教程:基于 UIE 的命名实体识别
本教程基于 PaddleNLP 的 Universal Information Extraction 进行命名实体识别任务,并展示通过标注少量数据进行微调获取模型效果快速提升。
完整的 Jupyter 笔记本、代码、标注数据在 https://openbayes.com/console/open-tutorials/containers/lWyxi1DwhJU 都可以找得到。
导入依赖库
from pprint import pprint
from paddlenlp import Taskflow
使用 uie-base 进行命名实体识别
首先直接使用预训练模型 uie-base 进行命名实体识别,不做任何的调优看看效果。
schema = [
'地名',
'人名',
'组织',
'时间',
'产品',
'价格',
'天气'
]
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))
[{'产品': [{'end': 35,
'probability': 0.8594067882980987,
'start': 25,
'text': '《小缇娜的奇幻之地》'}],
'地名': [{'end': 117,
'probability': 0.5248250992968906,
'start': 109,
'text': '小缇娜的奇幻之地'},
{'end': 34,
'probability': 0.3007929716932729,
'start': 26,
'text': '小缇娜的奇幻之地'}],
'时间': [{'end': 52,
'probability': 0.87968346213556,
'start': 38,
'text': '6 月 24 日凌晨 1 点'}],
'组织': [{'end': 93,
'probability': 0.5977969768231866,
'start': 88,
'text': 'Steam'},
{'end': 2,
'probability': 0.6914769673274321,
'start': 0,
'text': '2K'},
{'end': 75,
'probability': 0.5848915911412256,
'start': 71,
'text': 'Epic'},
{'end': 60,
'probability': 0.5682100157587833,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.679590305138845,
'start': 5,
'text': 'Gearbox Software'},
{'end': 105,
'probability': 0.4573145431744834,
'start': 100,
'text': 'Steam'}]}]
pprint(ie("近日,量子计算专家、ACM 计算奖得主 Scott Aaronson 通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校 (UT Austin) 一年,并加盟人工智能研究公司 OpenAI。"))
[{'人名': [{'end': 32,
