内部数据管理
OpenBayes 数据的存储结构
.
├── <username>
├── codes
│ └── <sourcecode-id>
├── datasets
│ ├── <dataset-id>
│ │ ├── <dataset-version>
│ │ └── <dataset-version>
│ └── <dataset-id>
│ ├── <dataset-version>
│ └── <dataset-version>
└── jobs
├── <job-id>
│ ├── logs
│ └── output
└── <job-id>
├── logs
└── output
根目录是用户名,然后分三个目录:
/codes用户上传的代码/datasets用户上传的数据集/jobs用户所有任务的存储
其中 /datasets 下会每个数据集 id 为文件夹,并在其下依次保存每个版本的数据内容。/jobs 下每个 job 创建一个独立的文件夹,其下分别有 /output /logs 两个文件夹,分别保存了数据集的输出以及日志内容。存储在 S3 和 NFS 的数据都遵循这个目录结构。
举几个例子:
- 用户名为 test,id 为 abcde 的数据集第一个版本的目录为
test/datasets/abcde/1 - 用户名为 xushanchuan,id 为 zk812kadf 的 job 目录为
xushanchuan/jobs/zk812kadf,其 output 目录为xushanchuan/jobs/zk812kadf/output/,其 logs 目录为xushanchuan/jobs/zk812kadf/logs/
OpenBayes 与 NFS 的同步方式
- 当数据集上传时,数据会首先存放在临时目录进行解压,解压后被同步到 NFS
- 在 job 开始时,如果绑定的目录为
/input*那么相应的目录会从 NFS 以 只读 的模式绑定到容器中。 - 如果数据集被绑定到
/output(即用户输出)目录,则需要首先将数据拷贝到/output所绑定的volume - 当用户 job 执行时,会有后台进程周期性将工作目录下的数据(默认每 6 分钟,不同环境会有区别)同步到 NFS
- 当 job 执行结束时数据同样会同步到 NFS
如何绕过网页限制上传超大规模数据集
