0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
快速简洁
短短几行代码
,即可生成线上服务
根据 Serving 服务 `start.sh` 启动脚本模版只需要几行代码,即可完成一个自定义模型的在线推理服务逻辑。无需自己搭建复杂环境,可直接复用 OpenBayes 线上的训练环境镜像。效果 100% 复现

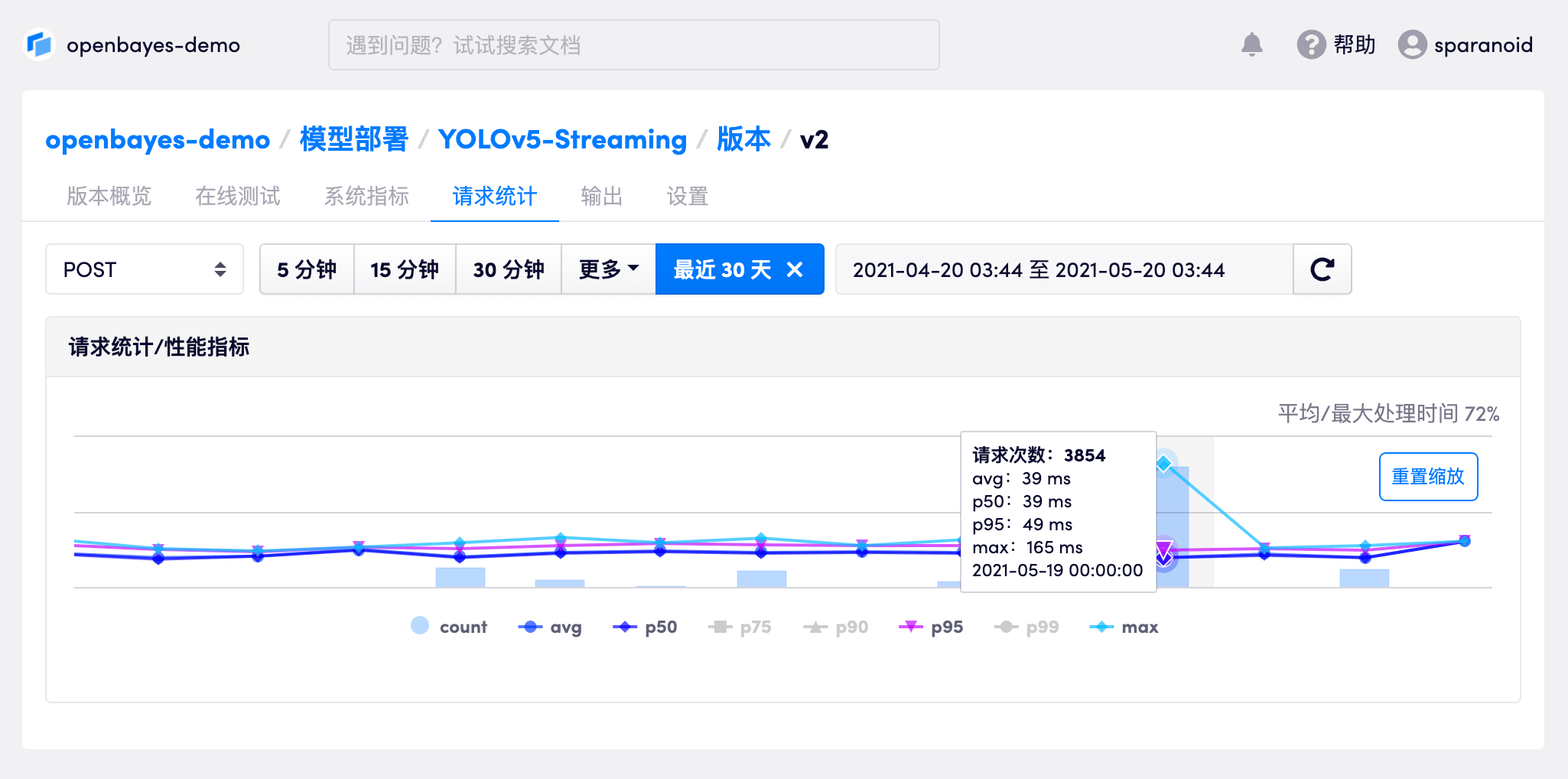
请求统计
内置请求统计
,直观查看性能指标
我们的 Serving 服务可对每次请求进行跟踪,保留完整的请求结果,方便追溯问题事件。
请求指标可以对请求的性能进行分析,还可按不同周期进行筛选。清晰查看性能走向。
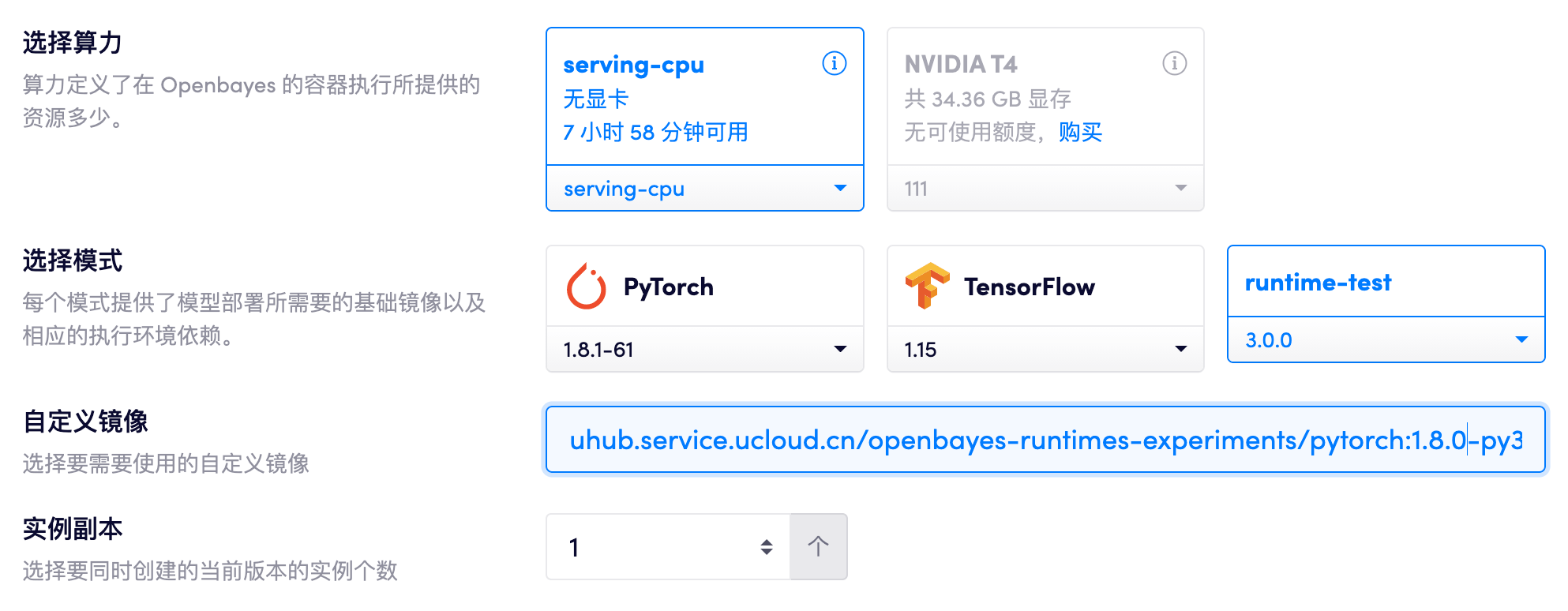
自定义镜像
灵活的环境控制
,满足企业定制化需求
私有部署可基于 Docker 创建并使用部署的自定义镜像,可更加灵活的控制部署环境,满足企业生产环境的定制化需求
多版本选择
模型版本控制
,不再为性能对比而发愁
基于 数据仓库 的模型版本控制,可在模型的不同版本之间进行切换,直观对比推理结果

多格式支持
支持主流框架
覆盖多数应用场景
高度灵活
通过
start.sh 启动脚本即可完成部署。针对高级用户,也可以在脚本中完全自定义启动流程与服务框架。多框架支持
兼容主流框架的模型格式。支持 PyTorch、XGBoost、TensorFlow 的多种模型文件保存方法
GPU 分片Enterprise-Only
私有部署可将物理 GPU 划分为多个虚拟 GPU,并保证计算资源与显存资源的隔离,大幅提升 GPU 利用效率,降低企业采购成本
平台定价方案
从入门级 CPU,
到专业级高性能 GPU 算力
我们提供了多种类型的算力租用方案,可满足不同算力需求、不同预算的用户