'probability': 0.4801083732026494,
'start': 24,
'text': 'Aaronson'},
{'end': 23,
'probability': 0.6648137293130958,
'start': 18,
'text': 'Scott'}],
'时间': [{'end': 43,
'probability': 0.8425767345737043,
'start': 41,
'text': '本周'}],
'组织': [{'end': 87,
'probability': 0.5554367836811132,
'start': 81,
'text': 'OpenAI'}]}]
使用默认模型 uie-base 进行命名实体识别,效果还不错,大多数的命名实体被识别出来了,但依然存在部分实体未被识别出,部分文本被误识别等问题。比如 "Scott Aaronson" 被识别为了两个人名,比如 "得克萨斯大学奥斯汀分校" 没有被识别出来。
为提升识别效果,本教程尝试通过标注少量数据对模型进行微调。
数据标注
本教程使用数据标注平台 Label Studio 进行数据标注。所有的工作都是在一个开启了的 「OpenBayes 工作空间」 中完成的。
启动 Label Studio
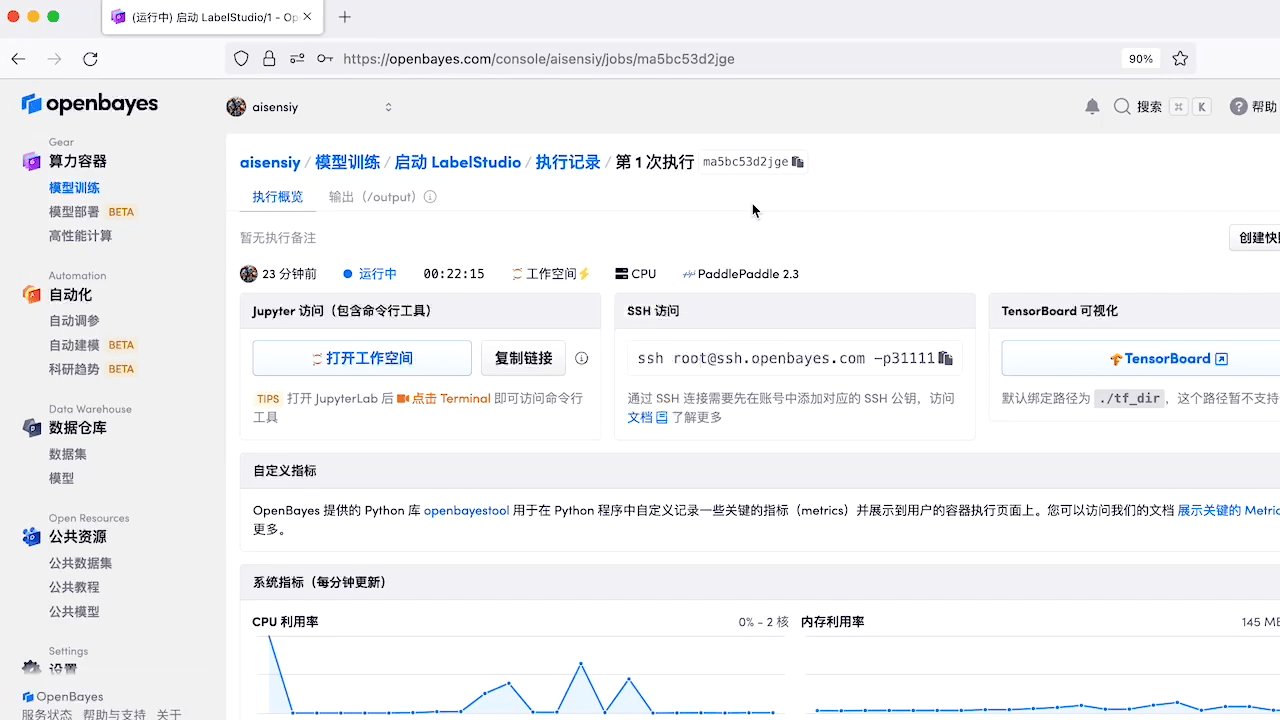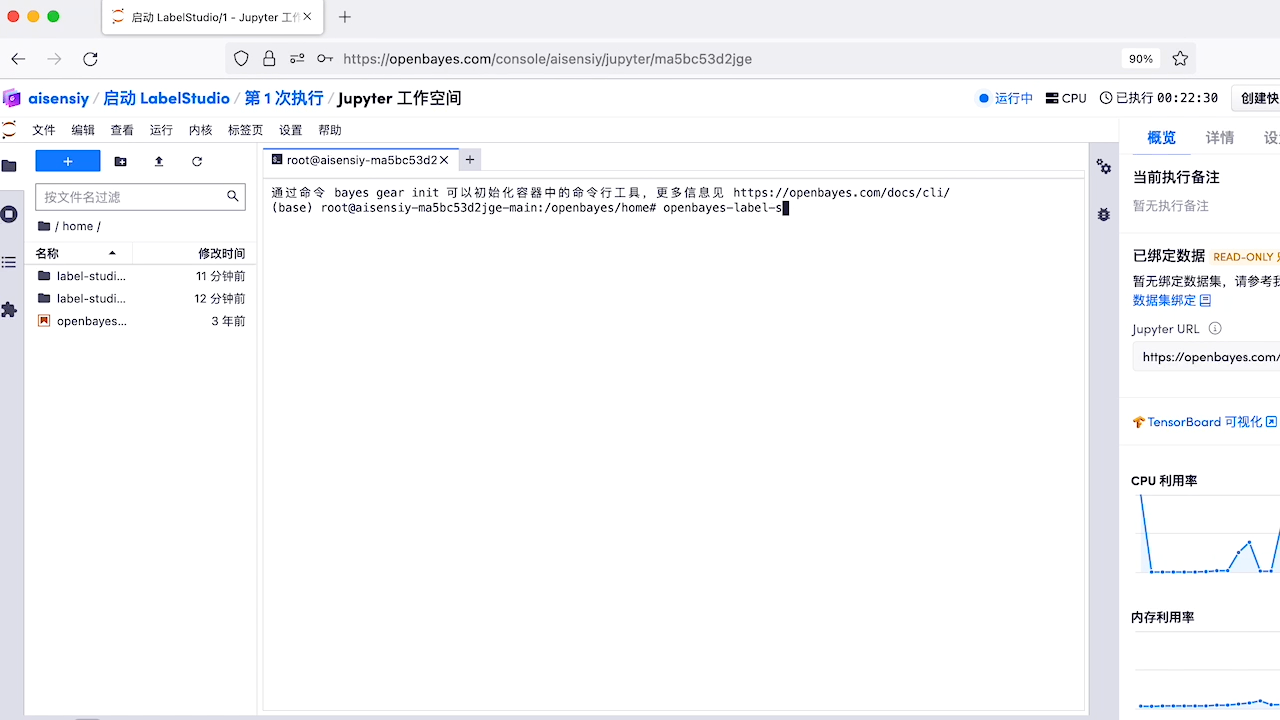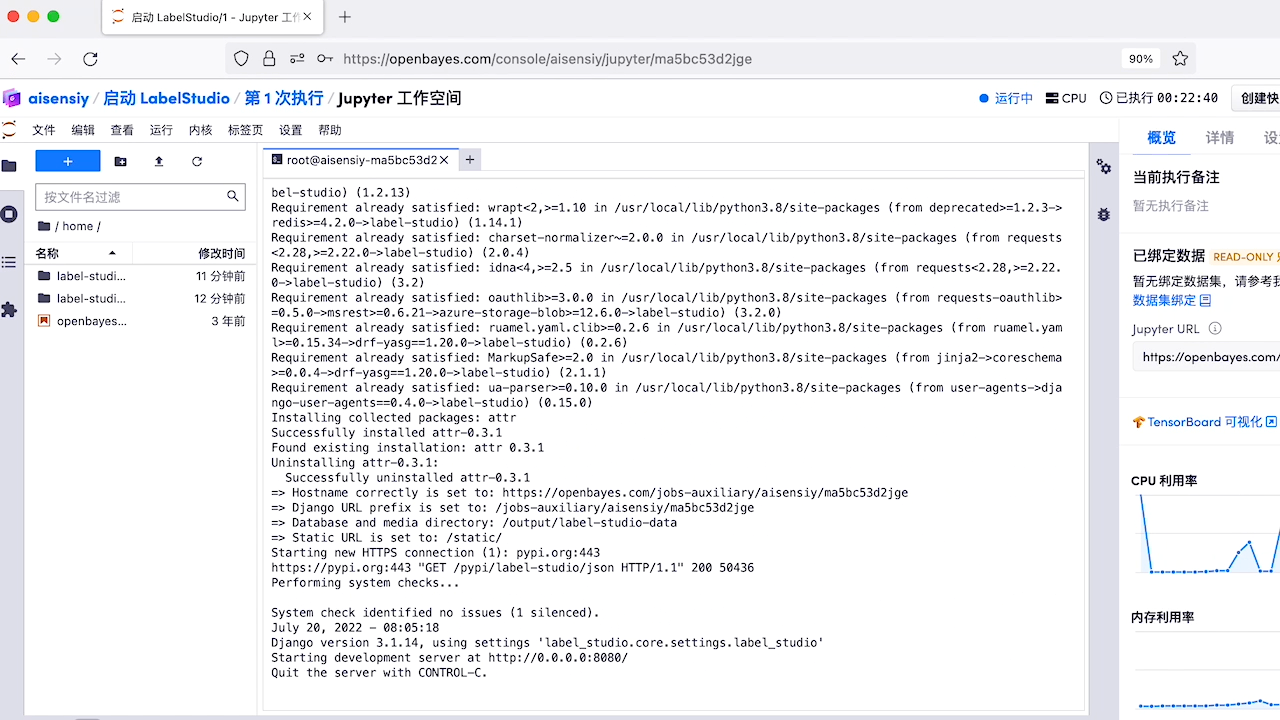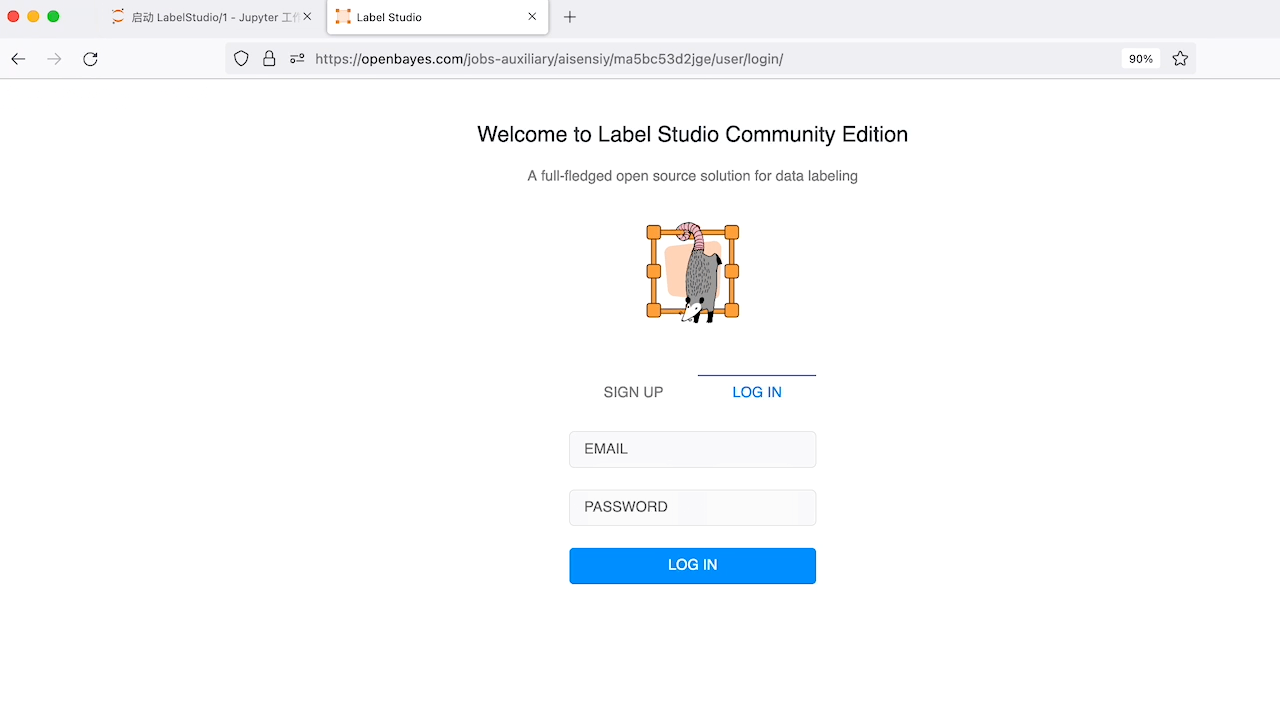
如上所示,在 Jupyter 中打开终端并在终端中执行 openbayes-label-studio 即可在 OpenBayes Jupyter Workspace 中使用 LabelStudio 了。然后使用如下所示的命令行中生成的 url 启动 Label Studio:
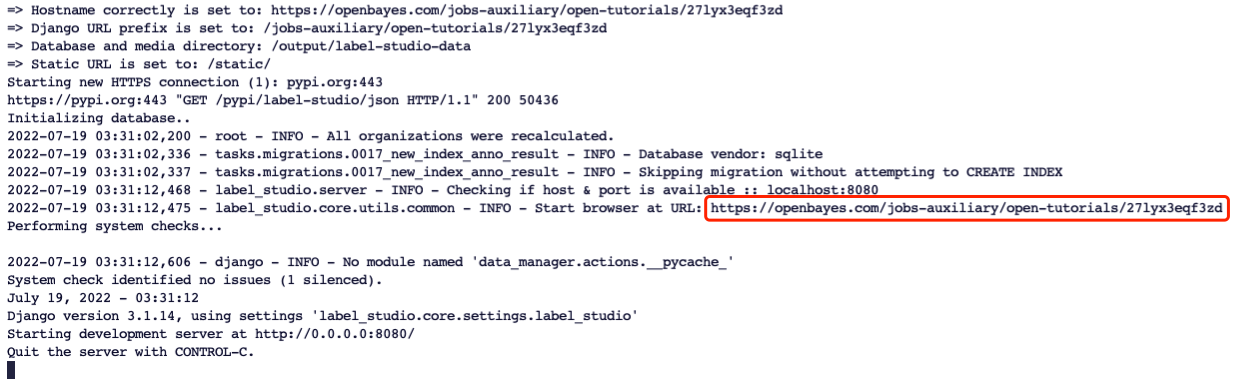
在浏览器中打开链接,注册账户并登录,即可开始使用。
对于不同的 OpenBayes 算力容器,红框中的外部访问链接各不相同,直接使用本教程中的链接是无效的,需用终端中提示的链接进行替换。
标注数据

具体步骤如下:
- 创建项目。
- 导入数据。本教程使用的数据已上传到此算力容器,即
corpus.txt。 - 配置标签界面。在 Natural Language Processing 中选择 Named Entity Recognition 模板,根据需要添加或修改标签。本教程中需要定义的实体标签有『地名』『人名』『组织』『时间』『产品』『价格』『天气』。
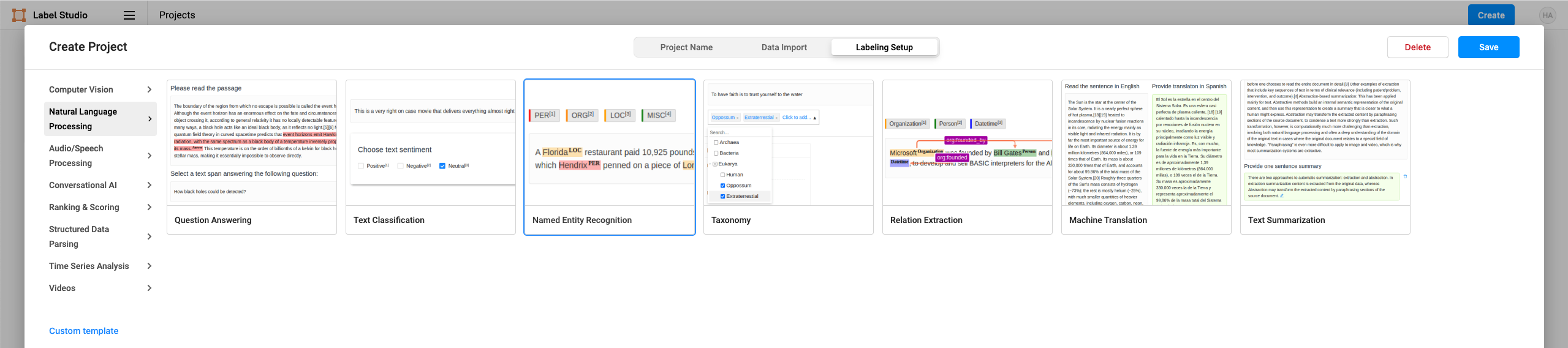
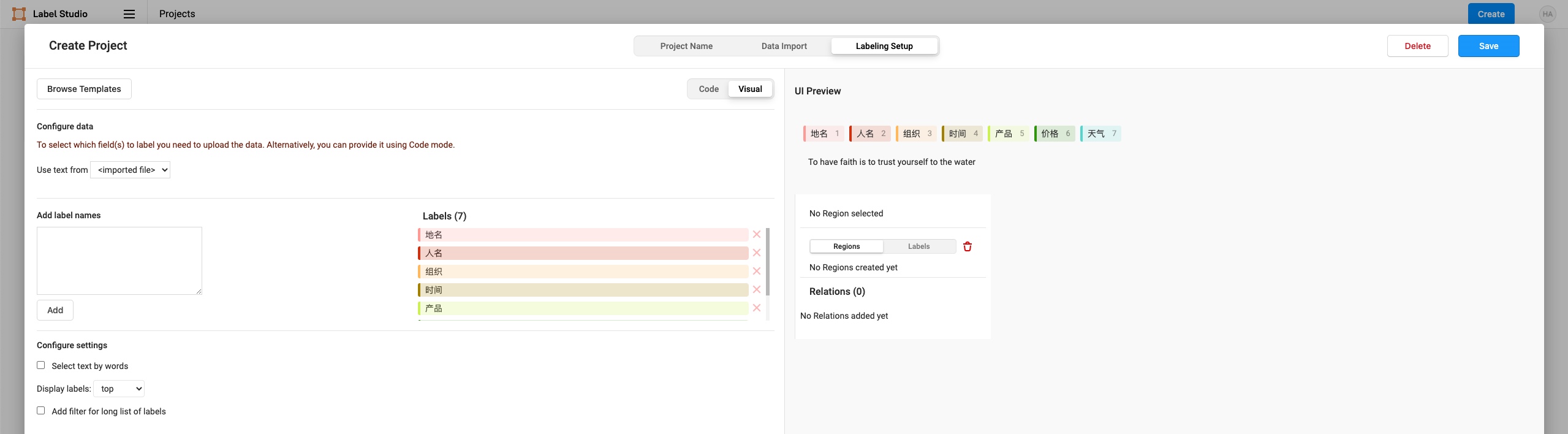
- 开始标注数据。
- 导出数据。标注完成后,从 label studio 导出 JSON 格式的结果文件。此算力容器中已有预先标注好的文件
label-studio.json。
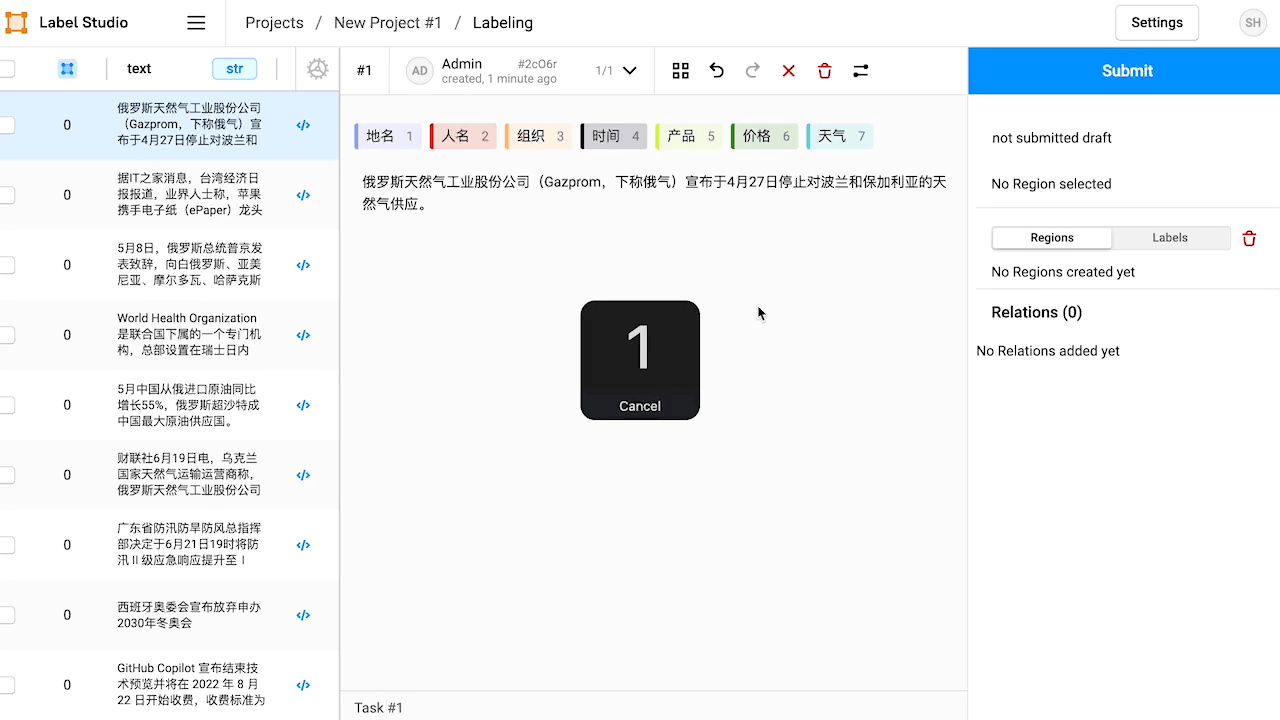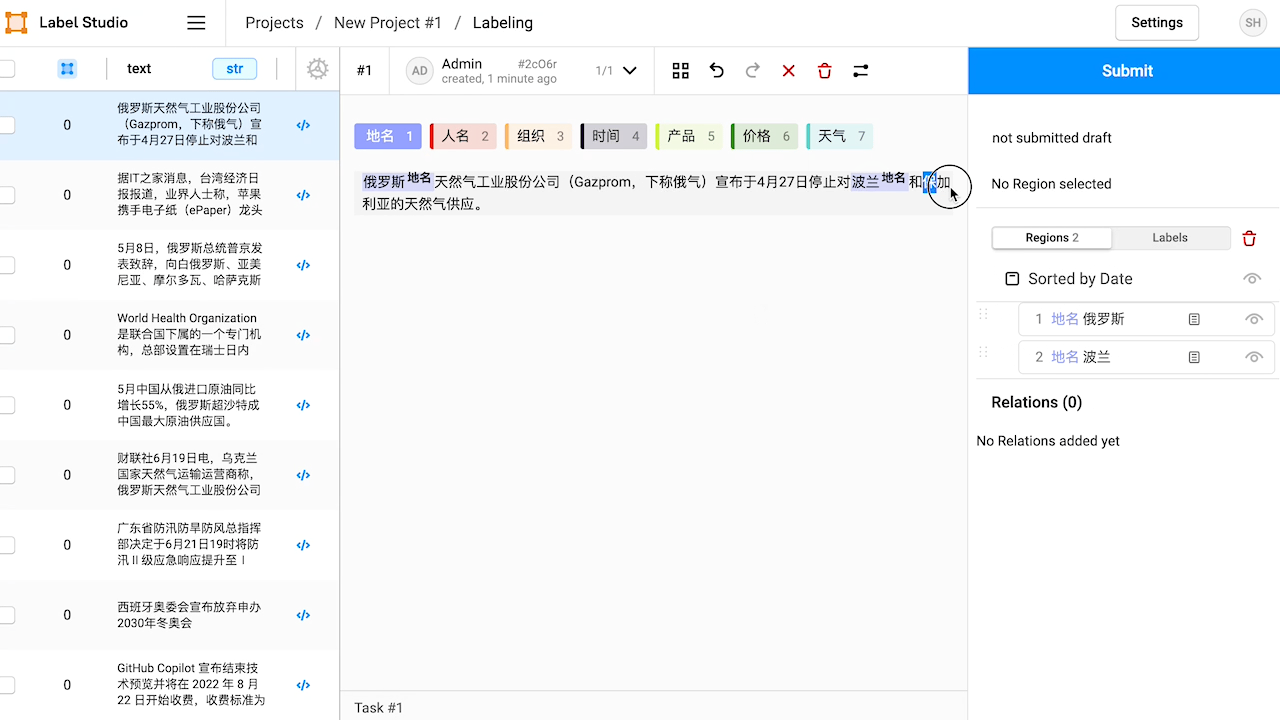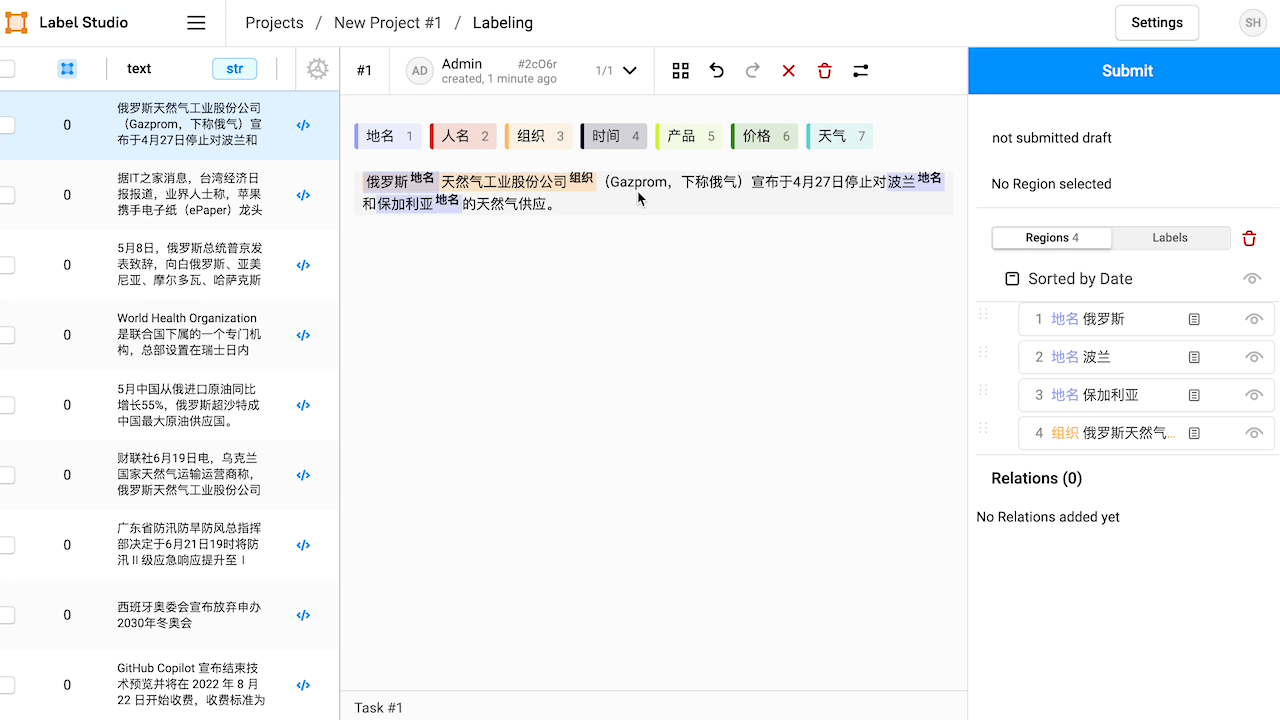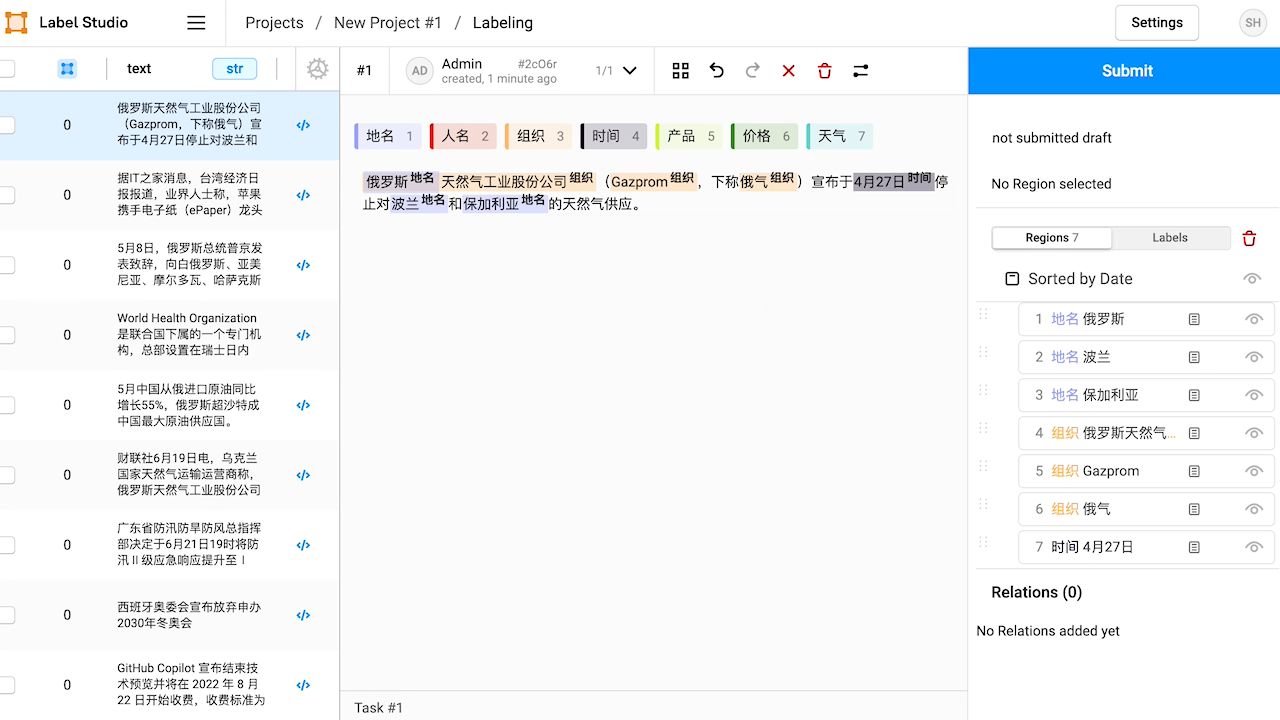
