OpenBayes 自动调参介绍
在构建机器学习模型的过程中需要很多的超参数,超参数的选择极大的影响了最终获取的模型的效果,自动调参是指通过系统自动获取最优超参数集合的方法。
自动调参目前支持通过界面和命令和进行创建,如需通过命令行创建,请先安装 bayes 命令行工具,并了解其基本的使用方法。
为了使用自动调参需要做以下的工作:
- 完成自动调参的配置,主要包含两个部分:
- 确定需要自动调节的超参数,依据自动调参的配置文档为系统指定哪些超参数需要调节以及调节的范围
- 确定所需要获取的关键指标,并在模型训练时通过 openbayestool 提交到 OpenBayes 系统中
- 修改已有的代码,支持对自动调参系统所生成的超参数的读取
快速尝试
openbayes-hypertuning-example 是一个样例代码库,目前仓库中分别包含 TensorFlow 和 PyTorch 版本的样例,请分别在 /tensorflow 和 /pytorch 目录查看。每个目录都包含了完成的 openbayes.yaml 以及相应的支持代码,按照其中的步骤可以运行一个自动调参的样例。
修改自身代码以支持自动调参
获取自动调参服务生成的参数
自动调参启动的任务可以通过两种方式获取其提供的参数:
-
读取
openbayes_params.json:如上的parameter_specs会生成四个参数,那么在容器的工作目录下会出现包含这些内容的openbayes_params.json:openbayes_params.json{
"regularization": 6.933098216541059,
"latent_factors": 29,
"unobs_weight": 3.439490399012204,
"feature_wt_factor": 102.9461653166788
}在代码执行之前通过读取该文件内的参数并使用即可
-
读取命令行参数:通过自动调参创建的任务其参数会以如下形式被添加到执行命令上:
python main.py \
--regularization=6.933 \
--latent_factors=29 \
--unobs_weight=3.439 \
--feature_wt_factor=102.9采用 argparse 可以解析并使用这些参数。
上报关键指标
在 系统指标与自定义指标 章节介绍了 openbayestool 工具有 log_metric 方法可以上报自定义的指标,自动调参同样采用这个工具实现指标的上报。在程序结束时通过以下代码即可实现上报:
import openbayestool
openbayestool.log_metric("precision", 0.809)
注意这里具体上报的指标名称应当和 openbayes.yaml 中配置的 hyperparameter_metric 一致。
创建自动调参
通过界面创建
