OpenBayes 下识别手写数字
如果你了解机器学习,特别是近年来非常流行的深度学习方法,那么你很可能听说过 MNIST 这个数据集。该数据集来自美国国家标准与技术研究所(National Institute of Standards and Technology,简称 NIST)。训练集(training set)由来自 250 个不同人手写的数字构成,测试集(test set)也是同样比例的手写数字数据。

我们这里就借用这个数据集来介绍在 OpenBayes 中采用 PyTorch / TensorFlow 进行图片的分类。其中会使用到 OpenBayes 的数据集绑定、模型的训练以及模型的使用。
PyTorch
获取代码
从 GitHub 下载样例代码:
git clone https://github.com/signcl/openbayes-mnist-example.git
cd openbayes-mnist-example/pytorch
切换到所下载代码目录看到代码结构如下:
.
├── openbayes.yaml
└── train.py
其中,
.py包含了执行机器学习模型训练和采用模型进行推断的代码openbayes.yaml包含了执行一个「Python 脚本执行」的配置,更多信息见 openbayes cli 配置文件
创建第一个任务
这里介绍的是通过页面上传代码压缩包的流程,但是这已经不再是我们推荐的创建「Python 脚本执行」的最佳实践了,更好的方式参见 bayes 命令行工具入门。
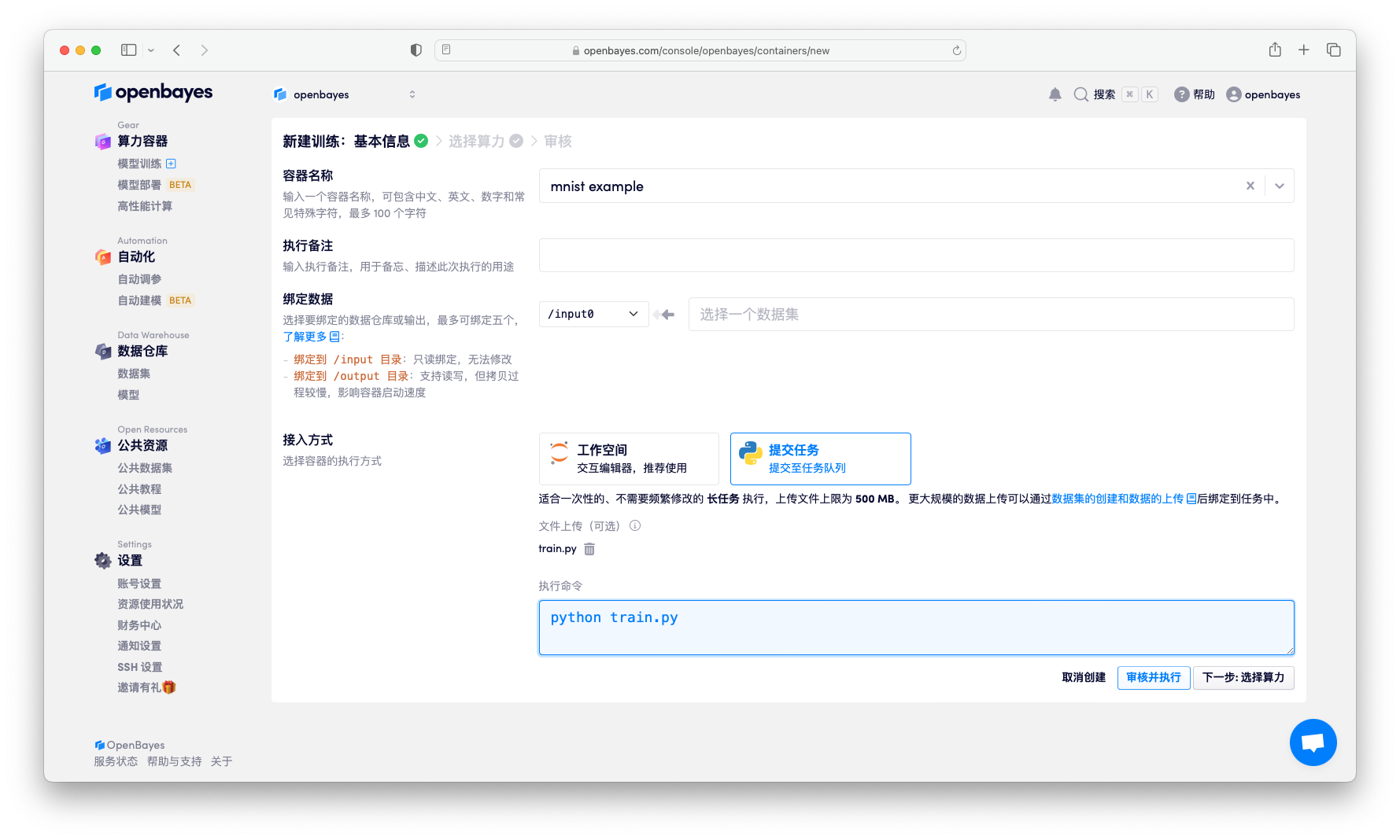
数据集准备好后在页面左侧导航栏点击「新建算力容器」创建一个Python脚本执行任务,采用 train.py 训练一个 Pytorch 的手写识别模型。