如果你懒得自己标注也没关系,这个教程里的 label-studio.json 就是已经标注好并导出的结果了。
模型微调
以下模型微调所需脚本已上传到此算力容器。
数据转换
在终端中执行以下脚本,将 label studio 导出的数据文件格式转换成 doccano 导出的数据文件格式。
python labelstudio2doccano.py --labelstudio_file label-studio.json
参数说明:
labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。doccano_file: doccano 格式的数据文件保存路径,默认为 "doccano_ext.jsonl"。task_type: 任务类型,可选有抽取("ext")和分类("cls")两种类型的任务,默认为 "ext"。
PaddleNLP 默认并不提供将 labelstudio 的标注格式转换为其所支持的格式的工具,我们这里提供了一个 labelstudio2doccano.py 的脚本。
然后在终端中执行以下脚本,对 doccano 格式的数据文件进行处理,执行后会在 /home/data 目录下生成训练/验证/测试集文件。
python doccano.py \
--doccano_file ./doccano_ext.jsonl \
--task_type "ext" \
--save_dir ./data \
--splits 0.7 0.2 0.1
参数说明:
doccano_file: doccano 格式的数据标注文件路径。task_type: 选择任务类型,可选有抽取("ext")和分类("cls")两种类型的任务。save_dir: 训练数据的保存目录,默认存储在 data 目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为 5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集、测试集所占的比例。默认为 [0.8, 0.1, 0.1] 。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为 ["正向", "负向"]。prompt_prefix: 声明分类任务的 prompt 前缀信息,该参数只对分类类型任务有效。默认为 "情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为 True。seed: 随机种子,默认为 1000。separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为 "##"。
每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件。
Finetune
在终端中执行以下脚本进行模型微调。
python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 4 \
--max_seq_len 512 \
--num_epochs 50 \