登录控制台之后,可以从侧边栏的「自动调参」进行创建,或者从列表右上角的「创建自动调参」进行创建。
目前我们支持两种方式配置自动调参参数,可视化编辑器和 YAML 编辑器。在任意编辑器中进行编辑会同步进行更新。也就是说当用户在可视化编辑器中更新了参数后,切换到 YAML 编辑器后,配置会同步更新,反过来也相同。
通过命令行工具创建
通过命令行工具创建自动调参时,需要对 bayes 命令行工具有所了解,可以参考 bayes 命令行工具入门,同时还需要了解 openbayes 配置文件。
在准备好自动调参配置文件之后,通过命令 bayes gear run hypertuning 创建自动调参任务:
查看自动调参
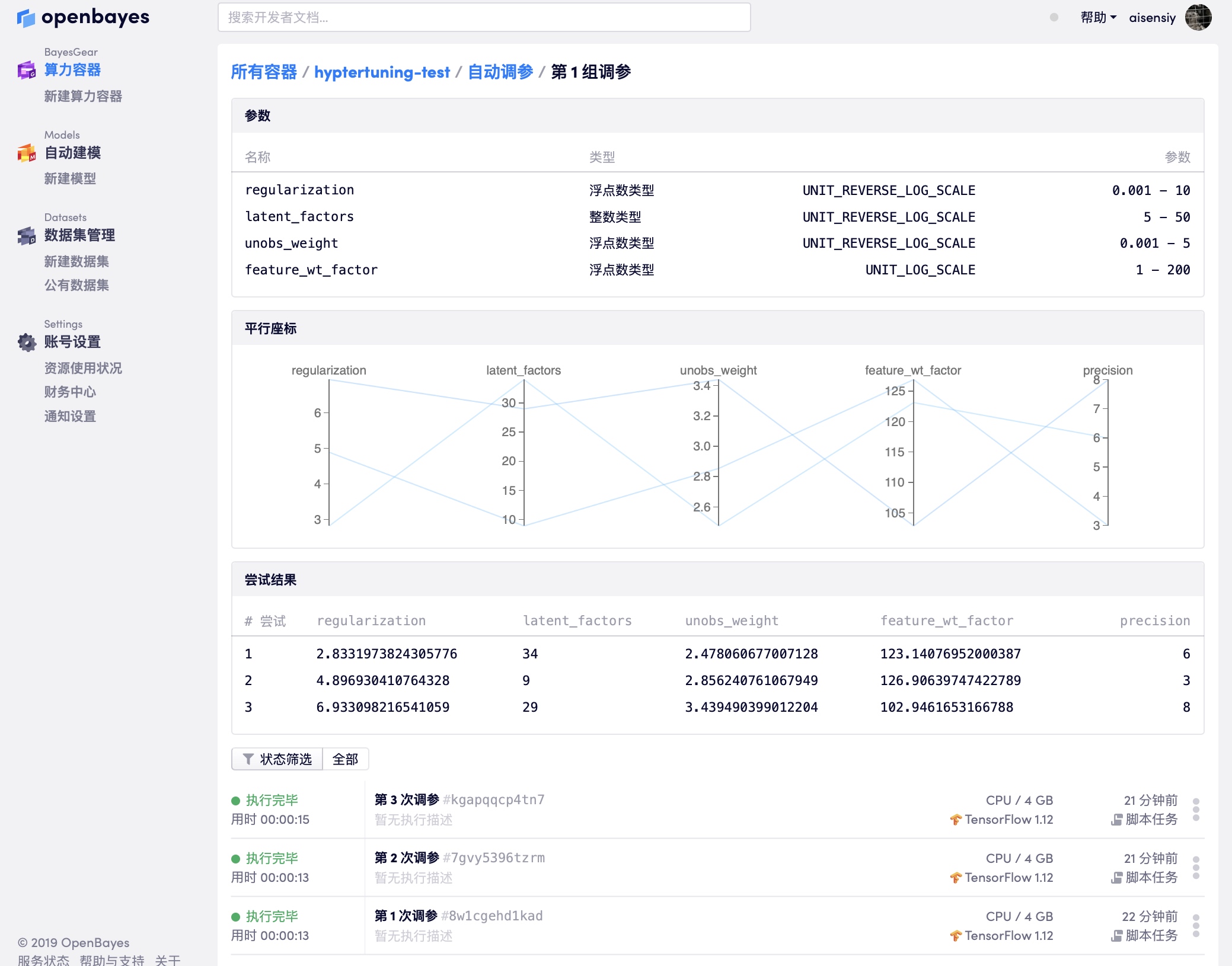
如上所示,自动调参页面会通过「图表」「平行坐标」等方式展示当前执行的状况,用户可以通过结果选择最好的一次执行作为结果或者依据目前的结果更新自动调参参数范围后继续新的自动调参任务。其中「平行坐标」是一个非常适合对自动调参结果进行筛选的视图,通过在界面上划定参数范围可以控制展示的参数组合。
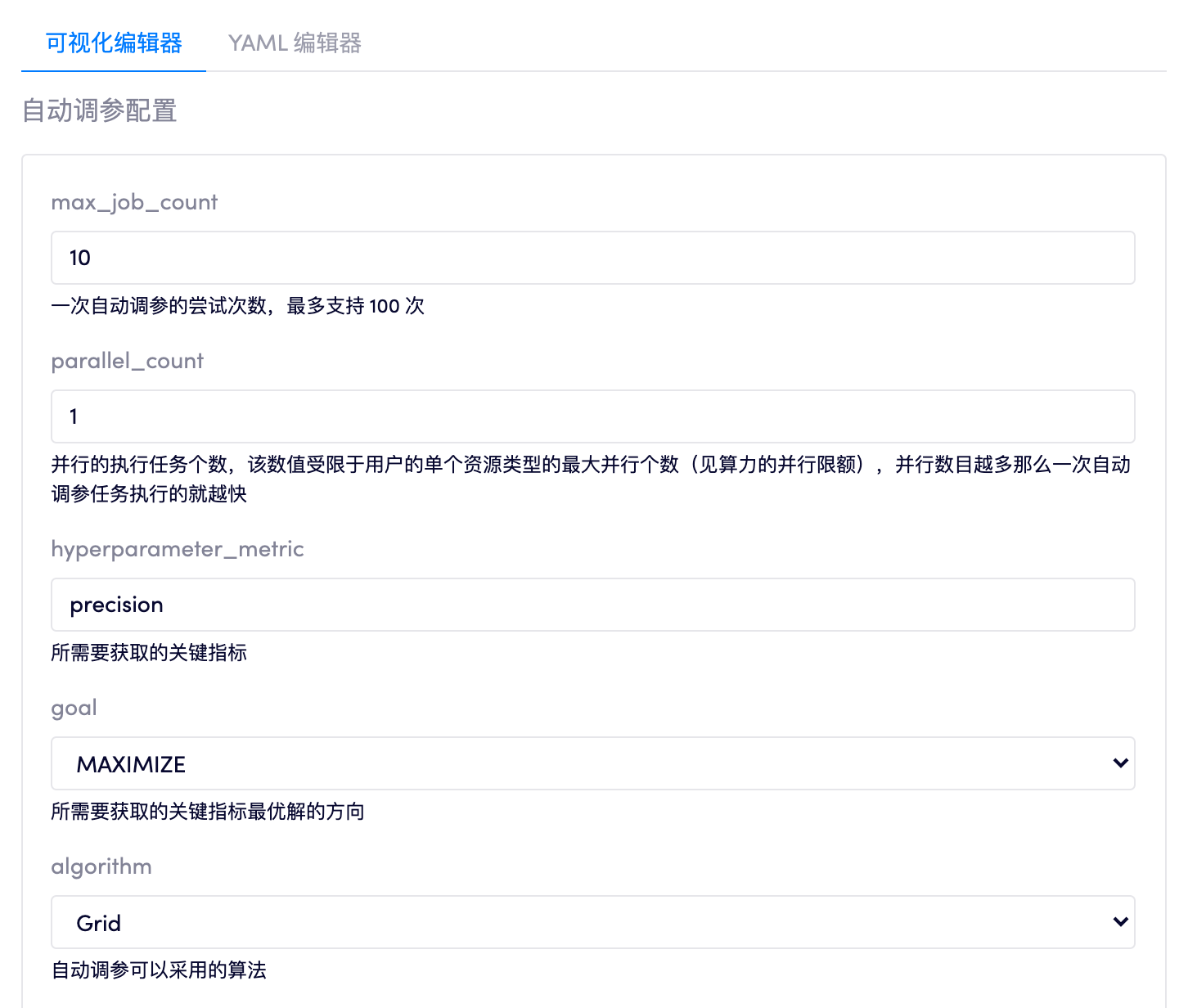
自动调参配置说明
在命令行中通过 bayes gear init <container-name>(相关文档)将当前目录和容器绑定,执行该指令后目录下会出现文件 openbayes.yaml。在 openbayes.yaml 下按照配置要求指定超参数及其范围。
一个 openbayes.yaml 文档分为两个部分:
- 基本配置,在 OpenBayes 配置文件 这部分有相应的介绍
- 自动调参配置,只在
hyper_tuning参数下有关自动调参部分的配置
在默认生成的 openbayes.yaml 下有如下的自动调参配置部分的样例:
hyper_tuning:
max_job_count: 3
hyperparameter_metric: precision
side_metrics: []
goal: MINIMIZE
algorithm: Bayesian
parameter_specs:
- name: regularization
type: DOUBLE
min_value: 0.001
max_value: 10.0
scale_type: UNIT_LOG_SCALE
- name: latent_factors
type: INTEGER
min_value: 5
max_value: 50
scale_type: UNIT_LINEAR_SCALE
- name: unobs_weight
type: DOUBLE
min_value: 0.001
max_value: 5.0
scale_type: UNIT_LOG_SCALE
- name: feature_wt_factor
type: DOUBLE
