如何制作一个好的数据集
序
在开始面对一个深度学习问题或者一个需要解决的场景的时候,我们最常遇到的问题就是“没有数据”。没有数据、数据杂乱、数据没有标注、标注质量不高,都在解决这个问题之前,先挡在了我们的面前。针对这样的问题,本节内容,我们来为大家介绍一下如何制作一个好的数据集,希望能为各位同学提供帮助。
开始之前
我制作一个数据集之前,我们要做什么呢? 在开始制作一个数据集之前,我们首先要回答这样几个问题:
- 我们的场景解决中需要解决什么样的问题?
- 解决这样的问题需要什么样的数据?
- 有没有公开的数据集和我们的场景相似?
- 我们在一个单位之间内,能收集到多少数据?
- 标注一个单位的数据,需要花费多大的代价?
制作步骤
确定任务
在解决问题和制作数据集之前,我们要做的第一步就是确定我们的任务是什么。如果没有清楚明白的了解我们要解决的任务,我们后面的工作都会直接浪费。
在确定任务的时候,首先要明确我们的场景,是从什么样的输入,到什么样的输出。明确了输入输出,我们就能大概知道,我们面对的是一个什么问题。
明确面对的问题之后,将其拆解成一个或多个算法问题。假设已经拥有这些算法模型,看能不能按照流程解决问题,如果可以,就开始规划如何训练对应的算法,以及制作算法模型所需要的数据集。
设计数据分布
数据集中的场景是根据任务的目标设定的,针对任务中可能出现的识别目标和识别场景,一般会考虑中英文、黑白色彩、天气、内容分布。
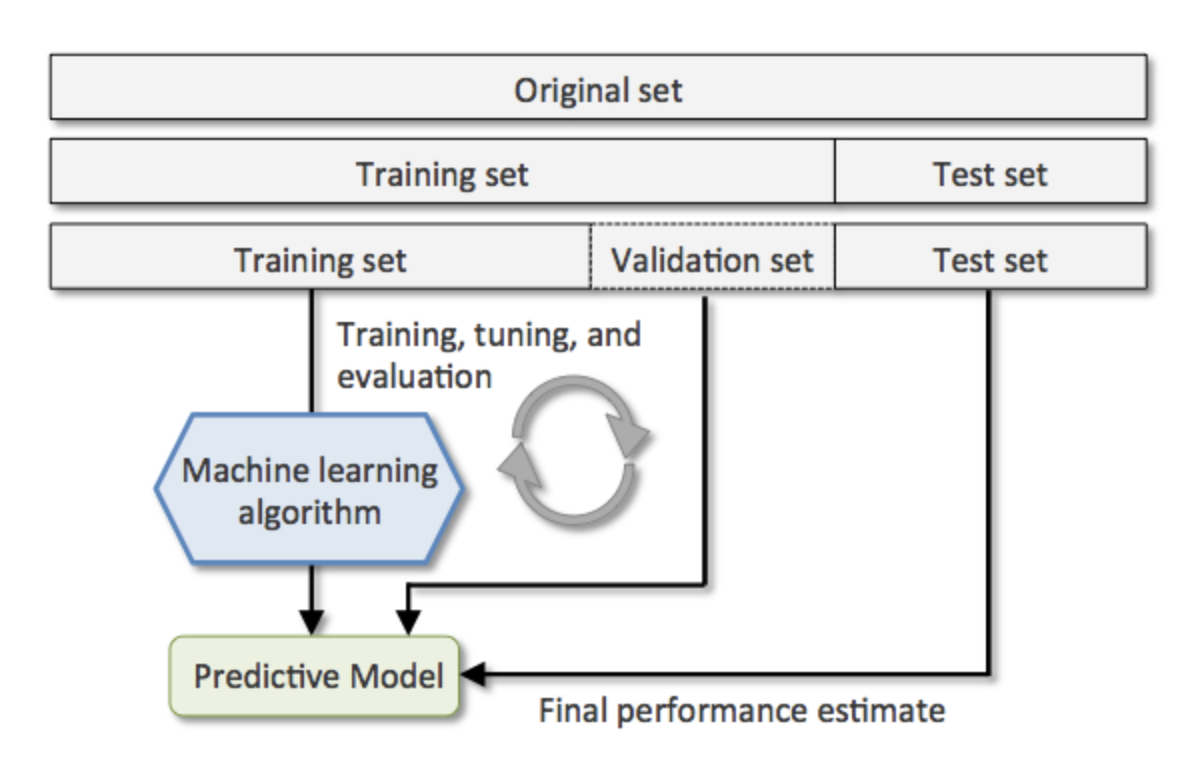
划分数据集
训练集是用来训练算法模型,通过输入输出学习神经网络等模型的参数权重。 验证集是用来在这些中间模型中挑选在验证数据中表现最好的模型。 测试集是用于评估使用训练数据集训练得到的算法的效果。 用生活的情况举个例子:
- 训练集相当于学生的课本:学生根据课本里的内容来掌握知识。
- 验证集相当于学生的作业:通过作业可以知道不同学生学习情况、进步的速度快慢。
- 测试集相当于最终的考试:考的题是平常都没有见过,考察学生举一反三的能力。
在得到原始数据集之后,我们需要对其进行划分,一份采样不能同时出现在训练集、验证集和测试集中。一般情况下,我们采取6:2:2的划分方式,每一部分中应尽可能全的包含各种数据场景。
标注数据
标注数据集的工具不是这篇文章的主要内容,下面只列举一些开源项目:
整理数据集格式
将标注好的数据集,按照文件夹整理,建议单文件夹不放置超过1000个文件。然后制作元信息文件 “meta.csv”。
meta.csv 是 OpenBayes 数据规范格式的元信息文件,具体格式讲解见:数据格式规范介绍
制作数据集会遇到的问题
1. 需要多少数据?
所有的项目都是独一无二的,我们理想的状况是数据是模型参数数量的10倍。任务越复杂,需要的数据就越多。
2. 我已经有数据集了,下面做什么?
不要着急开始。你需要先了解已有的数据集,并且一定能发现错误、无效、混乱的地方,先把它们修理好。数据集的质量决定了你后面做机器学习项目的每一步。
3. 如果我没有足够的数据怎么办?
如果有开源且场景相近的数据集,那么可以合并使用。如果场景特殊,就先梳理业务场景,做好打点,收集数据。