--model "uie-base" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device "gpu"
参数说明:
train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为 "./checkpoint"。learning_rate: 学习率,默认为 1e-5。batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。num_epochs: 训练轮数,默认为 100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有 "uie-base", "uie-medium", "uie-mini", "uie-micro" 和 "uie-nano",默认为 "uie-base"。seed: 随机种子,默认为 1000。logging_steps: 日志打印的间隔 steps 数,默认为 10。valid_steps: evaluate 的间隔 steps 数,默认为 100。device: 选用什么设备进行训练,可选 "cpu" 或 "gpu"。init_from_ckpt: 初始化模型参数的路径,可从断点处继续训练。
模型评估
在终端中执行以下脚本进行模型评估。
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
输出:
[2022-07-15 03:18:19,157] [ INFO] - -----------------------------
[2022-07-15 03:18:19,157] [ INFO] - Class Name: all_classes
[2022-07-15 03:18:19,157] [ INFO] - Evaluation Precision: 0.95349 | Recall: 0.89130 | F1: 0.92135
可以看到 F1 已经达到了 0.92,说明模型的效果较好。
参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件 model_state.pdparams 及配置文件 model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。debug: 是否开启 debug 模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
debug 模式输出示例:
[2022-07-15 03:27:57,801] [ INFO] - -----------------------------
[2022-07-15 03:27:57,801] [ INFO] - Class Name: 组织
[2022-07-15 03:27:57,802] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.75000 | F1: 0.85714
[2022-07-15 03:27:57,913] [ INFO] - -----------------------------