在 "新建容器" 页面下接入方式选择 Python 脚本执行,并将目录中 train.py 上传。在执行命令处输入命令:
python train.py
train.py中参数的解析采用了 Python 内置的库argparse进行处理,更多内容见 argparse — Parser for command-line options, arguments and sub-commands。
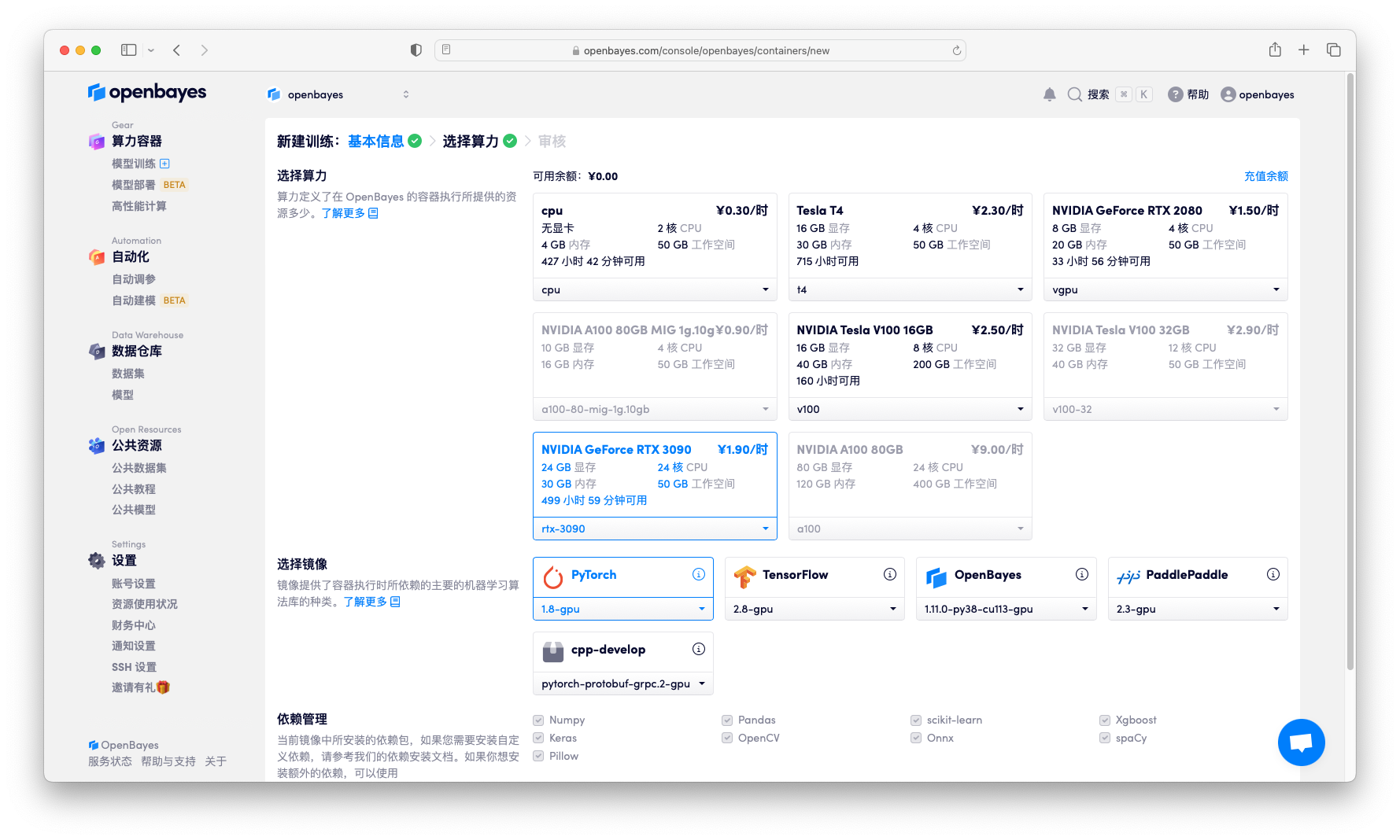
算力选择 CPU(如果有其他 GPU 类型,推荐选择 GPU 类型,速度会快很多),然后镜像选择「pytorch-1.8」,
提交任务后等待 15 秒左右的时间任务将开始执行,在容器页面可以看到日志所展示的执行情况。
TensorFlow
获取代码
从 GitHub 下载样例代码:
