关键概念
这里介绍在 OpenBayes 中所提到的一些重要的概念。
算力容器
算力容器,在文档中也经常称为「容器」,可以简单理解为一个提供特定资源的小机器,创建容器时需要指定「算力」(CPU、内存、硬盘大小)、选择「镜像」(可以理解为预装的应用程序)、绑定「数据」。
每次容器的「执行」都会提供独立的存储空间并绑定到 /openbayes/home 目录,作为其工作目录。执行结束后,其中的内容也会被保存下来。
每个执行在创建时可以通过目录
/openbayes/input/input0/openbayes/input/input1/openbayes/input/input2/openbayes/input/input3/openbayes/input/input4
绑定其他数据。
更多有关数据绑定的信息请查看数据绑定。
算力容器的「执行」目前支持两种方式:
- Python 脚本
- Jupyter 工作空间
其中「Python 脚本」方式支持用户将自己的代码上传上来,然后指定所要执行的命令,容器在启动时会按照用户指定的入口命令执行 Python 脚本。适合一次性的、不需要频繁修改的 长任务 执行,例如一次长达 12 个小时的模型训练任务。
Jupyter 工作空间是一种交互式的代码执行工具,创建 Jupyter 工作空间后我们可以在其上做一些即时的命令执行和尝试性的工作。适合早期模型的调试和构建。
Jupyter 工作空间一旦处于运行状态即开始计费,直到用户主动关闭,即使用户没有在使用其中的计算资源,但由于算力资源独占的特性,也依然会正常计费。因此,一旦不再使用 Jupyter 工作空间,请及时将其关闭,避免造成不必要的计费。
同一个「容器」下的「执行」被认为在业务上存在着密切的关联,每次「算力容器」的「执行」都会被独立记录下来。
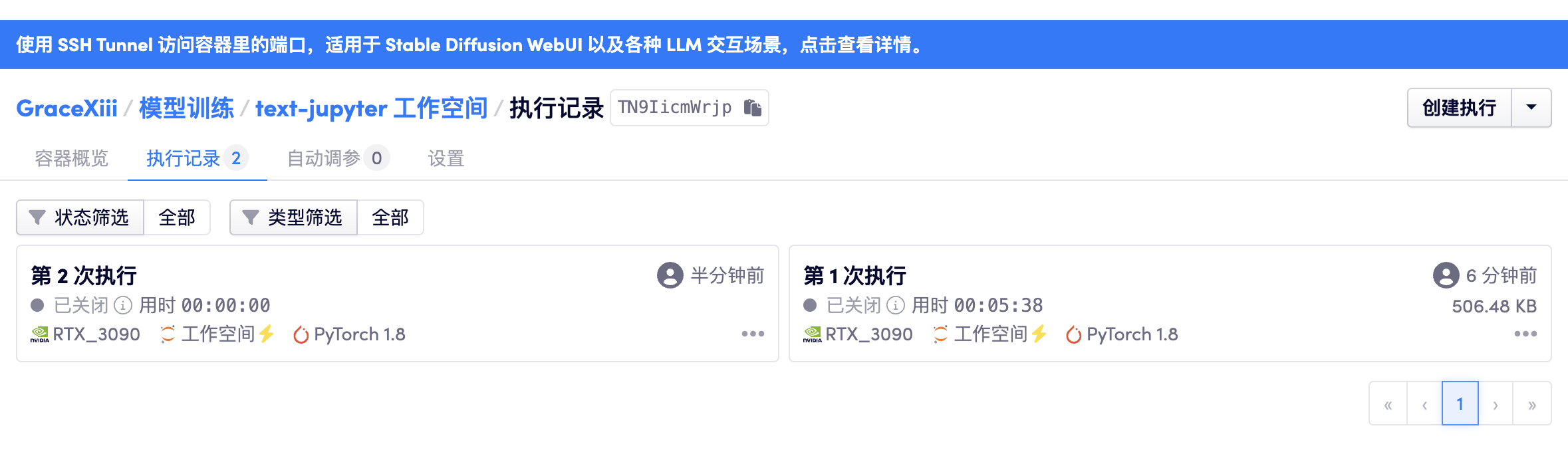
但是每次「执行」的环境都是隔离的,也就是说每次在「执行」中执行的安装命令当这次执行关闭之后就无法找回了。即使通过「继续执行」运行起来的「执行」的环境仍然是一次全新的环境。
数据仓库 Data Warehouse
用户可以创建数据仓库用于保存和复用数据。目前区分为两种类型:数据集与模型。通常来说数据集的规模都比较庞大,每次运行都重复上传代码和数据非常不现实。因此这里提供一个单独的区域用于数据集的管理。
绑定数据仓库