[2022-07-15 03:27:57,913] [ INFO] - Class Name: 地名
[2022-07-15 03:27:57,913] [ INFO] - Evaluation Precision: 0.90476 | Recall: 0.82609 | F1: 0.86364
[2022-07-15 03:27:58,046] [ INFO] - -----------------------------
[2022-07-15 03:27:58,046] [ INFO] - Class Name: 时间
[2022-07-15 03:27:58,047] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-15 03:27:58,098] [ INFO] - -----------------------------
[2022-07-15 03:27:58,098] [ INFO] - Class Name: 产品
[2022-07-15 03:27:58,098] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-15 03:27:58,147] [ INFO] - -----------------------------
[2022-07-15 03:27:58,147] [ INFO] - Class Name: 价格
[2022-07-15 03:27:58,147] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-15 03:27:58,176] [ INFO] - -----------------------------
[2022-07-15 03:27:58,176] [ INFO] - Class Name: 人名
[2022-07-15 03:27:58,177] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
微调后效果
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best') # task_path 指定模型权重文件的路径
pprint(my_ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))
[{'产品': [{'end': 148,
'probability': 0.9977381891196586,
'start': 141,
'text': '黄金英雄铠甲包'}],
'时间': [{'end': 52,
'probability': 0.9999856949362851,
'start': 38,
'text': '6 月 24 日凌晨 1 点'},
{'end': 137,
'probability': 0.6508416072546055,
'start': 122,
'text': '2022 年 7 月 8 日前'}],
'组织': [{'end': 21,
'probability': 0.9996073012678011,
'start': 5,
'text': 'Gearbox Software'},
{'end': 93,
'probability': 0.9872895891306825,
