从零开始的超分辨率服务(Predictor 方式)
传统的 predictor.py 部署方式不再是最佳实践,建议使用自定义部署方式。请参考快速上手文档了解推荐的部署方法。
在依赖管理部分介绍的依赖安装会在「模型部署」启动时执行,为了加速服务的启动可以通过使用自定义镜像,在自定义镜像中预装所有的依赖。
MMEditing 是一个基于 PyTorch 实现的开源的图像和视频的编辑库,属于 OpenMMLab 项目的一部分。 MMEditing 可以做图像补全、抠图、超分辨率、生成工作。这篇教程以超分辨率作为例子来搭建一个 Serving 服务。
在开发环境走通流程
首先,新建一个「模型训练」算力容器,选择 PyTorch 镜像,取名叫做 MMEditing。
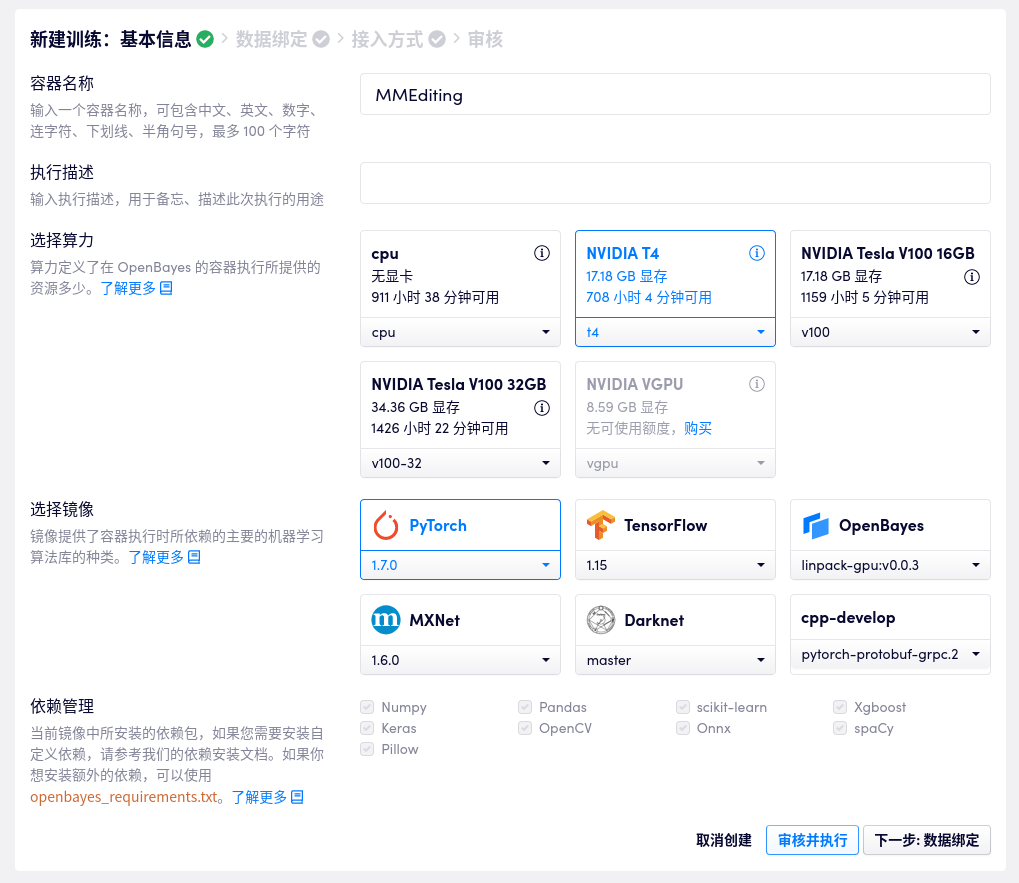
等到 Jupyter 工作空间启动完毕后,打开一个 Terminal,将 MMEditing 的仓库 clone 下来,在 MMEditing 的 README 中找到文档的链接并且按照文档进行安装。
容器中已经提供了 CUDA、PyTorch 和 torchvision 组件,所以从 c 步骤开始就可以了。