min_value: 1
max_value: 200
scale_type: UNIT_LOG_SCALE
- name: level
type: DISCRETE
discrete_values: [1, 2, 3, 4]
- name: category
type: CATEGORICAL
categorical_values: ["A", "B", "C"]
hyper_tuning 下的参数就是自动调参所需要配置的内容:
1. max_job_count
一次自动调参的尝试次数,最多支持 100 次。
2. parallel_count
并行的执行任务个数,该数值受限于用户的单个资源类型的最大并行个数(见配额限制),并行数目越多那么一次自动调参任务执行的就越快。
3. hyperparameter_metric
就是所需要获取的关键指标,在下文 上报关键指标 部分会用得到。
4. goal
所需要获取的关键指标最优解的方向(MAXIMIZE 或 MINIMIZE)。
5. parameter_specs
超参数的规约,即可以设置的超参数类型以及其范围,其中超参数的类型可以是以下四种:
| 类型 | 数值范围 | 数据类型 | 描述 |
|---|---|---|---|
| DOUBLE | min_value - max_value | 浮点型 | |
| INTEGER | min_value - max_value | 整数 | |
| CATEGORICAL | 枚举类型 | 字符串 | |
| DISCRETE | 离散类型 | 有顺序的数值 |
其中 INTEGER 和 DOUBLE 类型还可以设定获取参数的分布类型(scale_type):
| 分布类型 | 描述 |
|---|---|
| UNIT_LINEAR_SCALE | 线性分布,指数据在 min_value 和 max_value 是遵循均匀分布抽样 |
| UNIT_LOG_SCALE | LOG 分布,指 log(value) 在 min_value 和 max_value 之间遵循均匀分布,也就是在抽样时,数值越小其抽样的密度越大,在使用 UNIT_LOG_SCALE 时 min_value 必须大于 0 |
6. algorithm
自动调参可以采用的算法,支持 Bayesian Random 或 Grid:
| 算法 | 描述 |
|---|---|
| Grid | 对于只有 DISCRETE 以及 CATEGORICAL 类型参数的场景可以通过 GridSearch 遍历所有参数的组合 |
| Random | 针对 INTEGER 以及 DOUBLE 类型,依据其所支持的分布类型,在 min_value 和 max_value 之间随机选择数值,对于 DISCRETE 和 CATEGORICAL 类型,其行为和 Grid 方式类似 |