'start': 88,
'text': 'Steam'},
{'end': 105,
'probability': 0.9665188911951077,
'start': 100,
'text': 'Steam'},
{'end': 2,
'probability': 0.9883892925330713,
'start': 0,
'text': '2K'},
{'end': 75,
'probability': 0.9965524822425209,
'start': 71,
'text': 'Epic'},
{'end': 60,
'probability': 0.9965759490955008,
'start': 55,
'text': 'Steam'}]}]
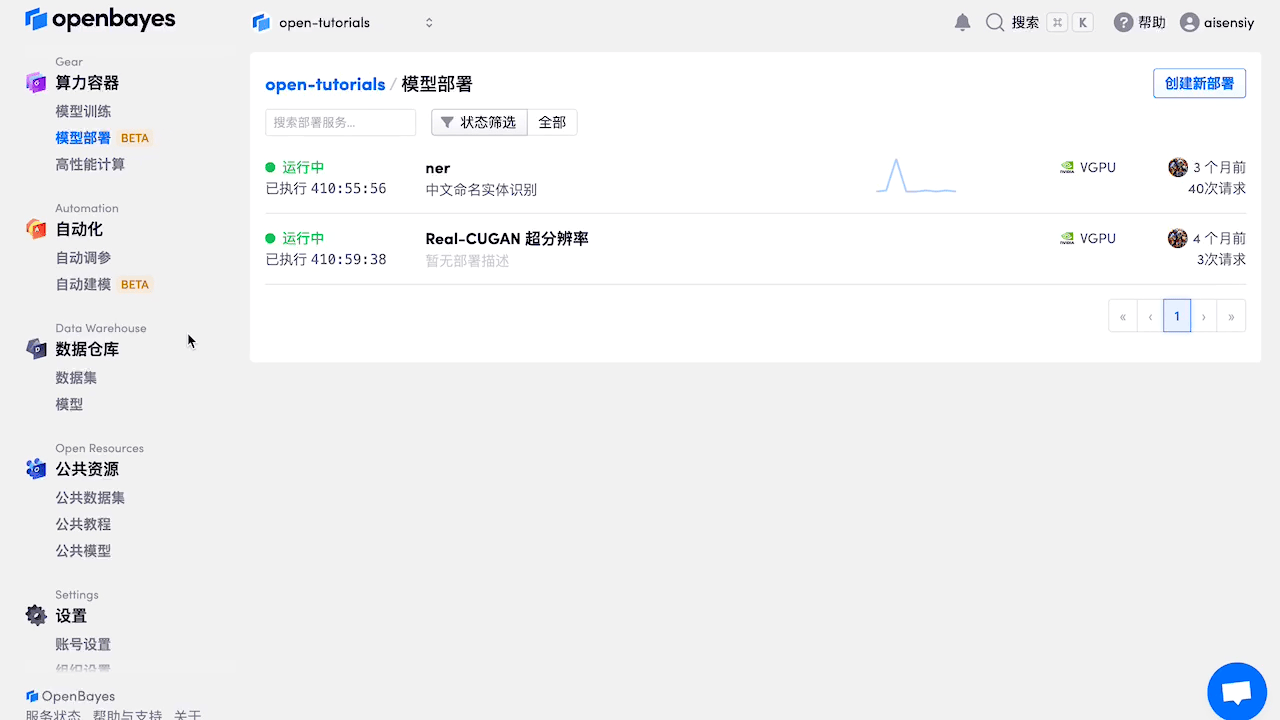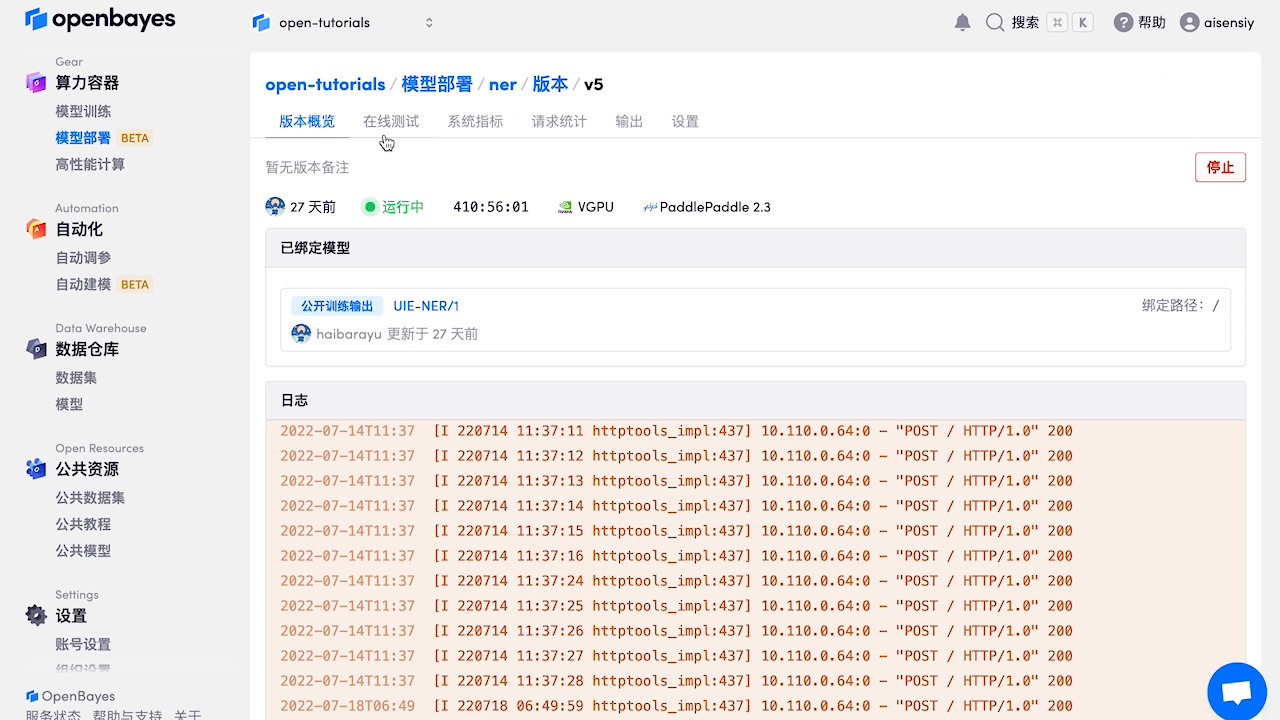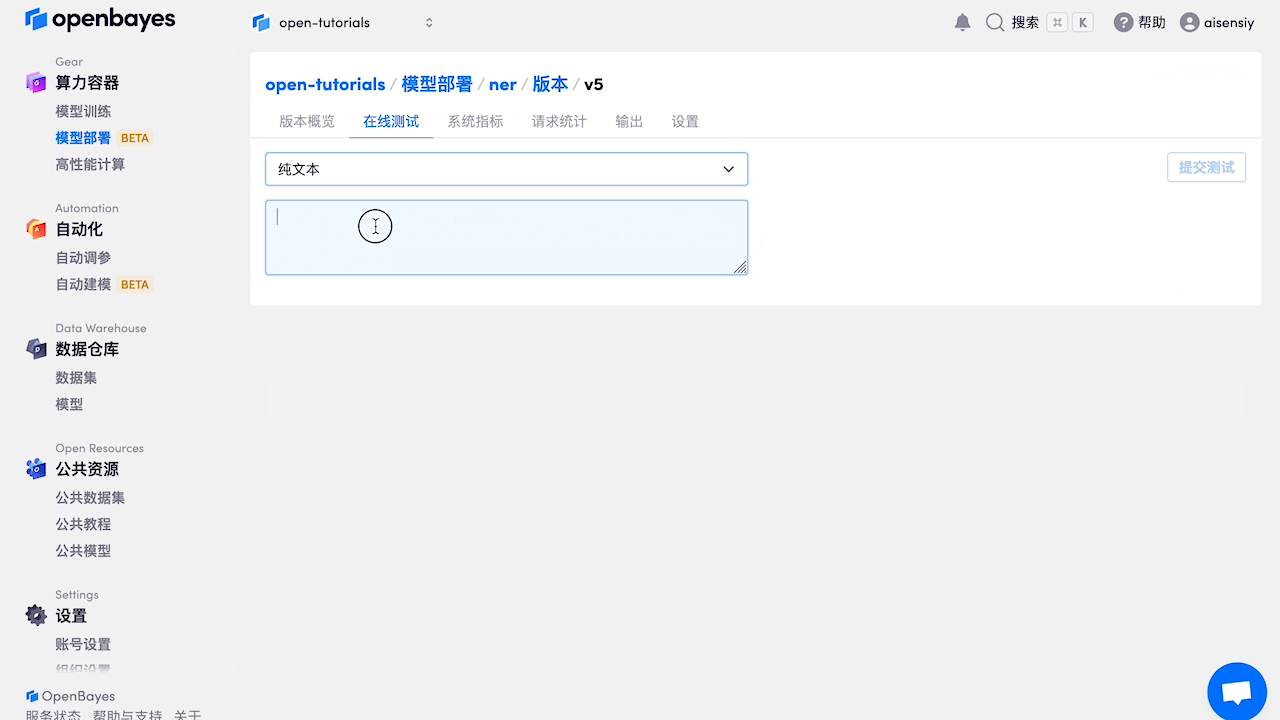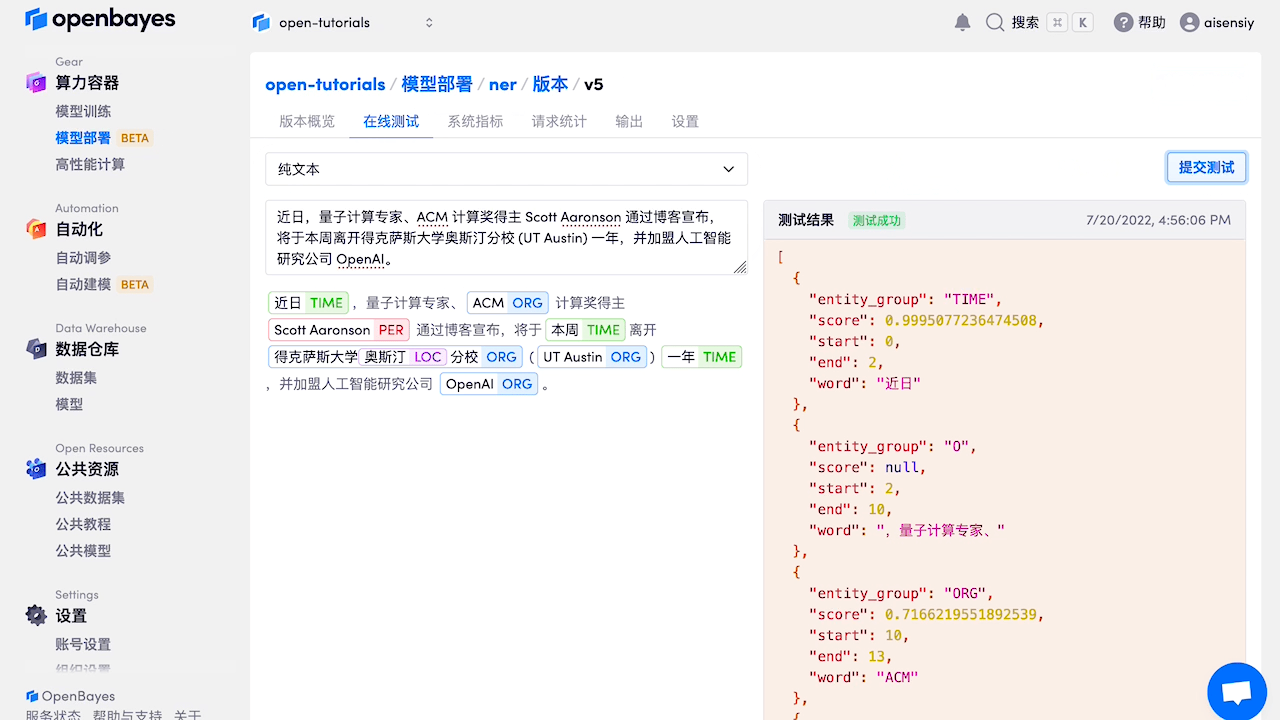
pprint(my_ie("近日,量子计算专家、ACM 计算奖得主 Scott Aaronson 通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校 (UT Austin) 一年,并加盟人工智能研究公司 OpenAI。"))
[{'人名': [{'end': 32,
'probability': 0.9999316942434575,
'start': 18,
'text': 'Scott Aaronson'}],
'地名': [{'end': 54,
'probability': 0.976469583224933,
'start': 51,
'text': '奥斯汀'}],
'时间': [{'end': 69,
'probability': 0.9782005099896942,
'start': 67,
'text': '一年'},
{'end': 2,
'probability': 0.9995077236474508,
'start': 0,
'text': '近日'},
{'end': 43,
'probability': 0.9999382505043286,
'start': 41,
'text': '本周'}],
'组织': [{'end': 66,
'probability': 0.46570937436359827,
'start': 57,
'text': 'UT Austin'},
{'end': 56,
'probability': 0.9686587700987381,
'start': 45,
'text': '得克萨斯大学奥斯汀分校'},
{'end': 13,
'probability': 0.7166219551892539,
'start': 10,
'text': 'ACM'},
{'end': 87,
'probability': 0.999835617128781,
'start': 81,
'text': 'OpenAI'}]}]
模型部署
得到微调后的模型后,可以将模型部署到 OpenBayes 的服务端,以实现实时的模型推理服务。