执行 pip install --user -r requirements.txt 。其中一个包需要编译所以时间会有点长。
最后执行 pip install --user -v . 安装好 mmediting 库本身。这里不要加 -e 参数(开发模式)而是正常安装,因为模型上线后也需要它。
然后我们在文档的 Model Zoo/Restration Models 找到了预训练的 EDSR 模型,把配置和模型文件下载下来并上传到算力容器的 home 目录下(可以用 Jupyter 工作空间的上传按钮,也可以直接拖动到文件列表上)。

上传完成后,在 home 目录新开启一个 Notebook,执行
import mmedit
如果没有错误,就说明我们的环境已经搭建好了。
接下来,上传一个低分辨率的图片,用作测试。这里我们叫做 low-resolution.png。
在 mmediting 的仓库内的 demo/restoration_demo.py 可以找到超分辨率的样例代码
我们改写下放到 Notebook 中实验。
import mmedit, mmcv, torch
from mmedit.apis import init_model, restoration_inference
from mmedit.core import tensor2img
model = init_model(
"edsr_x2c64b16_g1_300k_div2k.py",
"edsr_x2c64b16_1x16_300k_div2k_20200604-19fe95ea.pth",
device=torch.device('cuda', 0)
)
output = restoration_inference(model, "low-resolution.png")
output = tensor2img(output)
mmcv.imwrite(output, "high-resolution.png")
import PIL
low = PIL.Image.open('low-resolution.png')
high = PIL.Image.open('high-resolution.png')
display(low, high)
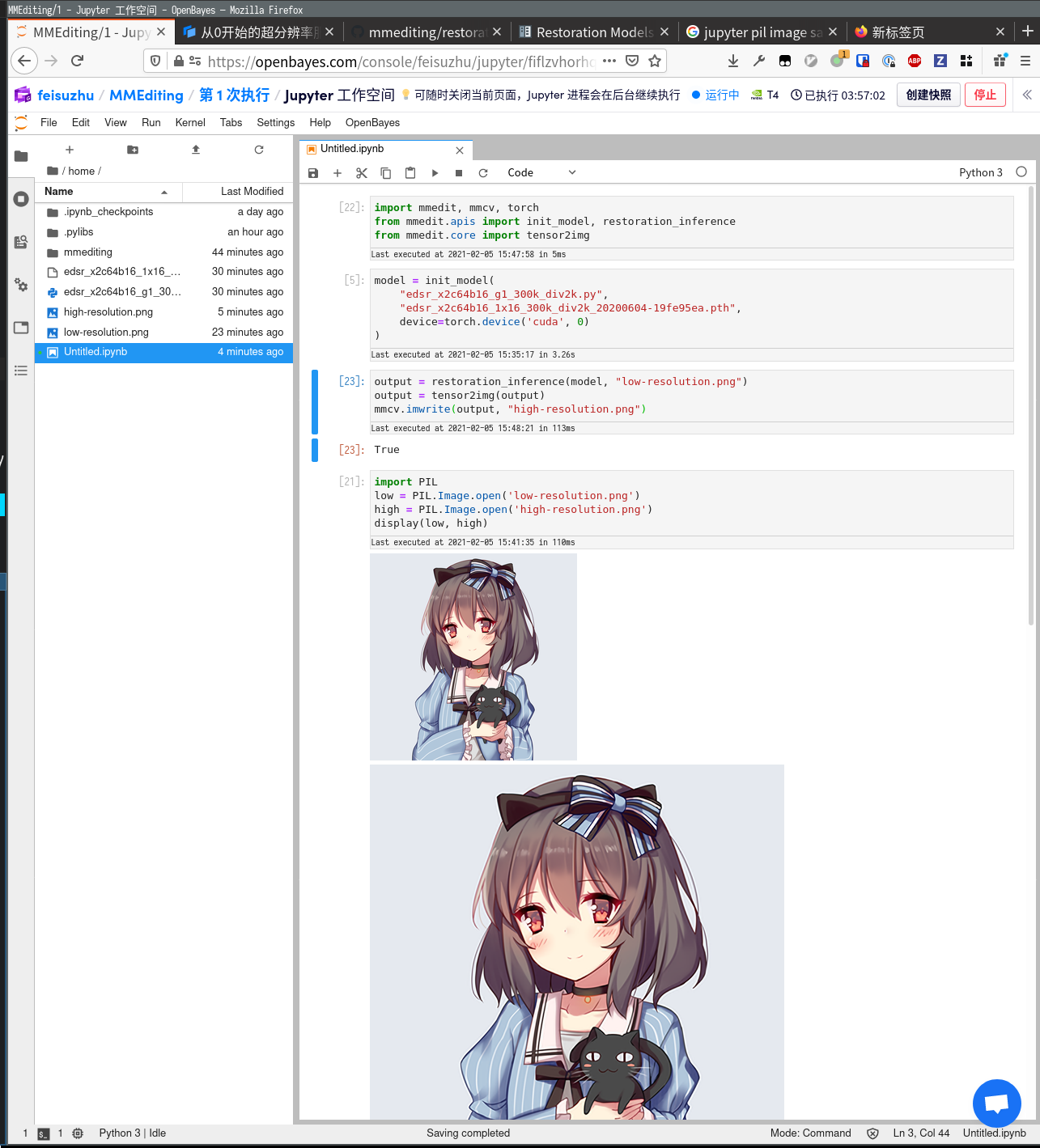
至此成功将一张图片做了超分辨率处理。