默认数据集上传的上限是 500G(生产环境),如果需要上传更大的数据集或者希望不通过压缩包上传文件可以通过模拟页面端数据集交互流程并直接向集群内 NFS 上传大数据集。首先我介绍一下我们后端上传数据版本的逻辑,然后再介绍怎么绕过上传流程。
目前数据集上传有两个流程:
每次上传压缩包到后端服务后,数据集会将当前需要更新的数据集版本或者新创建的数据集版本标记为 PROCESSING 状态。上传的 zip 解压后会有两种状态:成功或者是失败。
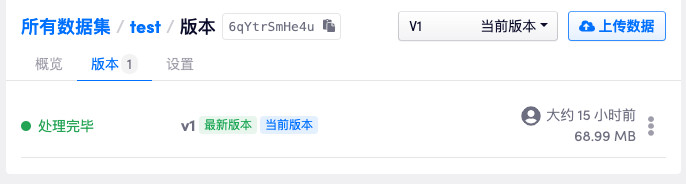
- 成功自然是指该压缩包没什么问题,可以正常使用了。这个时候后端存储服务会将该数据集版本标记为
VALID同时更新目录下的文件大小,我们在页面上也会见到新的版本以及对应的数据大小。
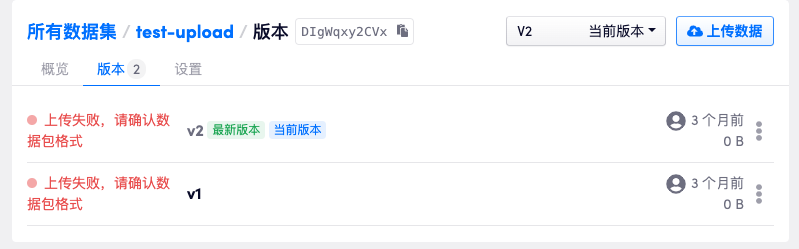
- 失败有多种原因,但大部分时候是压缩包解压失败,这个时候会将该次数据版本标记为
INVALID,我们在页面上会看到出现了一个失败的数据集版本。
针对上面的流程,如果希望直接向 NFS 拷贝数据绕过前端上传可以按照以下方法进行:
1. 确定想要上传的数据集 id 后先上传一个小文件作为占位符
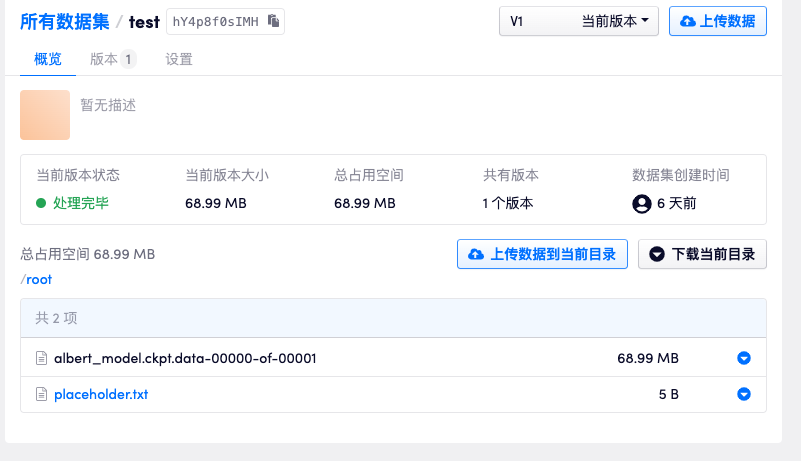
如上图所示,如果我希望将数据上传到 openbayess 账号下 id 为 hY4p8f0sIMH 的数据集下,首先我们可以先上传一个任意的小文件使其生成一个新的版本。
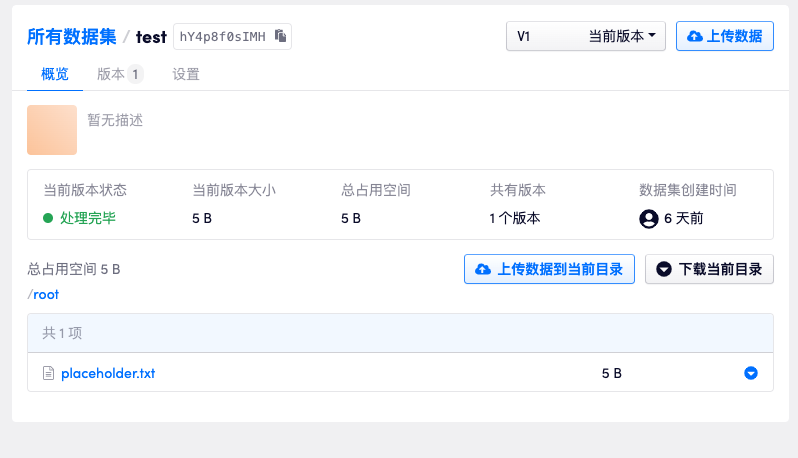
这里只上传一个名为 placeholder.txt 的文本文件,上传成功后数据集下生成一个新的版本。
2. 将大数据从后端直接上传到上述数据集版本的目录下
依据上文中「OpenBayes 数据的存储结构」部分可以知道新创建的数据集目录位置为 openbayes/datasets/hY4p8f0sIMH/1,我们可以将大规模的数据集直接拷贝到这个位置即可。拷贝后可以在页面上已经展示出了拷贝的文件,但是数据集的尺寸并没有更新。

由于不同环境的 NFS 技术方案各不相同,这里不再解释如何挂在一个 NFS 到内网目录上。
3. 再次上传小文件更新数据集版本尺寸
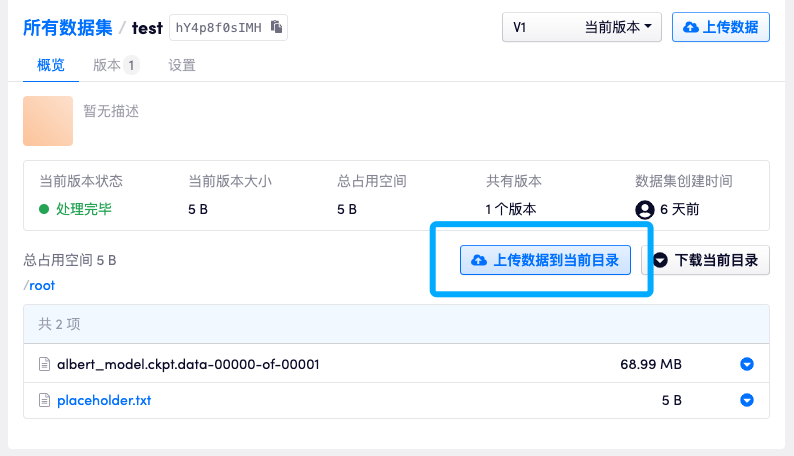
如图所示,再次通过「上传数据集到当前目录」的方式上传一个小文件会导致数据集版本的空间重新计算,上传成功后刷新页面就可以看到数据集大小已经正确了。