git clone https://github.com/signcl/openbayes-mnist-example.git
cd openbayes-mnist-example/tensorflow
切换到所下载代码目录看到代码结构如下:
.
├── inference.py
├── openbayes.yaml
└── train.py
其中,
.py包含了执行机器学习模型训练和采用模型进行推断的代码openbayes.yaml包含了执行一个「Python 脚本」的配置,更多信息见 openbayes cli 配置文件
创建第一个任务
本文介绍了通过页面上传代码压缩包的流程。然而,这已不再是我们推荐的创建「Python 脚本」的最佳实践。更好的方法请参见 bayes 命令行工具入门。
数据集准备好后,在页面左侧导航栏点击「新建算力容器」创建一个 Python 脚本执行的任务,采用 train.py 训练一个 TensorFlow 的手写识别模型。
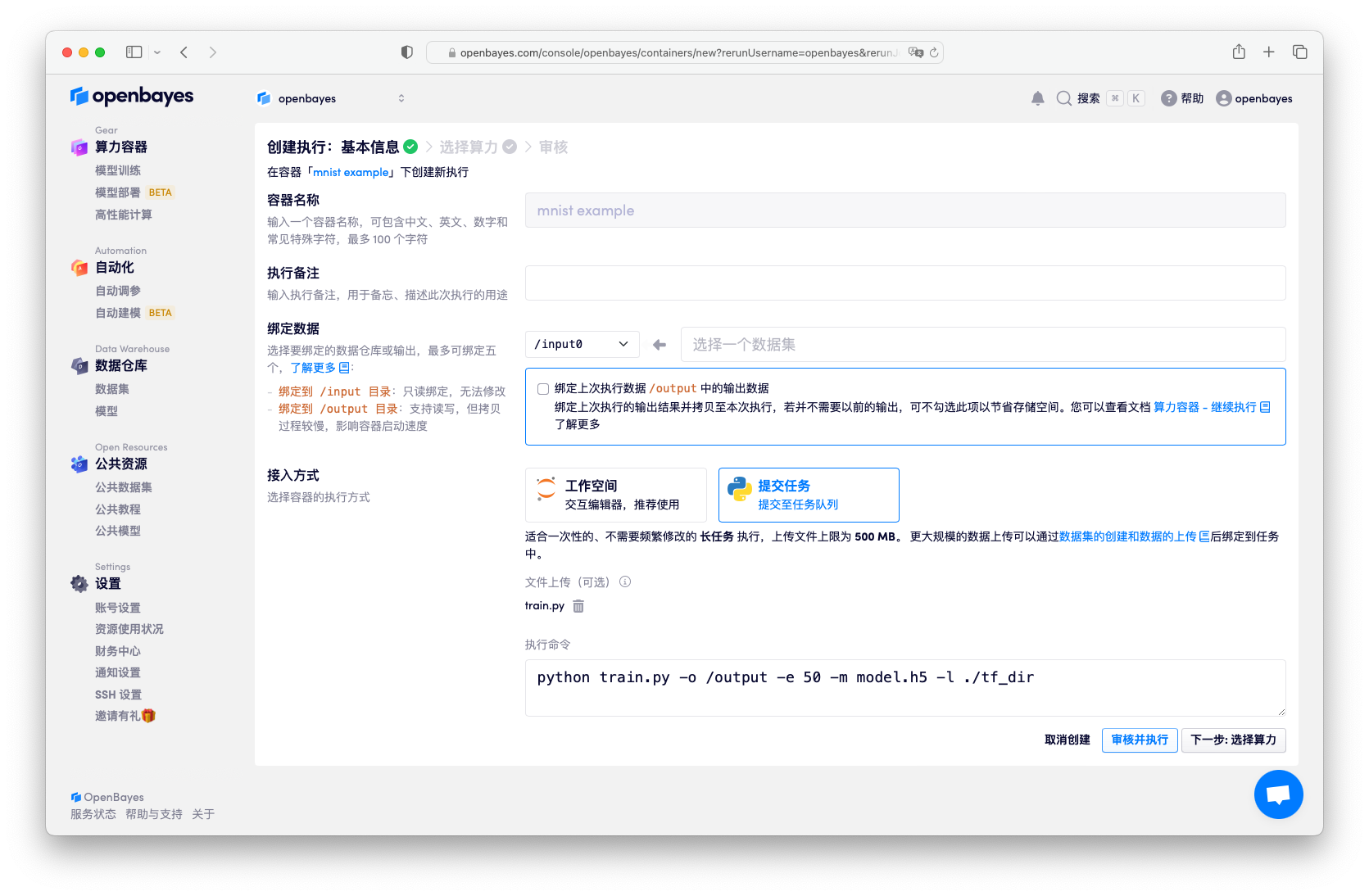
在 "新建容器" 页面下选择「Python 脚本执行」在执行命令处输入命令:
python train.py -o /openbayes/home -e 50 -m model.h5 -l ./tf_dir
其中:
train.py为用于模型训练的 py 文件-o /openbayes/home指明所要保存的文件目录为/openbayes/home,在 Python 脚本执行模式下,系统会将/openbayes/home目录下的结果进行保存并上传,因此所有的工作目录结果都应保存在该目录下,其他目录下,甚至包含默认的 . 目录下的文件更新都将不会被保存-e 50指定了模型训练的epoch值-m model.h5指明的保存的模型的名称,当然结合-o /openbayes/home参数,最终的训练模型会存储到/openbayes/home/model.h5下-l ./tf_dir默认./tf_dir指向 OpenBayes 取 TensorBoard 的目录
train.py中参数的解析采用了 Python 内置的库argparse进行处理,更多内容见 argparse — Parser for command-line options, arguments and sub-commands。
下一步算力选择 CPU,镜像选择 "tensorflow-2.8",接入方式选择「Python 脚本执行」,并将目录中 train.py 文件上传。
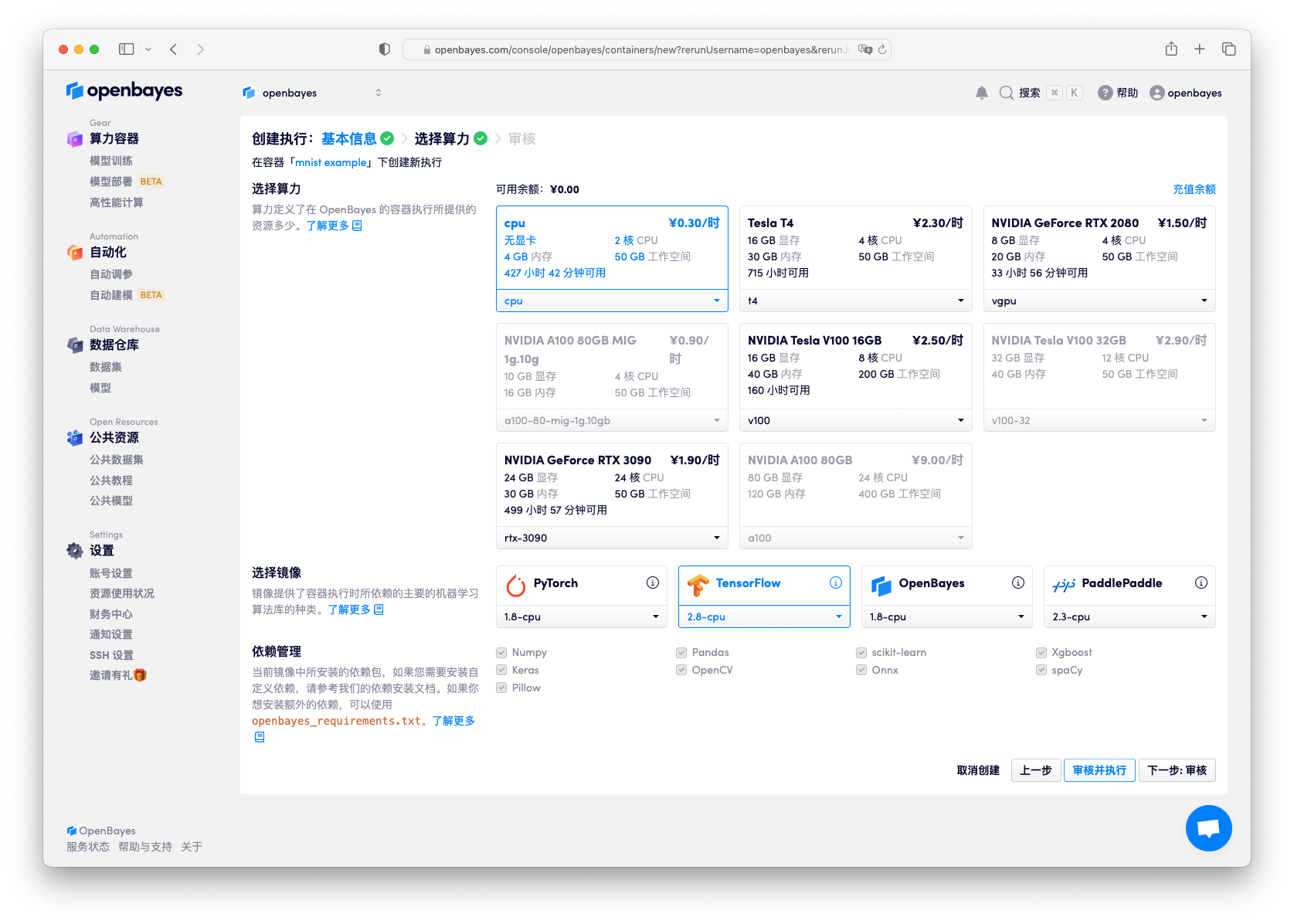
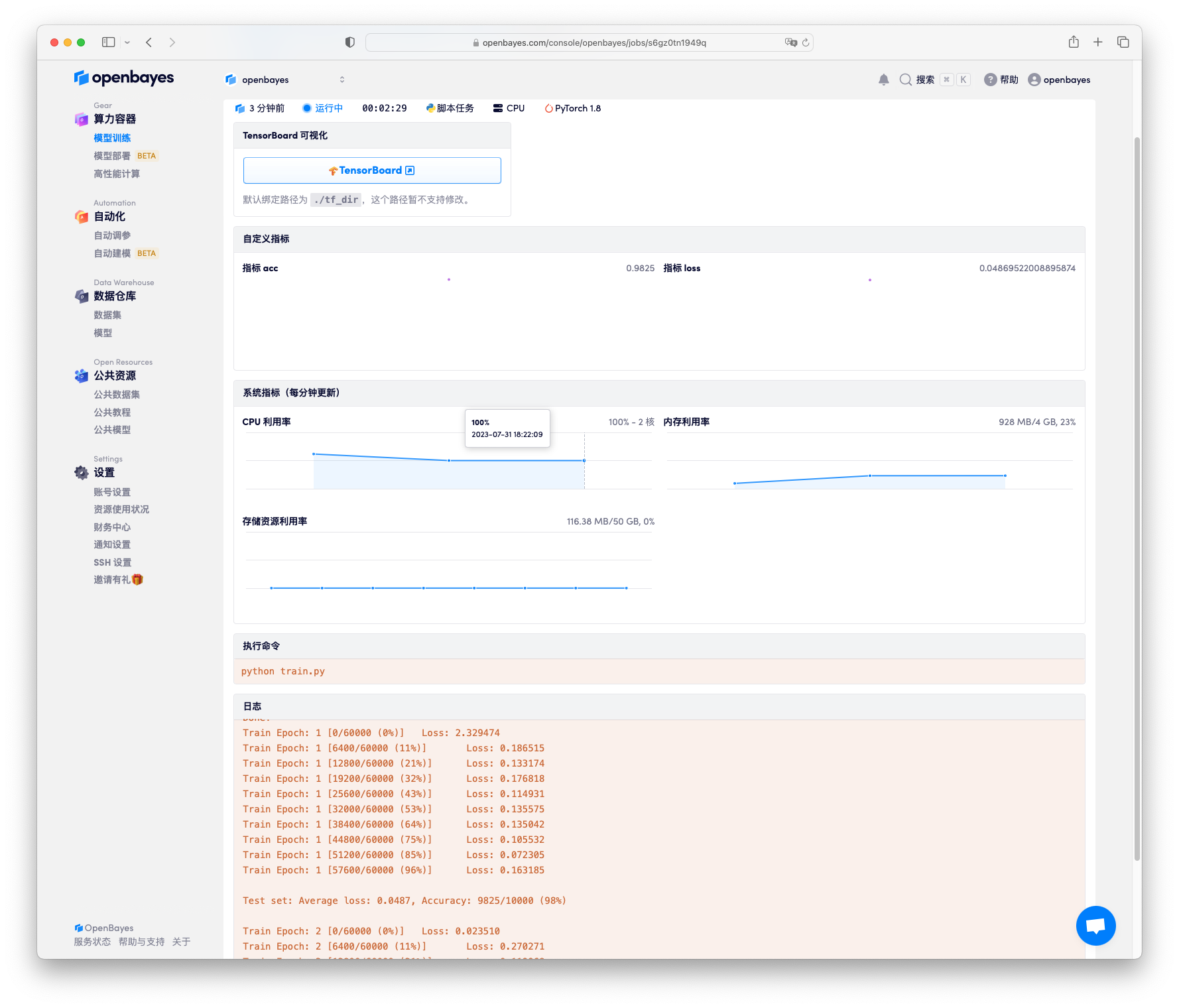