编写 Serving 服务使用的 predictor.py
在Serving 服务编写中有介绍 predictor.py 的具体编写方法,此处不再过多进行解释。
import openbayes_serving as serv
import mmedit, mmcv, torch
import cv2
from mmedit.apis import init_model, restoration_inference
from mmedit.core import tensor2img
import tempfile
class Predictor:
def __init__(self):
self.model = init_model(
"edsr_x2c64b16_g1_300k_div2k.py",
"edsr_x2c64b16_1x16_300k_div2k_20200604-19fe95ea.pth",
device=torch.device('cuda', 0)
)
def predict(self, data):
# 我们这里约定输入的数据是直接 POST 上来的图片
f = tempfile.NamedTemporaryFile()
f.write(data)
f.seek(0)
output = restoration_inference(self.model, f.name)
_, img = cv2.imencode('.png', output)
return img
if __name__ == '__main__':
serv.run(Predictor)
可以看到基本就是我们之前在 Notebook 中写的代码,填到了固定的框架中。将文件保存为 predictor.py,开启新的 Terminal 运行它。
然后在 Notebook 中测试它, POST 到本地访问地址即可
import requests
with open('low-resolution.png', 'rb') as f:
img = f.read()
resp = requests.post('http://0.0.0.0:8080', data=img)
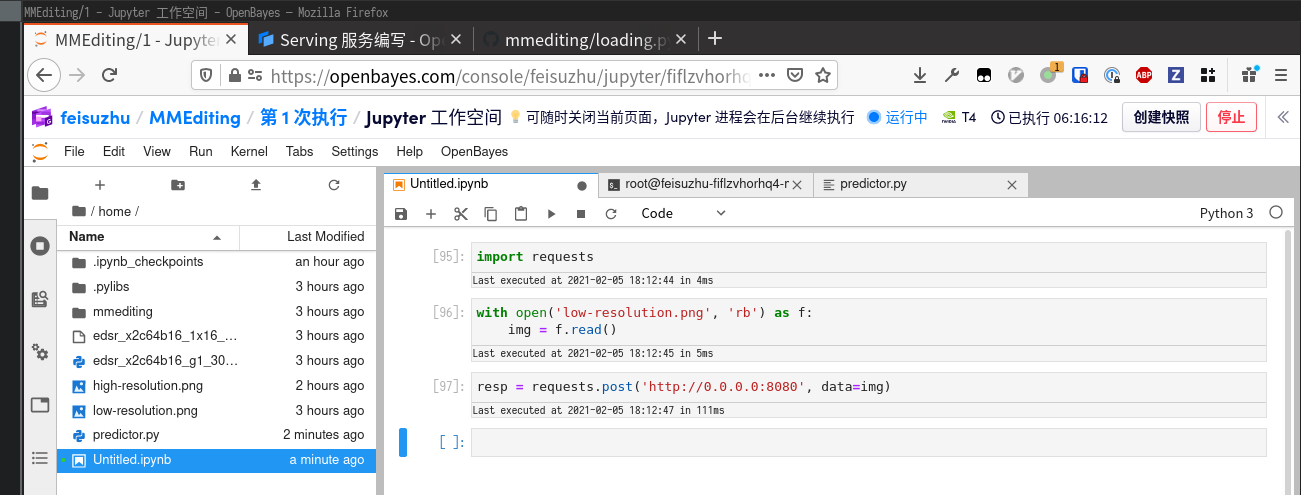
但是重新回到 predictor.py 的 Terminal 窗口,发现报了一个很奇怪的错误。