更多有关模型部署的信息可参考 模型部署介绍 和 基于迁移学习的中文命名实体识别的模型部署。
Serving 服务编写
编写 predictor.py 文件:
- 导入依赖库:除了业务中用到的库之外,需要额外依赖 openbayes-serving。
import openbayes_serving as serv
from paddlenlp import Taskflow
-
后处理(可选):根据需要对模型返回的结果进行处理,以更好地展示。本教程中通过
format()函数和add_o()函数修改命名实体识别结果的形式。 -
Predictor 类: 不需要继承其他的类,但是至少需要提供
__init__和predict两个接口。- 在
__init__中定义实体抽取结构,通过Taskflow加载模型。 - 在
predict中进行预测,返回后处理的结果。
- 在
class Predictor:
def __init__(self):
self.schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气']
self.ie = Taskflow("information_extraction", schema=self.schema, task_path='./checkpoint/model_best')
def predict(self, json):
text = json["input"]
uie = self.ie(text)[0]
result = format(text, uie)
return result
- 运行:启动服务。
if __name__ == '__main__':
serv.run(Predictor)
在教程的根目录下已经提供了编写好的 predictor.py 可以直接在后续使用。
在 Jupyter 中测试
在终端中执行 OPENBAYES_JOB_URL= python predictor.py ,成功开启本地测试服务后,在此 Notebook 中执行下列代码进行测试。
import requests
text = {
"input": "近日,量子计算专家、ACM 计算奖得主 Scott Aaronson 通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校 (UT Austin) 一年,并加盟人工智能研究公司 OpenAI。"
}
result = requests.post('http://localhost:25252', json=text)
result.json()
[{'entity_group': 'TIME',
'score': 0.9995077236474508,
'start': 0,
'end': 2,
'word': '近日'},
{'entity_group': 'O',
'score': None,
'start': 2,
'end': 10,
'word': ',量子计算专家、'},
{'entity_group': 'ORG',
'score': 0.7166219551892539,
'start': 10,
'end': 13,
'word': 'ACM'},