提交后等待 15 秒左右的时间任务将开始执行。任务开启的时间通常与所绑定数据集大小有关,所需数据集越大,容器执行准备时间越长。在容器页面可以看到日志所展示的执行情况。
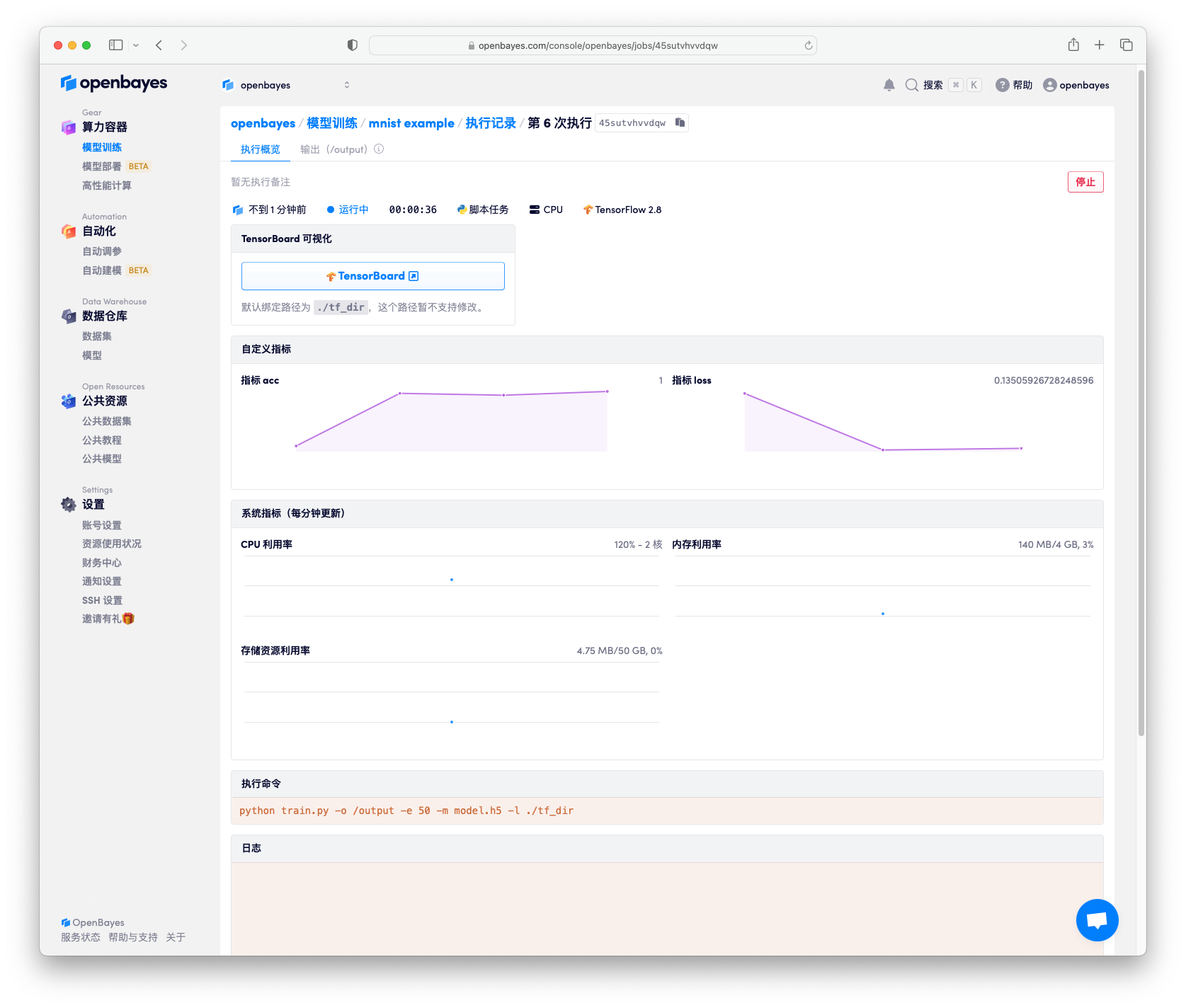
点击「TensorBoard 可视化」可以通过 TensorBoard 查看执行中的模型信息。
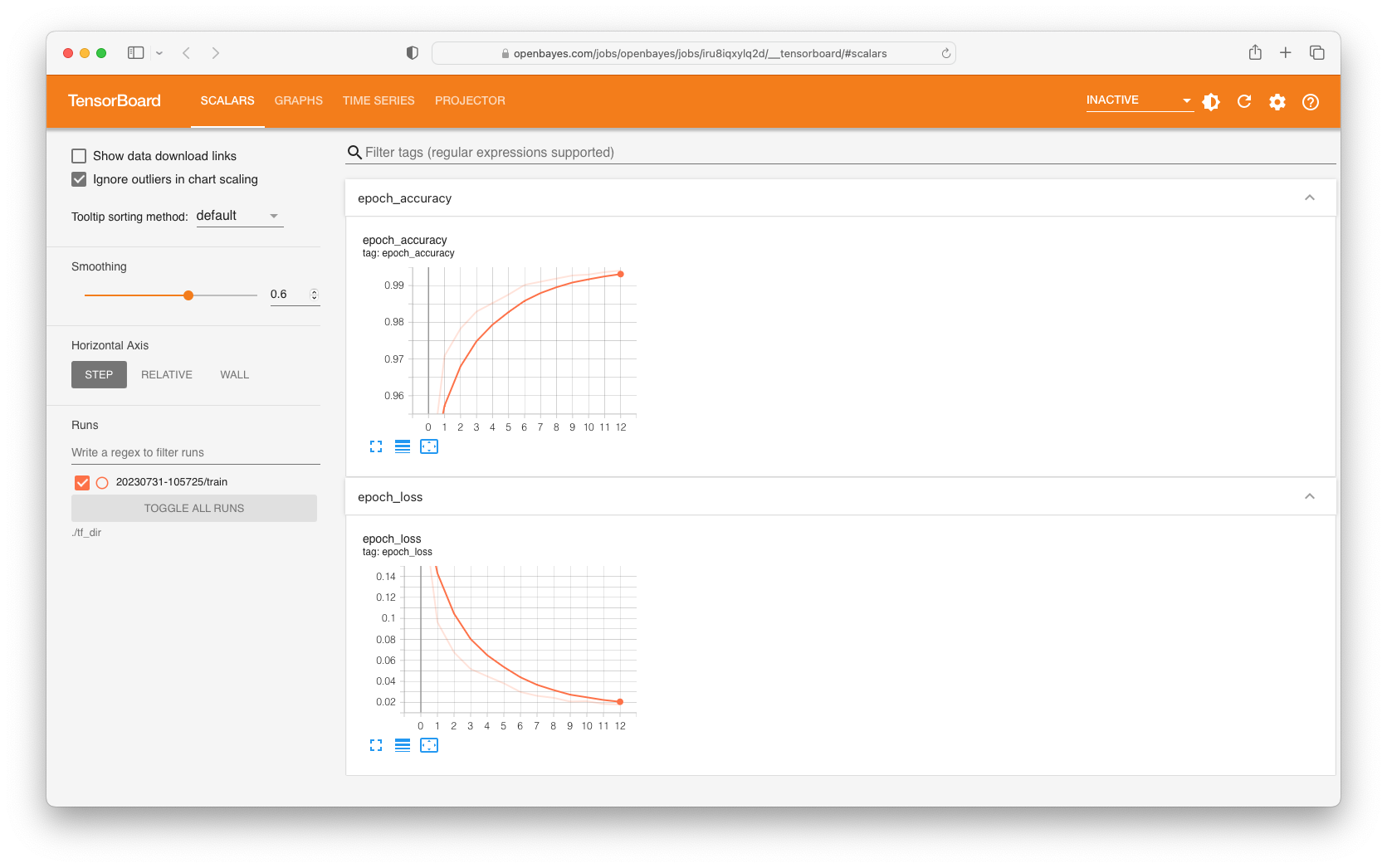
查看执行的目录以及输出结果
执行完毕后,点击容器页面的「工作目录」选项卡可以看到我们所指定的模型已经创建好了。
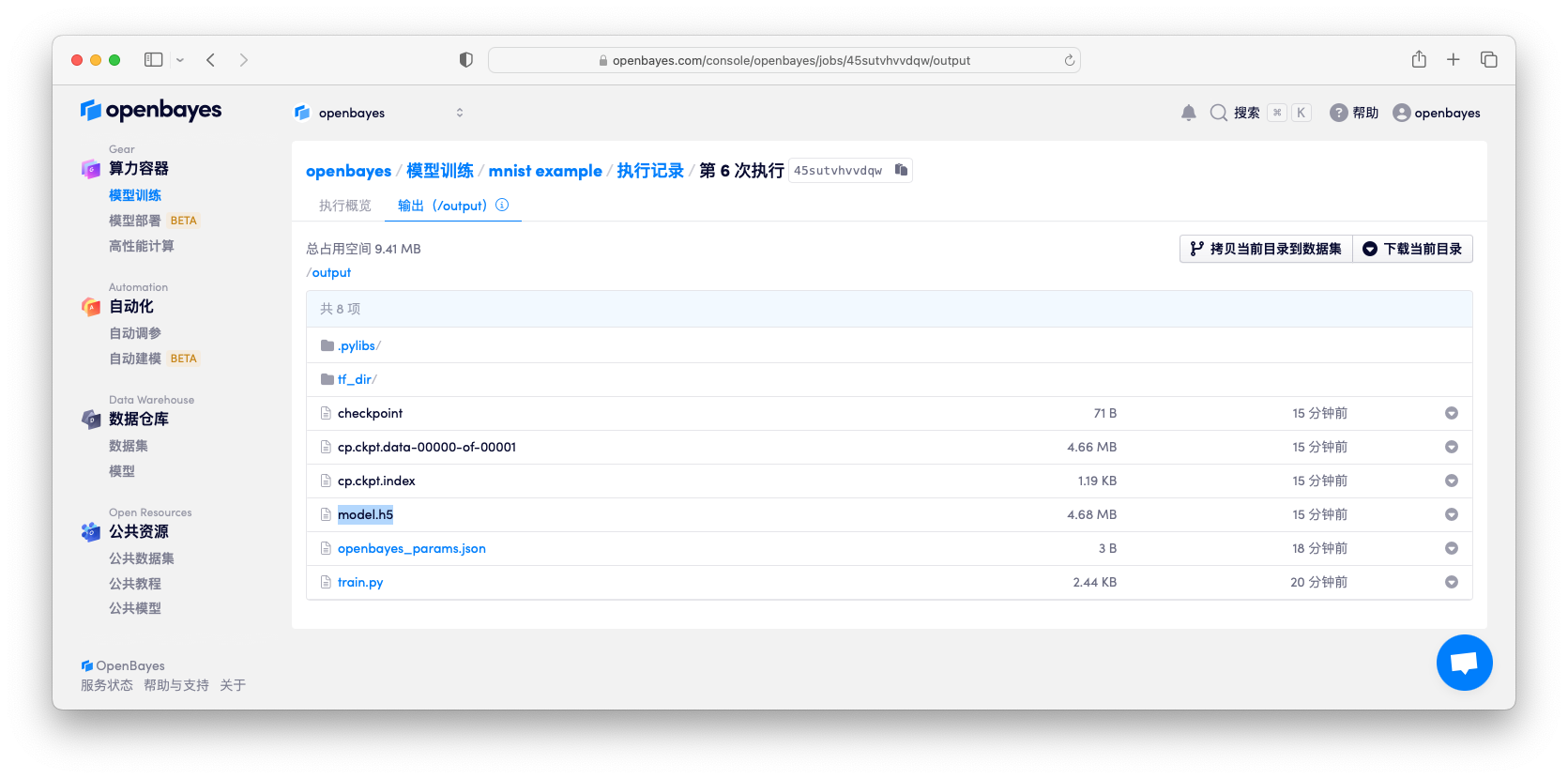
用训练好的模型进行分类
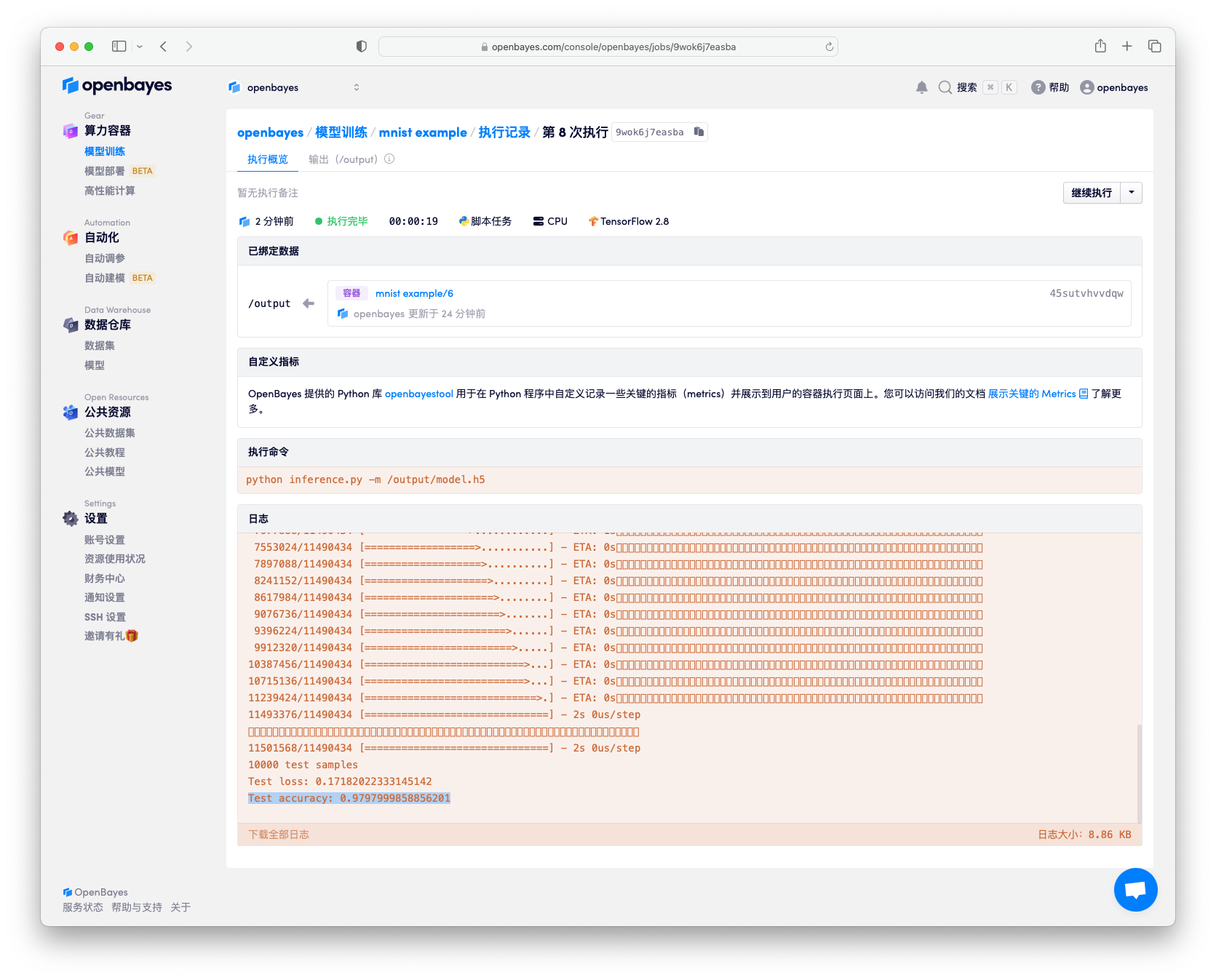
在获取了训练模型后,我们就可以用其对数据进行分类预估了。在已经完成了的执行页面点击右上角的「继续执行」,进入新的执行构建页面。