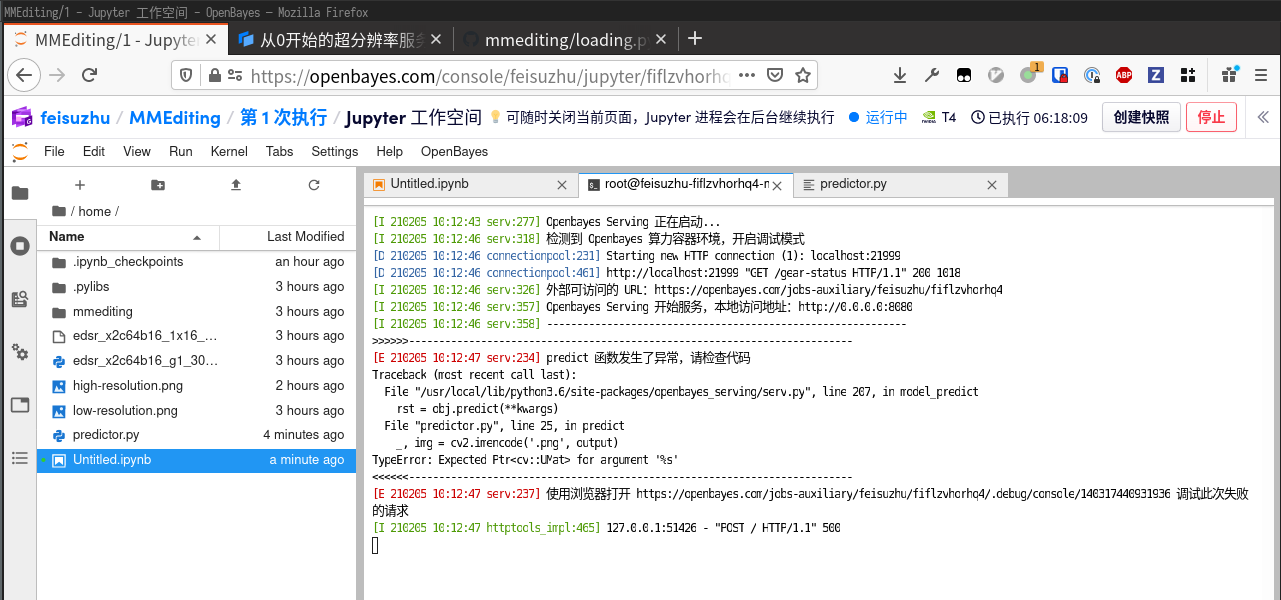
cv2.imencode 会失败,很可能是因为 output 参数不太正常。我们按照提示打开调试链接,观察一下 output 变量的状态。
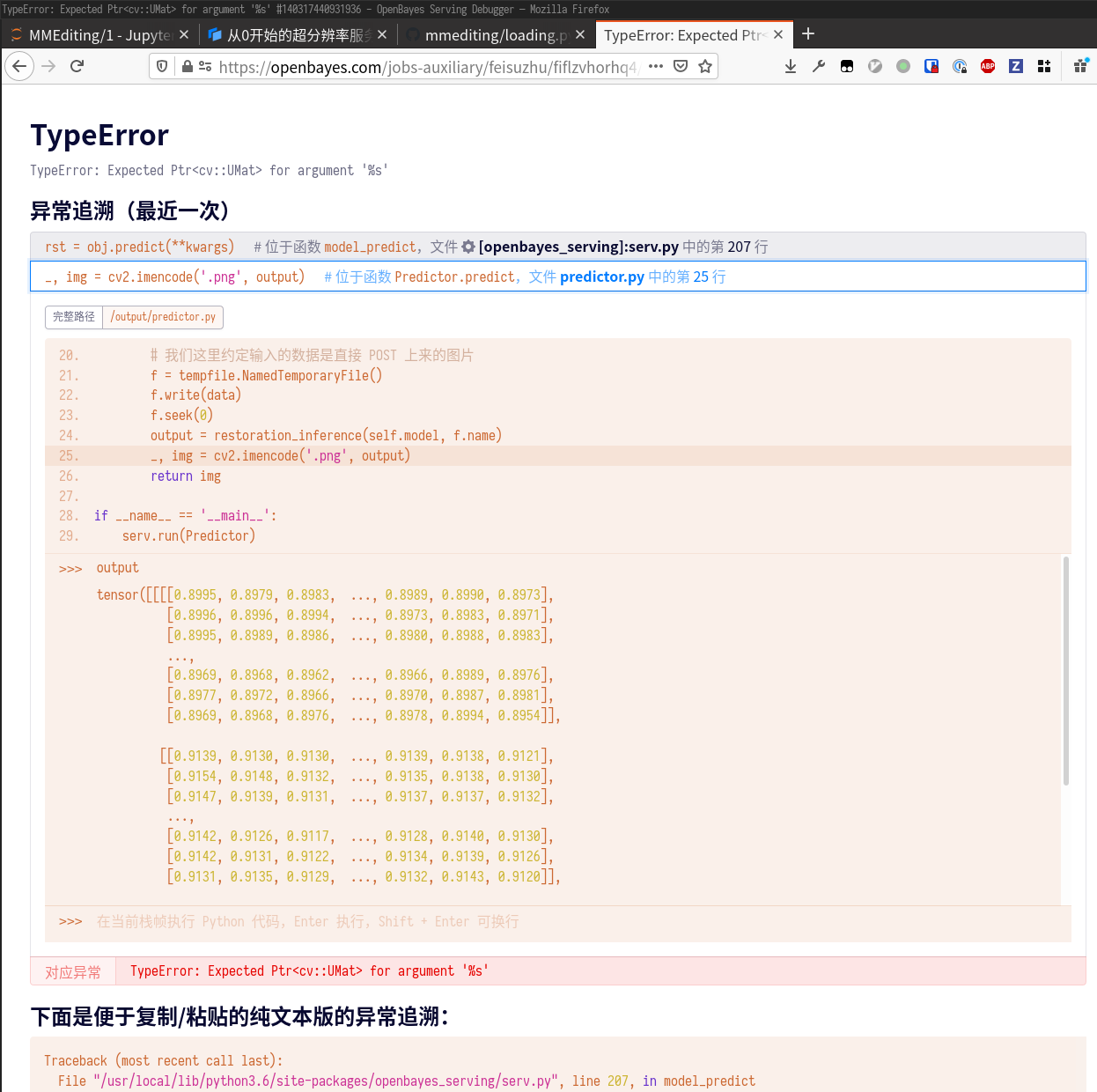
发现 output 是一个 PyTorch Tensor,但是 OpenCV 并不认识 Tensor,只知道 numpy array。
重新检查代码,发现漏掉了一句 output = tensor2img(output)(参考之前的代码)。我们先在调试窗口实验一下。
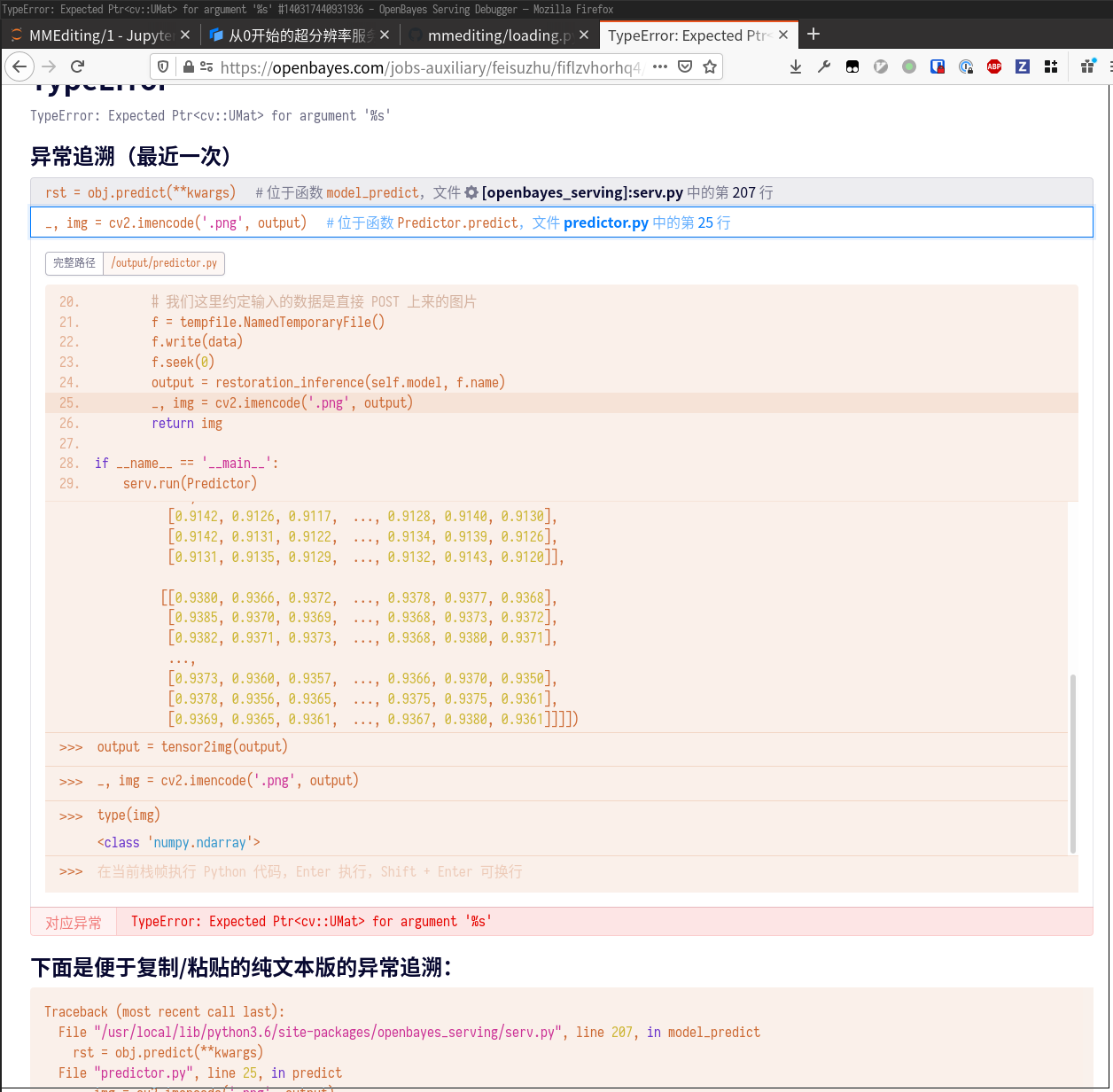
发现已经可以成功运行了,那么我们把这一句补上后,重新运行 python predictor.py,再次测试。
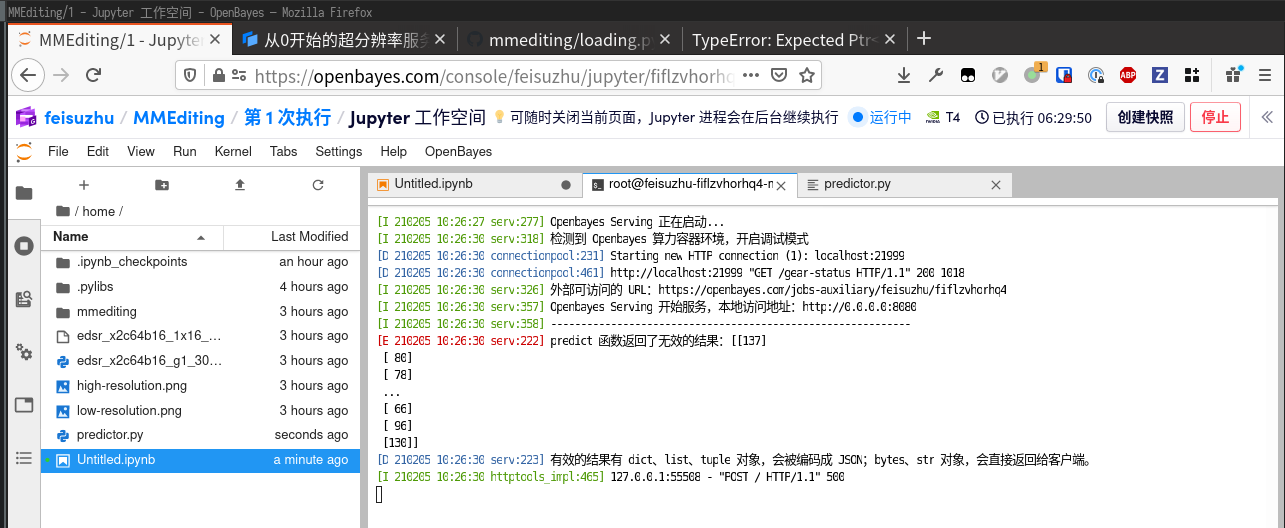
仍然报错,但是这次是一个非常显然的错误,我们需要把结果的 numpy array 对象转换成 bytes。
最后的 return img 改成 return img.tobytes() 就可以了。再次测试,成功返回结果。