在创建 "算力容器" 时,通过 "绑定数据" 可以将数据仓库绑定到容器中进行使用,目前 "容器" 支持最多 5 个数据绑定。
如下图所示,在创建容器时可以选定数据仓库或下文所说的 "工作目录" 绑定到 /openbayes/input/input0 /openbayes/input/input1 /openbayes/input/input2 /openbayes/input/input3 /openbayes/input/input4 /openbayes/home 中任意一个目录中。在容器创建时,对应的数据仓库或执行的工作目录就会绑定到对应的目录中。
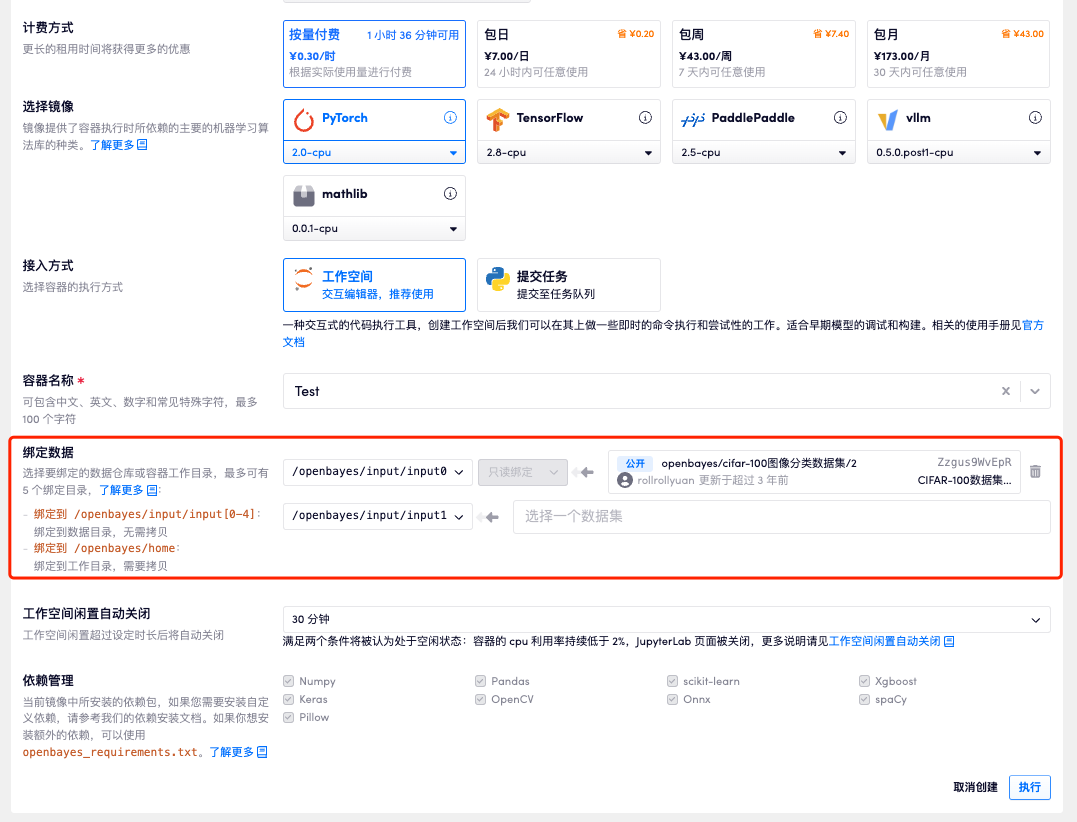
如上图所示,openbayes/cifar-100 图像分类数据集/2 数据仓库将被绑定到容器中的 /openbayes/input/input0 目录,在容器运行后就可以在 /openbayes/input/input0 访问到了。
用户的「存储空间」
用户上传的数据仓库、代码、容器关闭后保存的内容都会保存在用户的「存储空间」中,在用户的个人页面可以看到自己存储资源的用量。一旦超过用户存储总量用户将不再能创建容器、上传数据。