这里将上一次的「工作目录」的绑定指向 /openbayes/home。更多有关「继续执行」的细节见算力容器的继续执行。
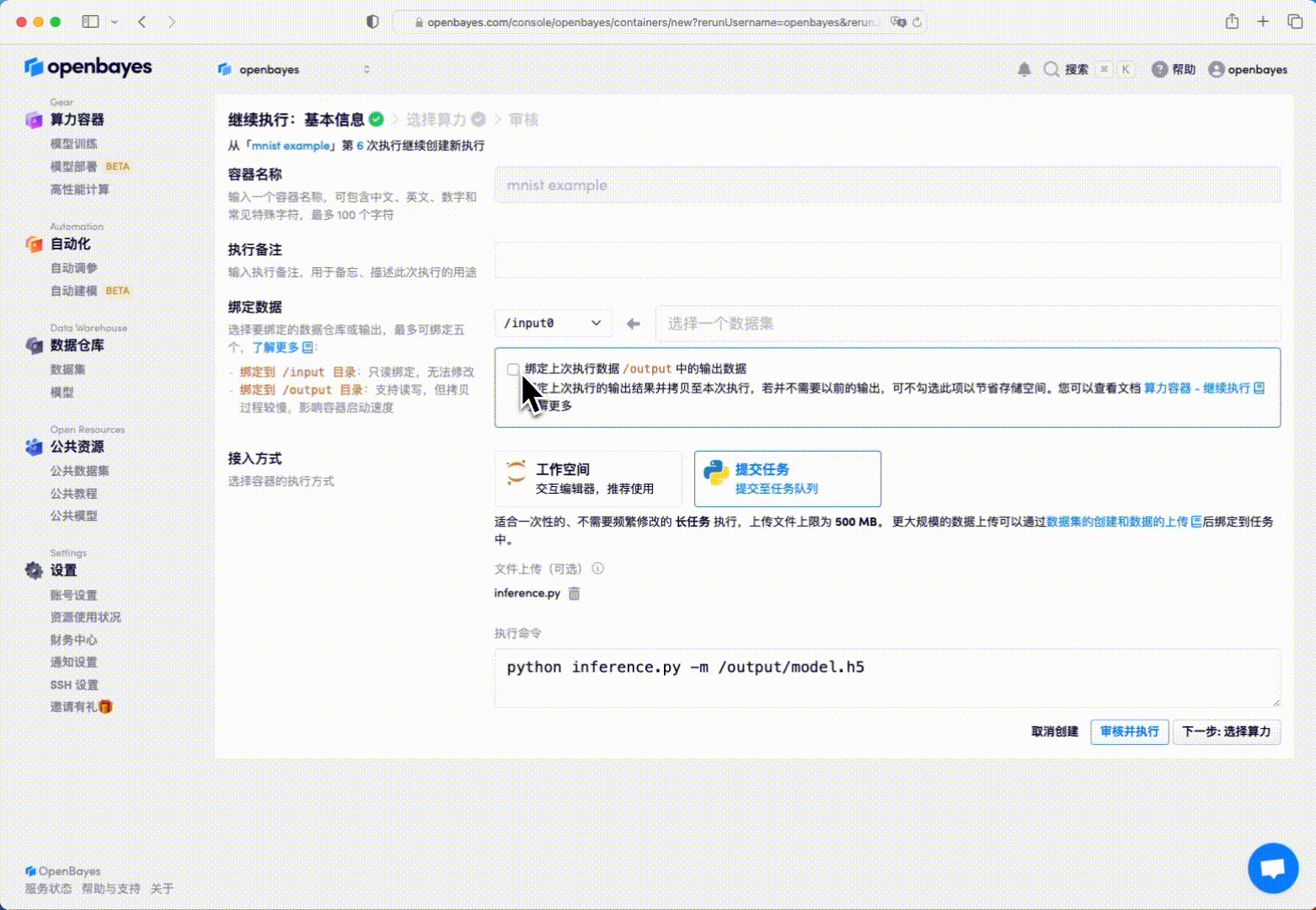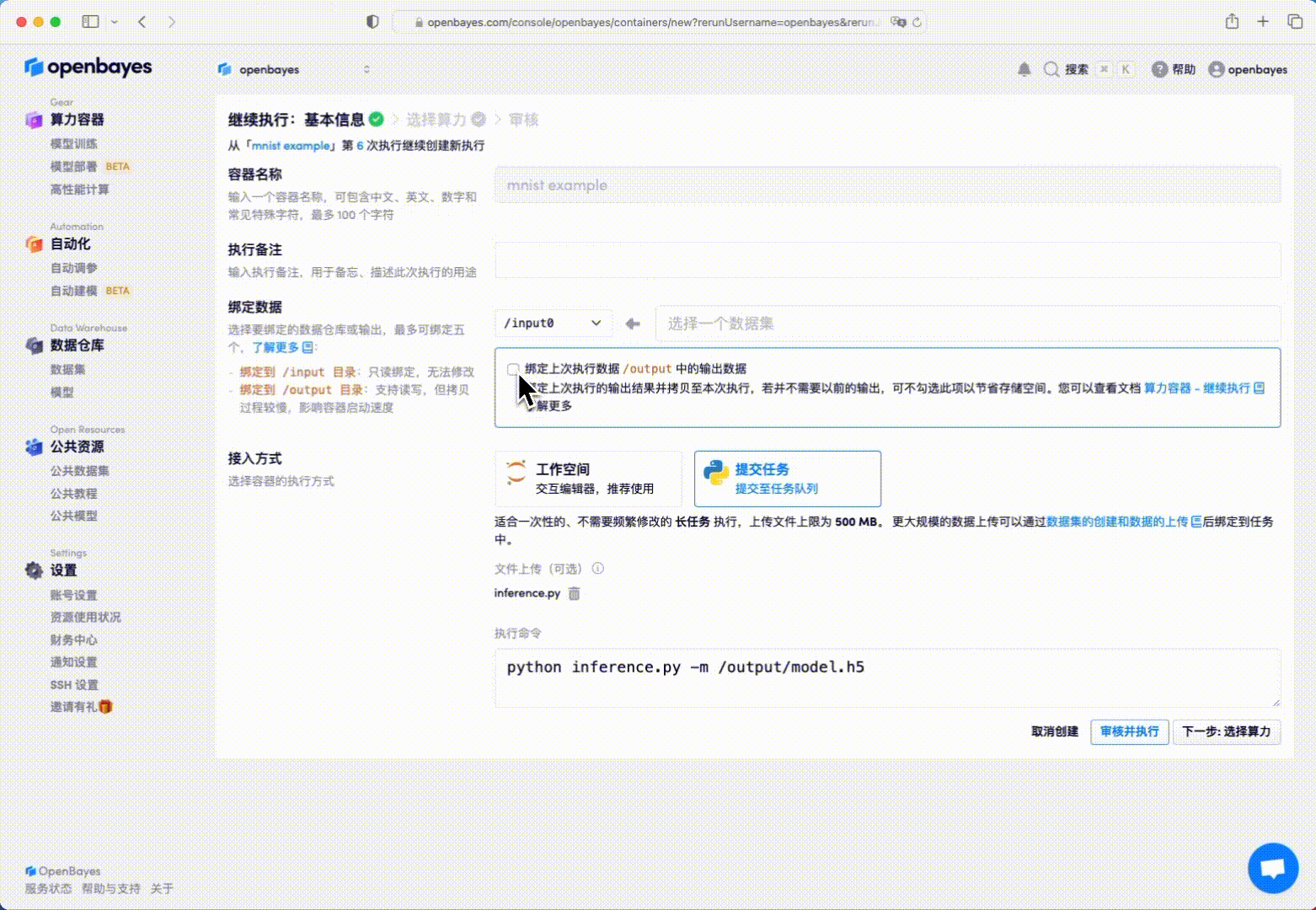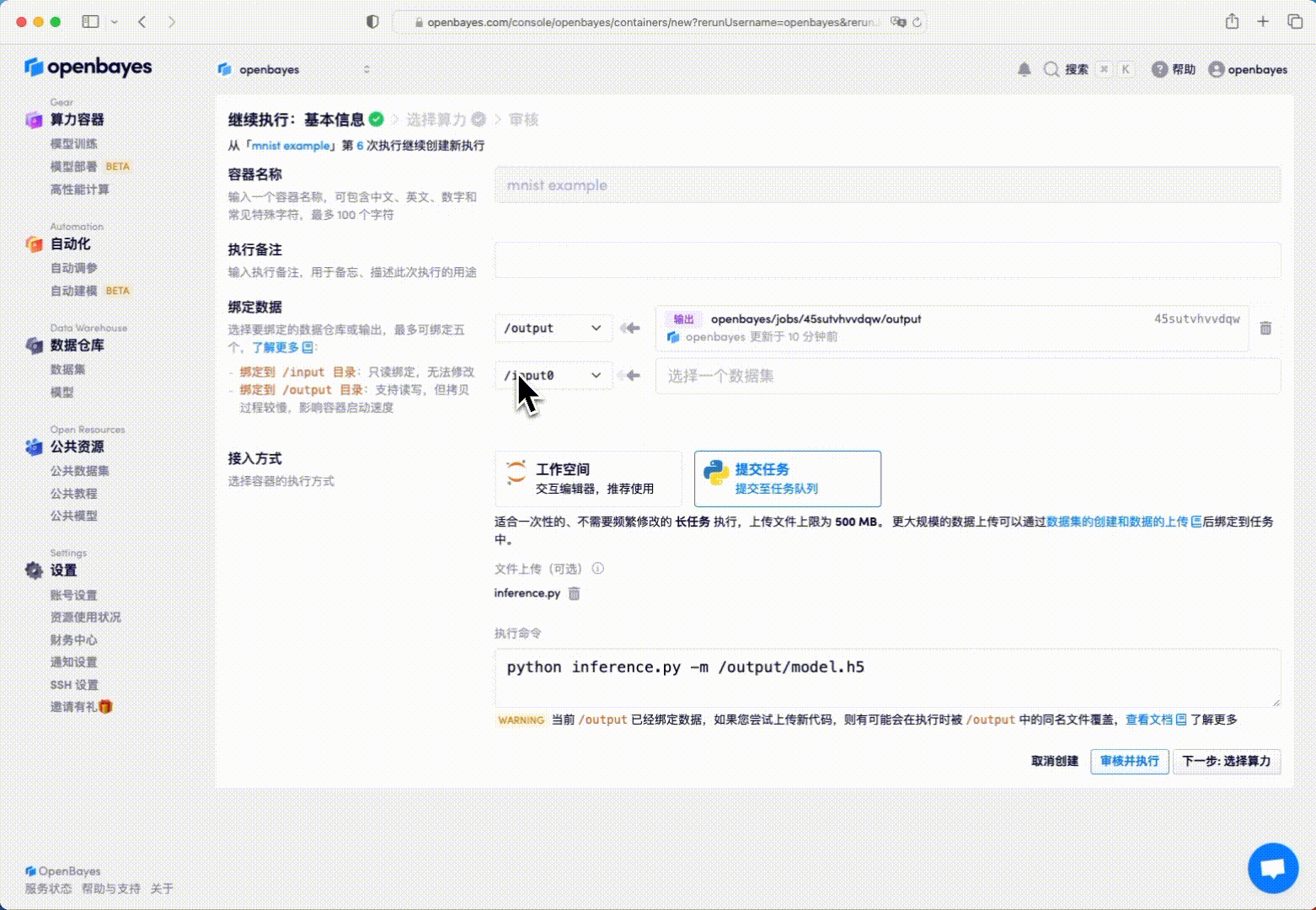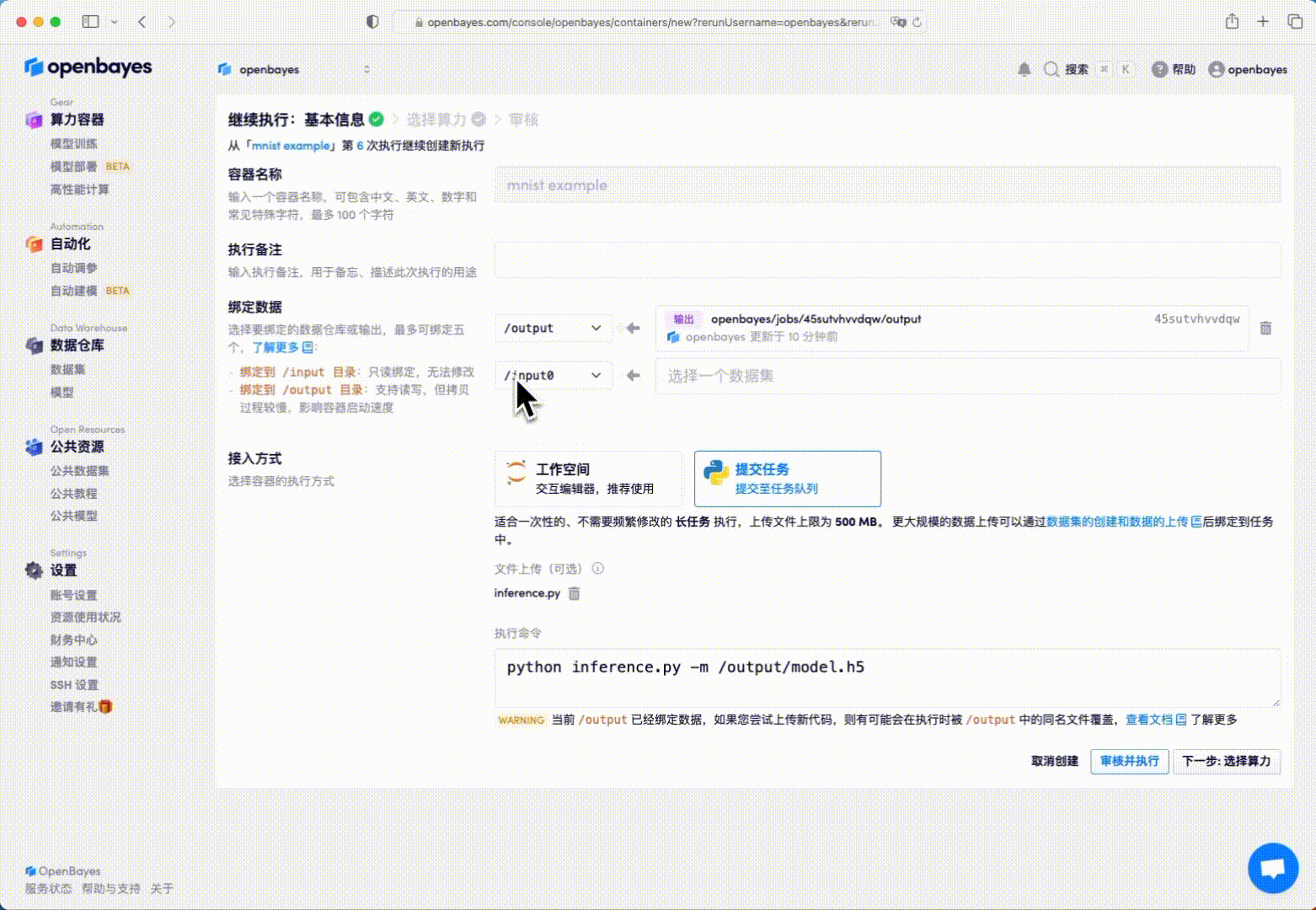
修改指定执行命令:
python inference.py -m /openbayes/home/model.h5
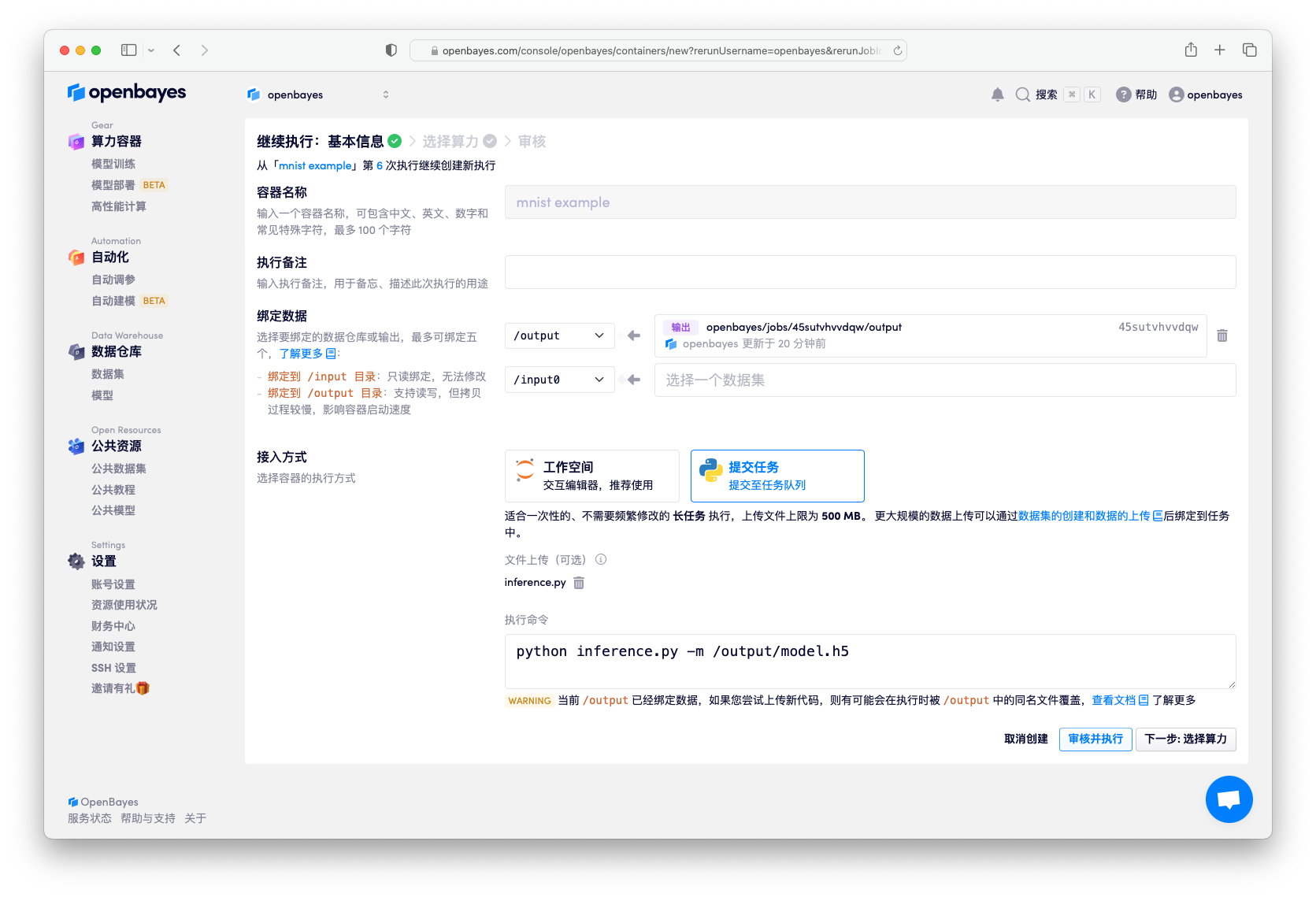
其中 -m /openbayes/home/model.h5 指定需要载入的模型的目录。提交并执行完毕后,可以看到日志中展示了对 10000 测试结果获取了 98% 的准确率。