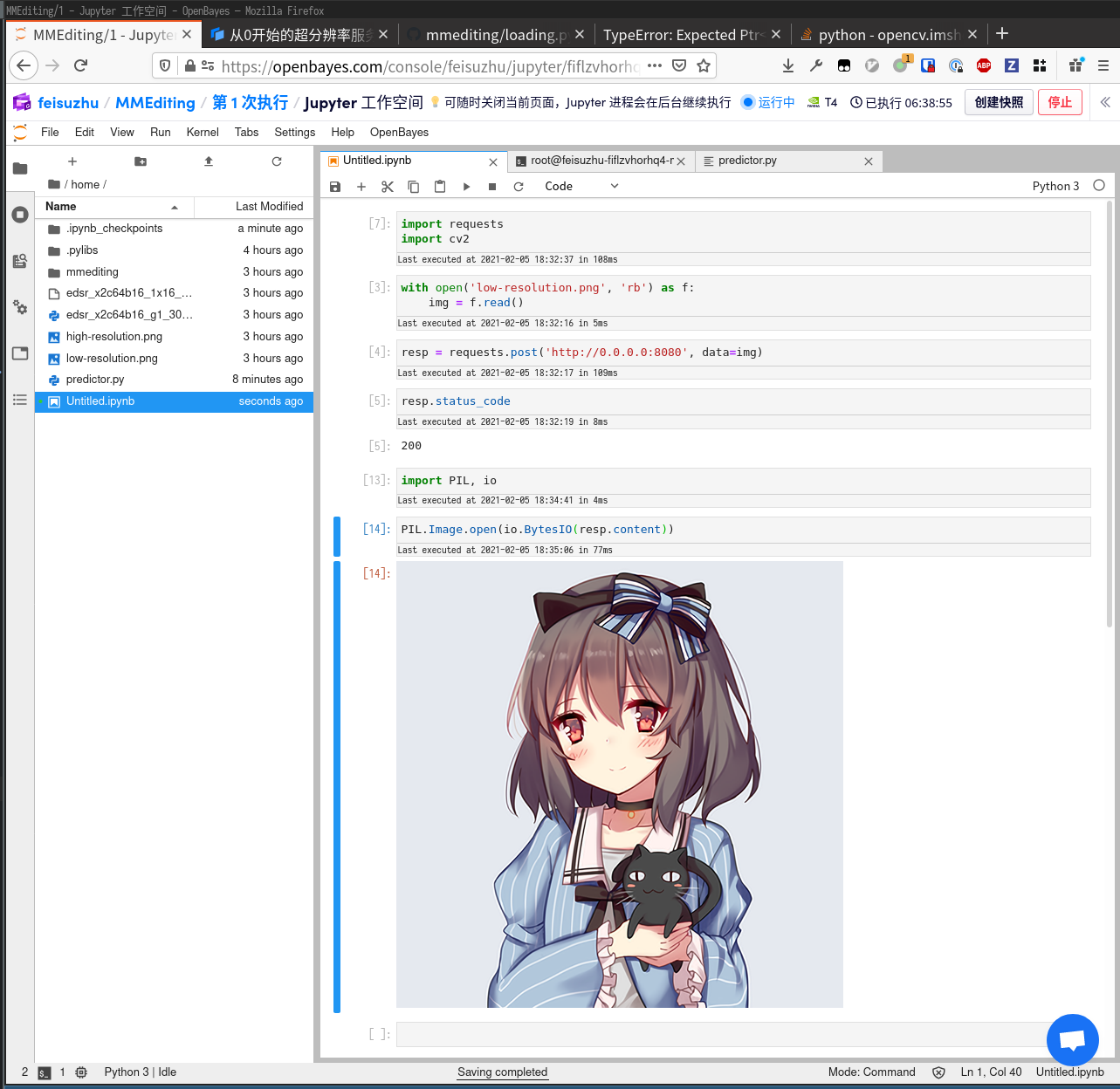
最后,上线!
开发已经完成了,可以清理一下用不到的东西。最后的结果是这个样子:
停止算力容器,等待完成同步后,在左侧边栏「数据仓库」处找到「模型」,点击「创建新模型」。
然后回到被关闭的算力容器处,点击「复制当前目录到数据仓库」。

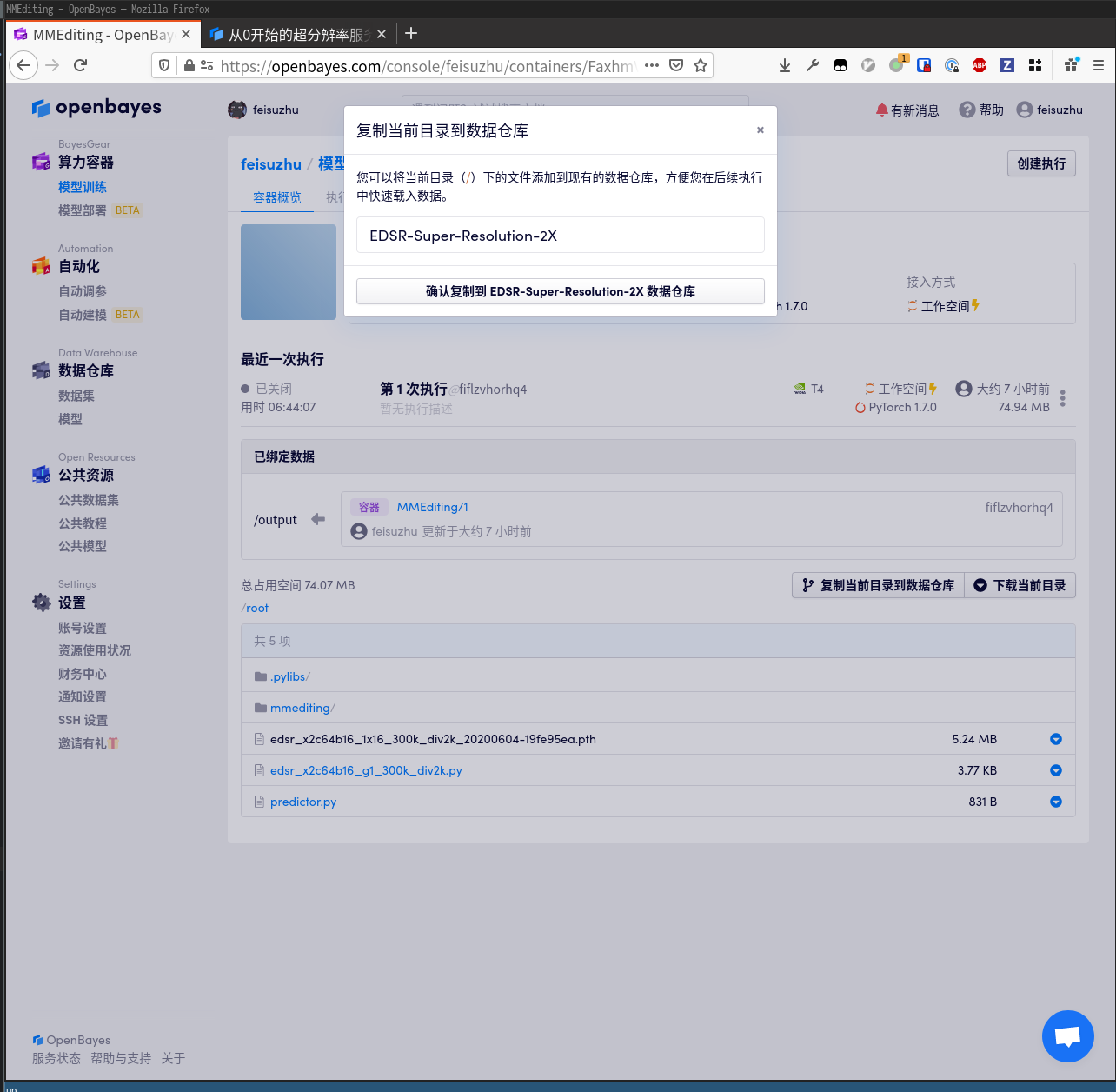
处理完毕后的模型应该是这个样子:
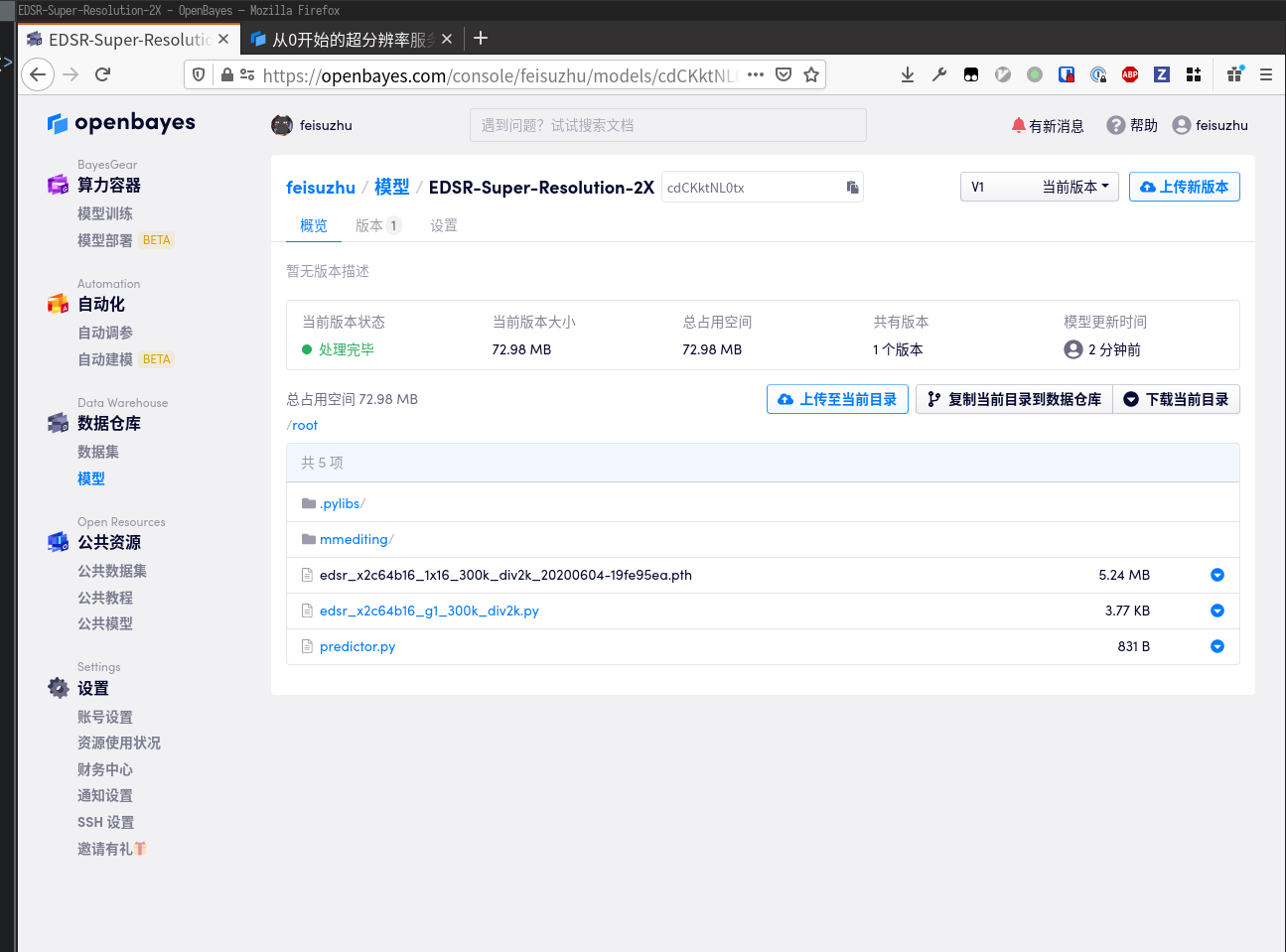
然后找到「算力容器」下的「模型部署」,点击「创建新部署」,选择与开发时相同的镜像,并选择一个 GPU 算力。

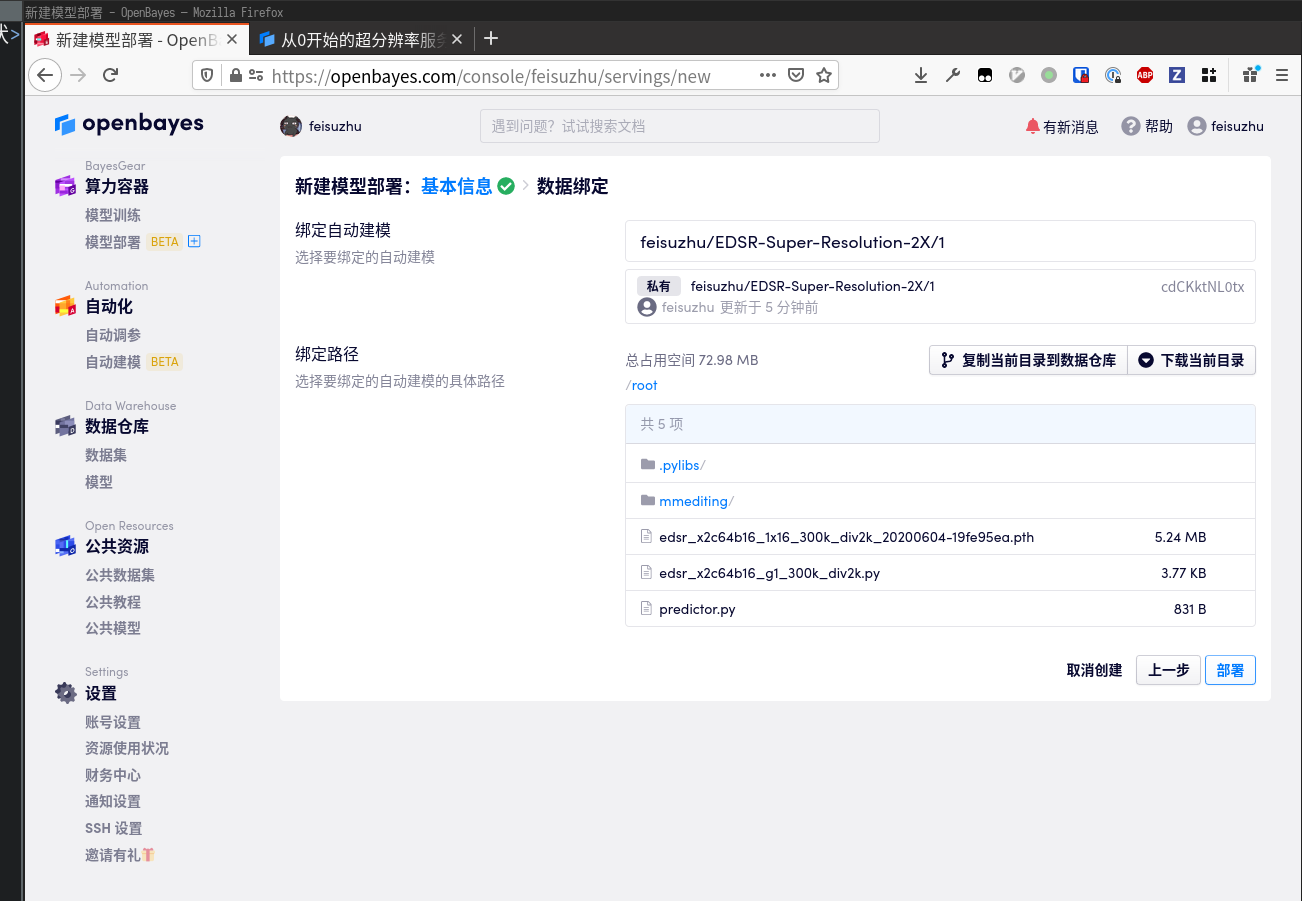
绑定刚刚准备好的模型,点击「部署」
等待模型启动,观察到下图样子就说明成功了
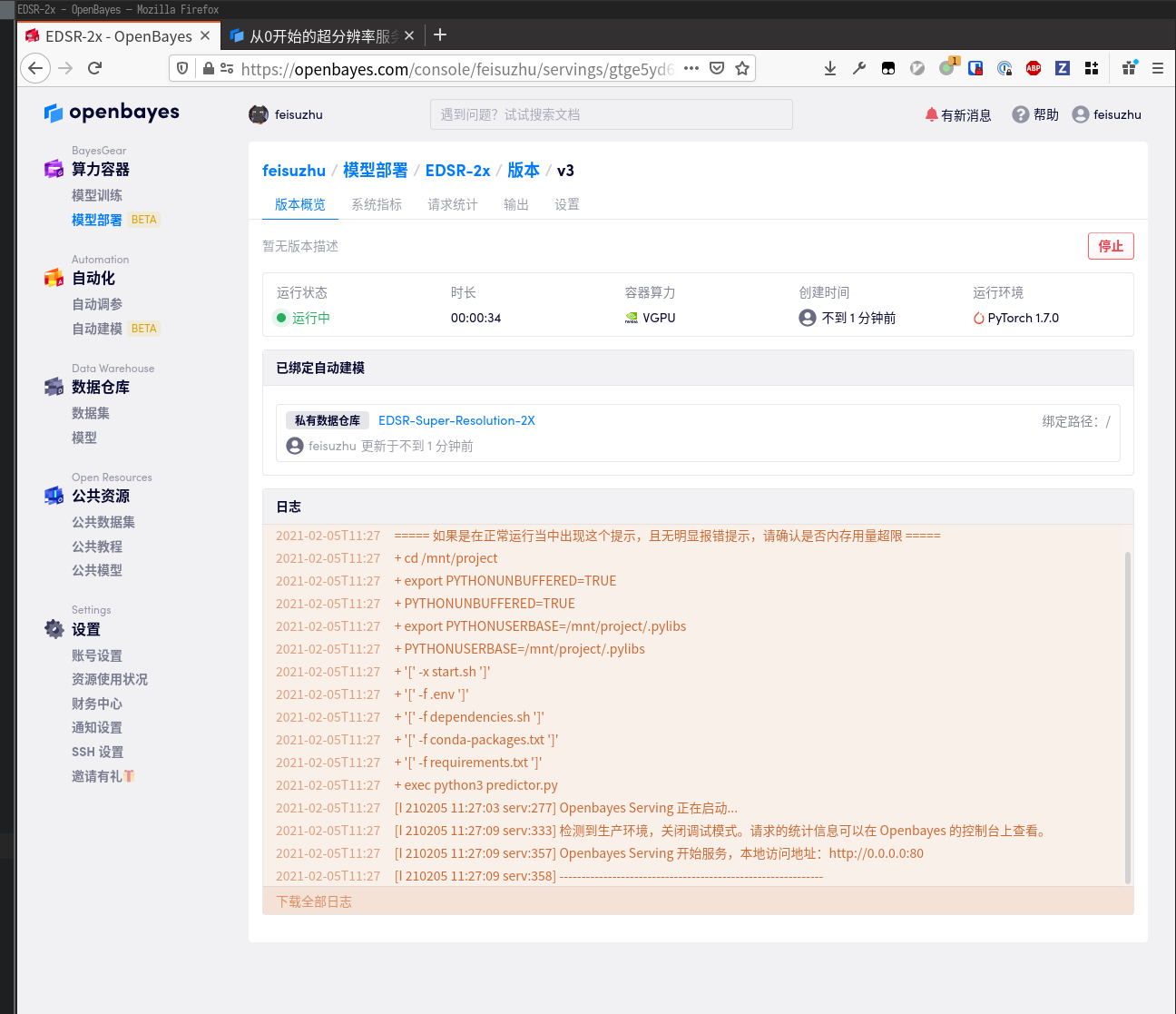
然后在模型部署「概览」处取得 API 地址,

在一个其他的地方试一下

至此已经成功将超分辨率服务上线。
另外再简单地测试一下性能