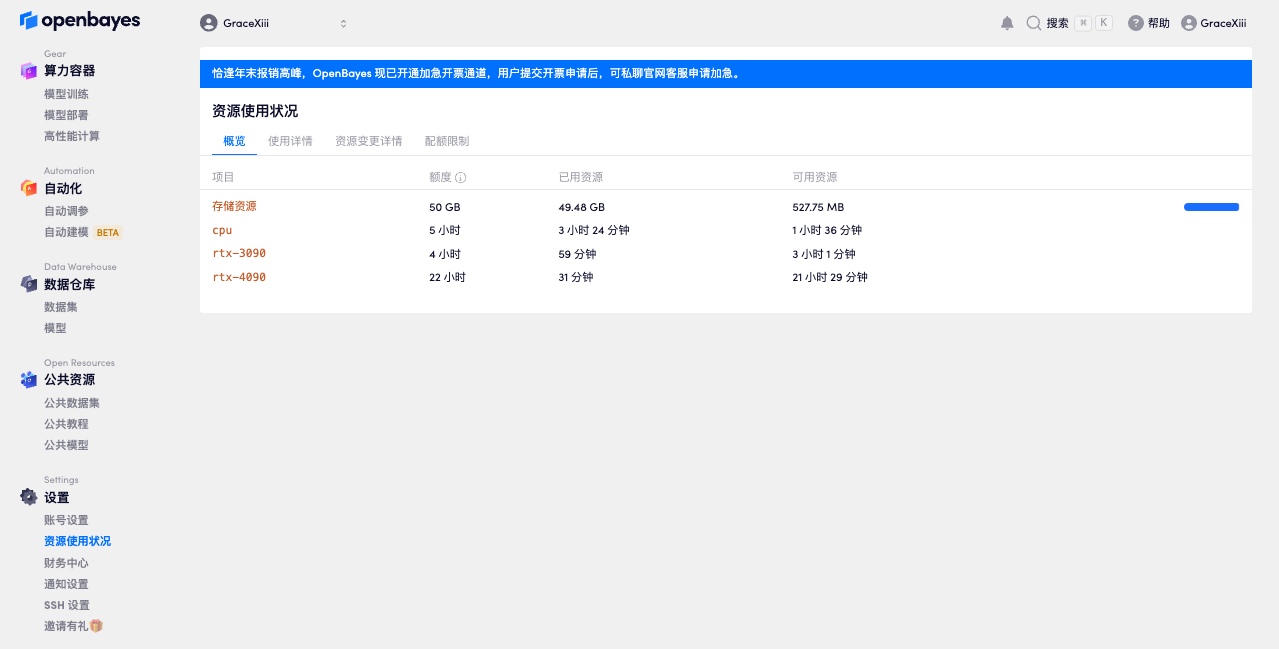
更多信息可以在资源以及用量获得。
容器的「工作目录」
「工作目录」是指每个「执行」中的 /openbayes/home 目录。这个目录下的数据在容器关闭后会自动的保存下来,其用量也会反映到用户的「存储空间」中。也就是说想要保存下来的内容都应该存储到这个目录中。
- 所有需要持久化的数据都必须存放在「工作目录」(
/openbayes/home)中 - 请勿将数据存放在系统盘(根目录
/下的其他位置),因为系统盘的数据在容器关闭后会丢失 - 「工作目录」的大小是根据选择的算力类型固定的,无法自行调整。请在创建容器时注意查看对应算力类型的存储空间限制
容器中默认绑定在 /openbayes/home 的「工作空间」与「存储空间」的关系如下:
- 容器的「工作空间」的容量是
/openbayes/home的存储容量上限,在使用该容器时,存放在该目录的文件总容量不能超过这个上限。 - 「工作目录」的数据会被持久化保存,即使容器关闭后也会保存下来,那么当然这部分数据也会占用「存储空间」的容量。
算力
算力定义了在 OpenBayes 的容器执行所提供的资源多少,目前 OpenBayes 主要提供两种类型的算力:
- CPU 算力,包含一定个数的 CPU,通过 CPU 执行机器学习算法
- GPU 算力,包含一个甚至多个 GPU,可以利用深度学习框架的 GPU 版本加速深度学习模型的训练和推理
每种算力都提供了内存的上限和存储上限,容器运行过程中一旦超过内存或存储的使用上限会导致任务的失败。
运行时环境
运行时环境也被称为镜像,提供了容器执行时所依赖的主要的机器学习算法库的种类。目前 OpenBayes 提供了 TensorFlow、PyTorch、MxNet、Darknet 的 CPU 和 GPU 环境下不同版本的标准库。后续将会提供更多其他种类的机器学习算法库。
更多内容请见运行时环境。
多端口映射
用户完成实名认证后,可以在「创建容器」-「端口映射」下,自定义内部服务与外部访问端口的对应关系,待容器状态显示「运行中」后会自动生成访问地址。22、5901、6006、6637、7088、8888 均为保留端口号,无法配置端口映射。
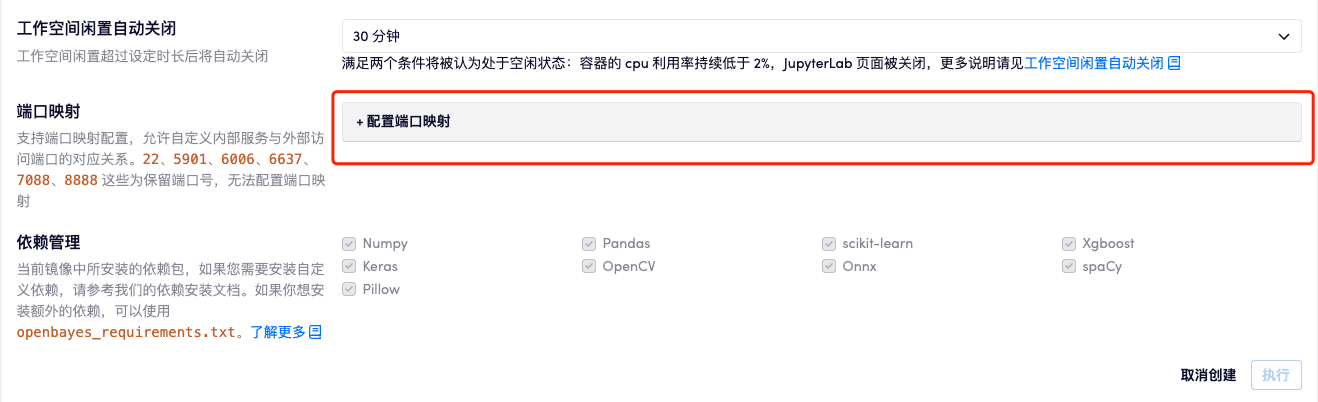
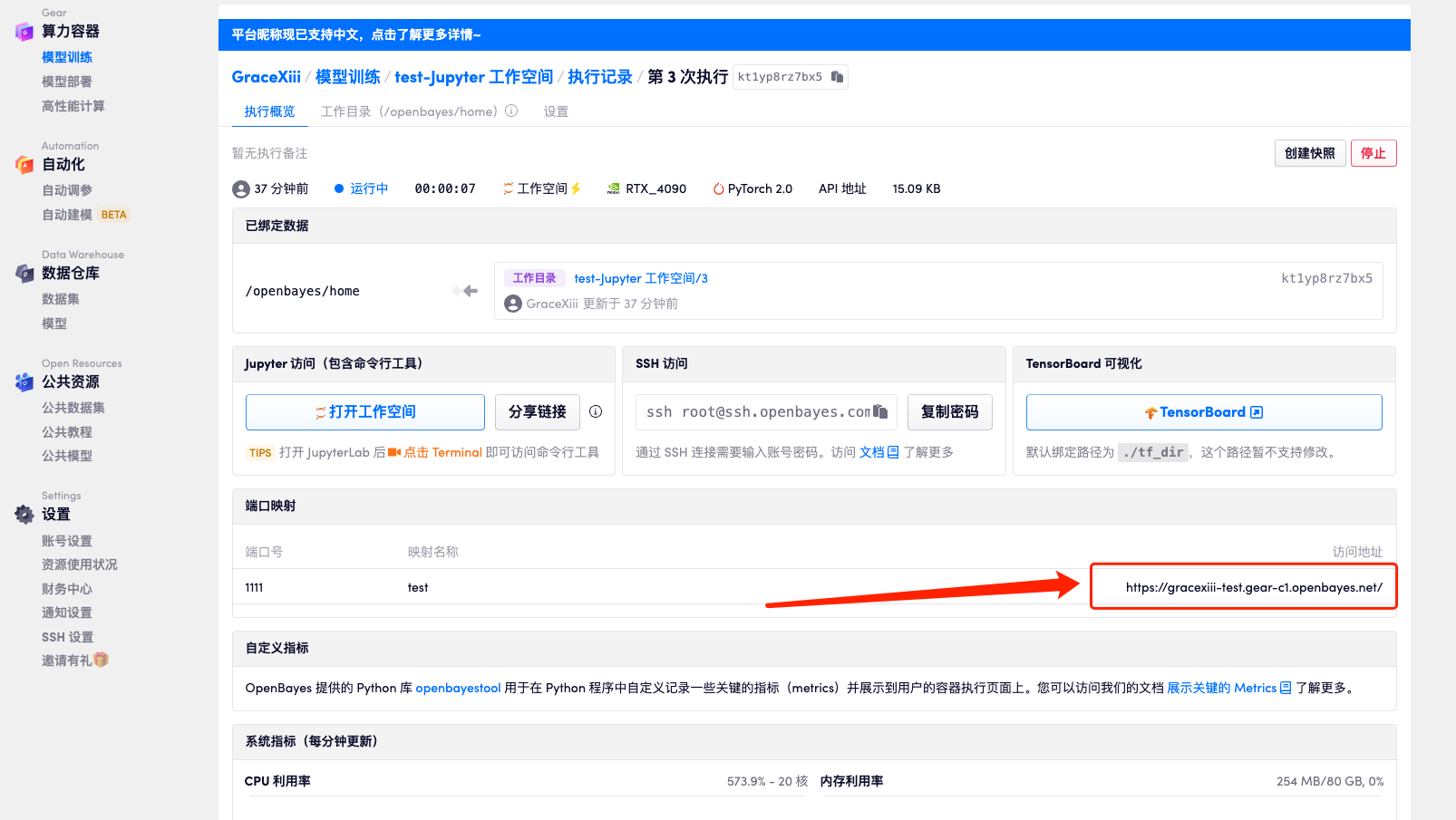
端口映射名称不能重复设置,否则会产生报错