| Bayesian | 每次生成参数时考虑之前的「参数」-「目标变量」的结果,通过更新后的分布函数提供参数以期望获取更好的结果,其算法可以参考 该文章 |
7. parameters
该参数并不是出现在 hyper_tuning 配置下面,而是在根层级下出现的,在 config 配置 部分做了介绍。在创建「自动调参任务」时提供该字段依然会产生作用。不过这里所提供的参数配置的优先级会低于自动调参过程中产生的配置,也就是说如果这部分配置中有和 parameter_specs 下的参数重名,那么该参数会被 parameter_specs 下的参数所覆盖。
举一个例子,我们配置了一个如下的 openbayes.yaml:
...省略其他部分...
parameters:
filter_size: 5
hyper_tuning:
parameter_specs:
- name: filter_size
type: DISCRETE
discrete_values: [1, 2, 3, 4]
...省略其他部分...
那么每次自动调参所生成的参数组合中一定会有 filter_size 这个字段,那么其生成的值会覆盖掉 parameters 下的 filter_size 字段的值。
8. side_metrics
在上文提到 hyperparameter_metric 是用于自动调参的关键指标,除此之外可以设置多个 side_metrics 作为最终指标的辅助指标,例如相对于 accuracy f1_score 指标或者在训练过程中的 loss 可以添加为 side_metrics 最为参考指标。该指标对自动调参过程没有任何的影响,只是会在指标的可视化中被展示出来,作为自动调参结果好坏的参考。

如上图所示,作为 side_metrics 的参考指标 loss 也会被展示出来。不过要注意,在代码过程中也要使用 openbayestool.log_metric 方法将指标记录下来,否则在可视化中无法展示出来。可以参考 openbayes hypertuning in pytorch 中对 loss 指标的处理。
自动调参的状态解释
自动调参任务在执行过程中会出现以下几种状态,这里分别对不同的状态做一些解释:
运行中:自动调参下的执行运行正常已取消:自动调参任务由于用户主动中止而关闭了没有相应指标:指在自动调参下的执行中没有提供指标上报的代码,自动调参系统发现了这个问题后中止了自动调参过程执行出错:指自动调参下的执行出错了或者由于某些原因被中止了(可能是单个执行被关闭了,比如由于欠费等原因被系统关闭)系统错误:指自动调参系统自身出现了某些问题导致自动调参被中止了,这种情况下可以联系系统管理员进行问题的上报搜索空间用尽:有两种情况会出现这个结果,一个是自动调参系统认为用户提供的超参数范围下所生产的参数组合已经用光了接下来产生的参数是重复的了;另一个是系统认为目前已经没有办法产生更好的结果了,主动中止了搜索