{'entity_group': 'O', 'score': None, 'start': 13, 'end': 18, 'word': '计算奖得主'},
{'entity_group': 'PER',
'score': 0.9999316942434575,
'start': 18,
'end': 32,
'word': 'Scott Aaronson'},
{'entity_group': 'O',
'score': None,
'start': 32,
'end': 41,
'word': '通过博客宣布,将于'},
{'entity_group': 'TIME',
'score': 0.9999382505043286,
'start': 41,
'end': 43,
'word': '本周'},
{'entity_group': 'O', 'score': None, 'start': 43, 'end': 45, 'word': '离开'},
{'entity_group': 'ORG',
'score': 0.9686587700987381,
'start': 45,
'end': 56,
'word': '得克萨斯大学奥斯汀分校'},
{'entity_group': 'LOC',
'score': 0.976469583224933,
'start': 51,
'end': 54,
'word': '奥斯汀'},
{'entity_group': 'O', 'score': None, 'start': 56, 'end': 57, 'word': '('},
{'entity_group': 'ORG',
'score': 0.46570937436359827,
'start': 57,
'end': 66,
'word': 'UT Austin'},
{'entity_group': 'O', 'score': None, 'start': 66, 'end': 67, 'word': ')'},
{'entity_group': 'TIME',
'score': 0.9782005099896942,
'start': 67,
'end': 69,
'word': '一年'},
{'entity_group': 'O',
'score': None,
'start': 69,
'end': 81,
'word': ',并加盟人工智能研究公司'},
{'entity_group': 'ORG',
'score': 0.999835617128781,
'start': 81,
'end': 87,
'word': 'OpenAI'},
{'entity_group': 'O', 'score': None, 'start': 87, 'end': 88, 'word': '。'}]
部署
测试成功后,停止此算力容器,等待同步数据完成。
在『算力容器』-『模型部署』中点击『创建新部署』,选择与开发时相同的镜像,绑定此算力容器,点击『部署』,即可进行在线测试。
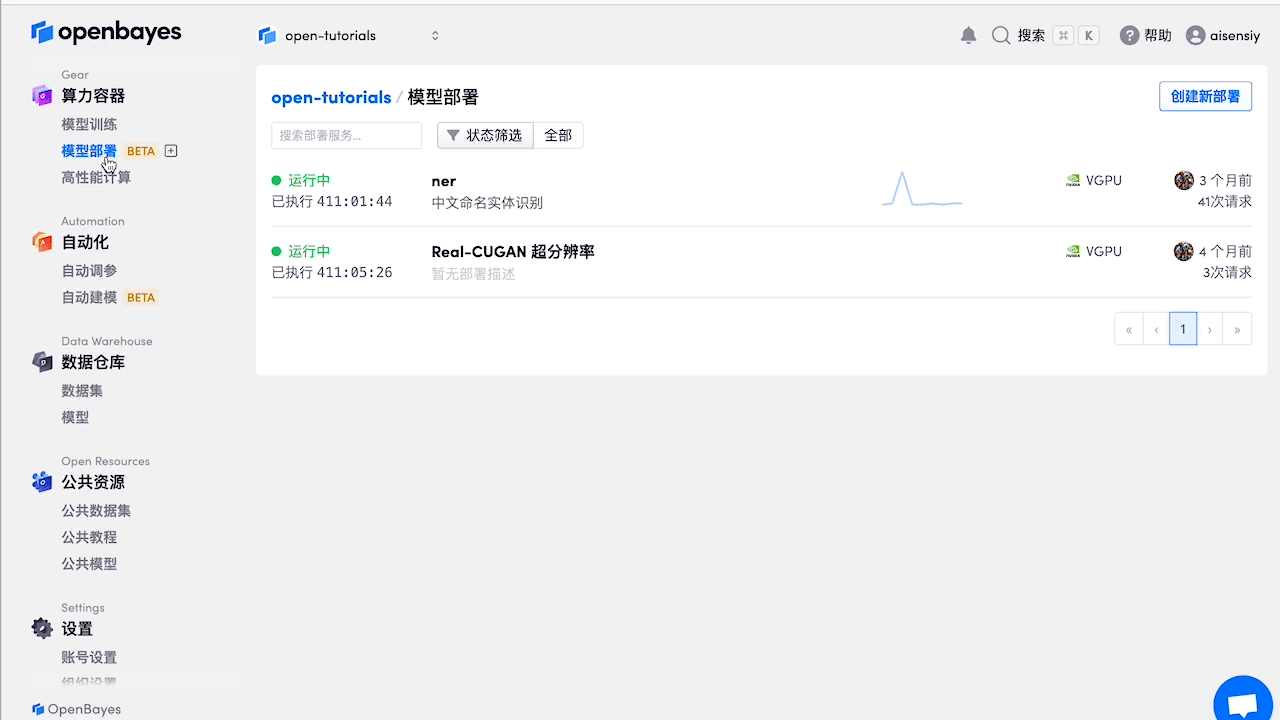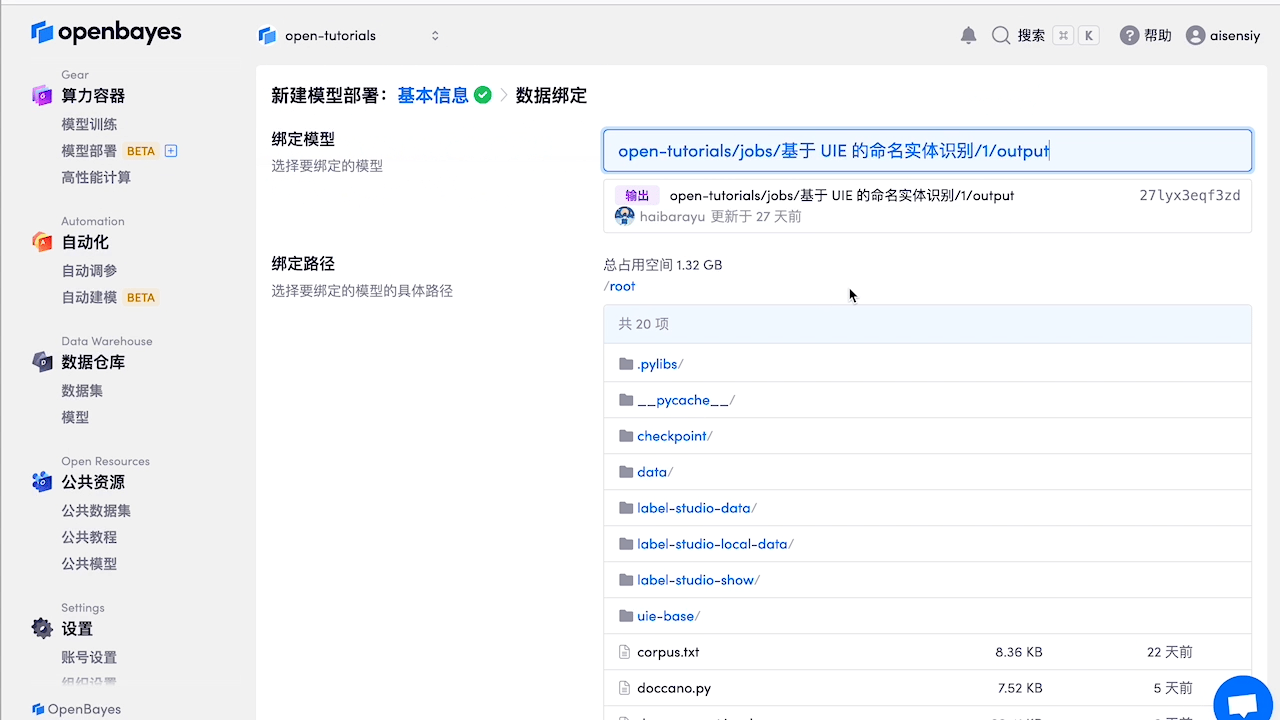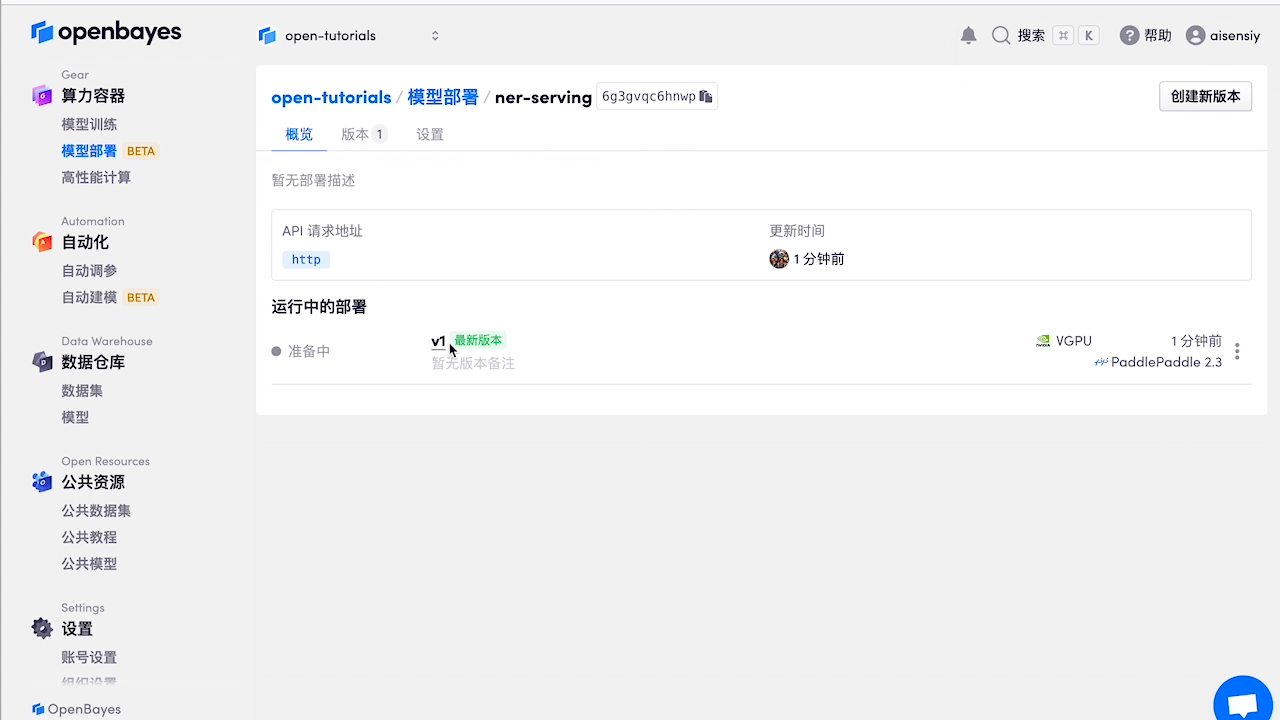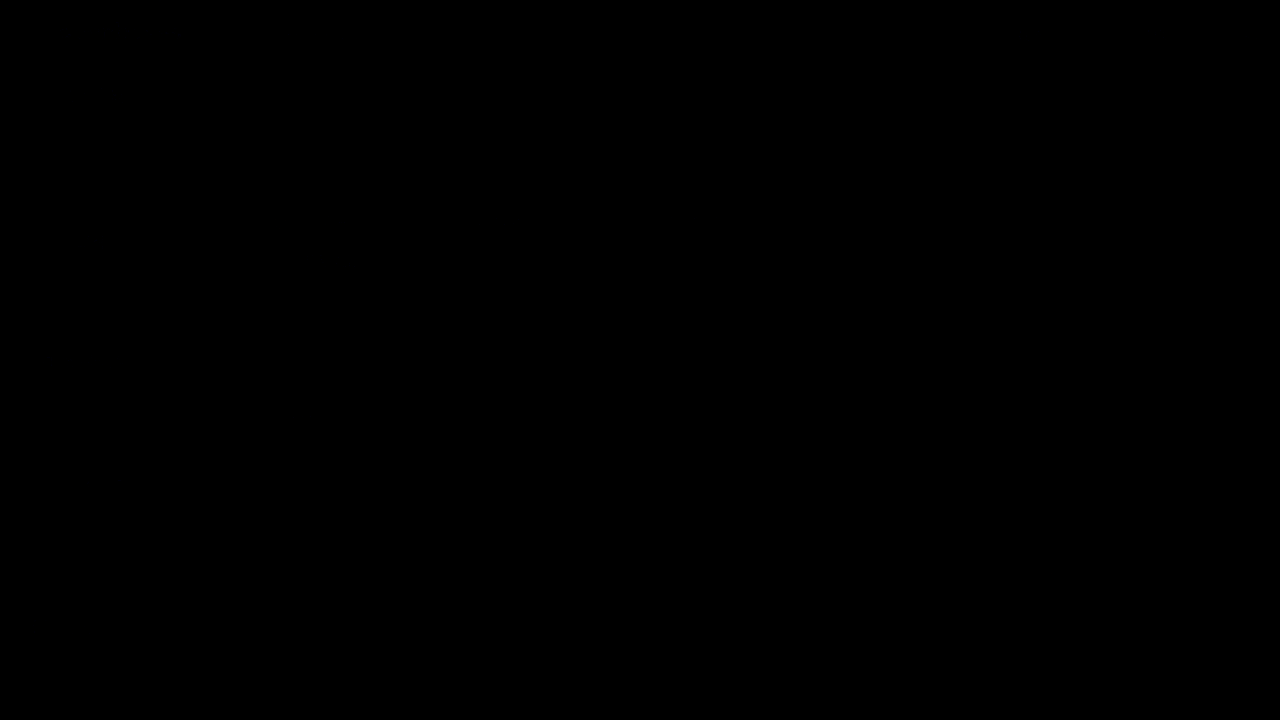
测试部署