注意这并不是一个用来展示性能的 case,教程为了减少认知负担使用了最浅显的方式实现,服务的性能并不是最优的。这个章节主要用来展示「请求统计」的用法。
我们将最后的 requests.post 包裹在 while True: 中,不停地请求服务,然后在「请求统计」中观察:
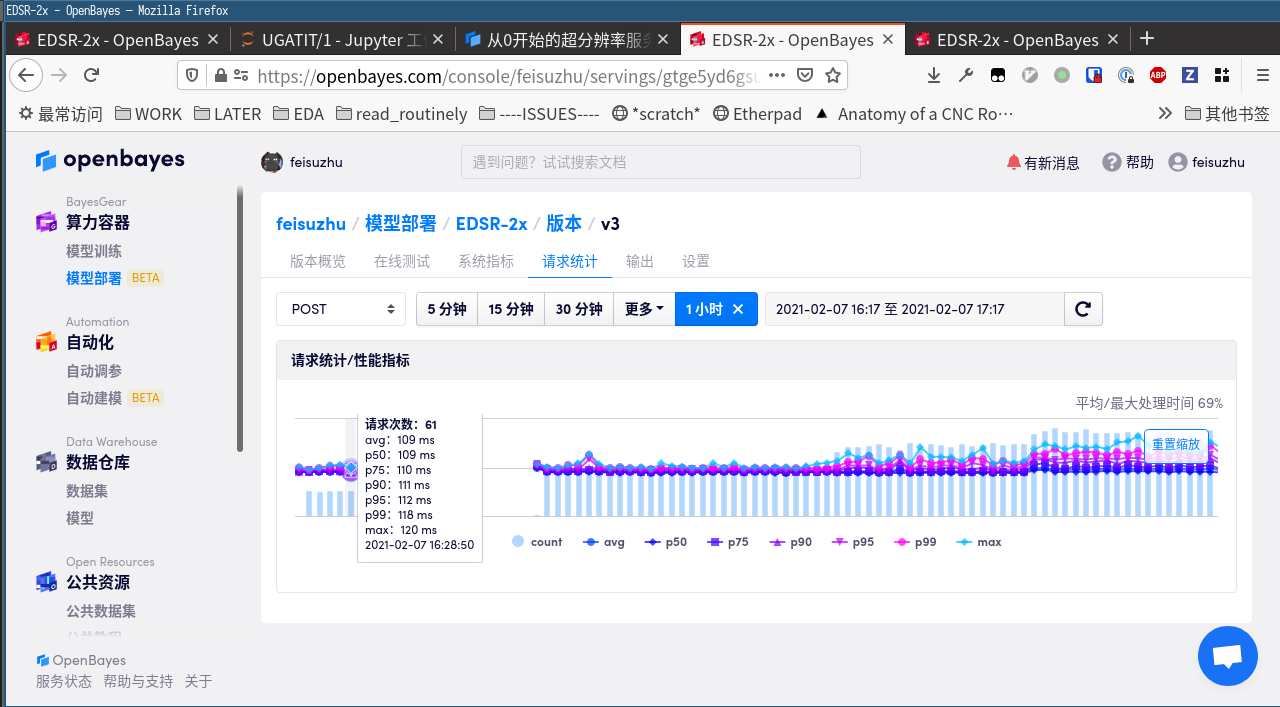
观察到平均(avg)一个请求的处理需要 109ms。这个数据是在后端观察的,不包括发送请求的创建连接、发送数据、回传数据过程。
请求时间的极大值(max)与 50% 分位数(中位数)差距不大,所以每个请求的实际处理时间很稳定。
每个数据点间隔是 10s,每个数据点捉到 61 个请求,所以 QPS 就是 6.1。
平均每个请求的处理时间是 10s/61 = 164ms,这个是客户端实际感知到的请求时间。
然后多开几个 Notebook,并行地向服务发送请求,再次观察。
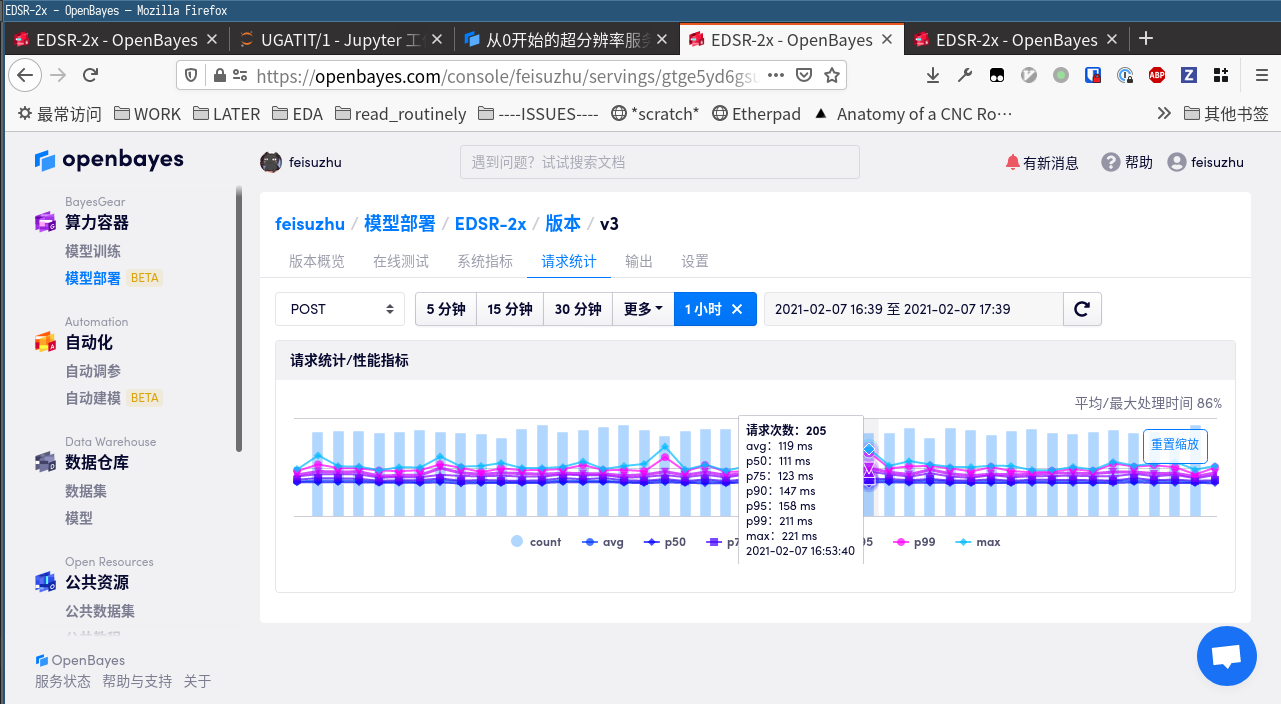
然后发现 QPS 变成了 20.5,但是高位的请求时间已经与 50% 分位数拉开差距了。这是在服务压力大的时候会出现的现象,这些指标会帮助你评估具体的服务质量。