管理员操作手册
管理员角色有独立的管理界面方便对集群的用户、算力、镜像、容器等所有资源进行管理。对于管理员界面可以在右上角的下拉菜单中看到管理员界面的入口。
进入后可以看到如下的界面:
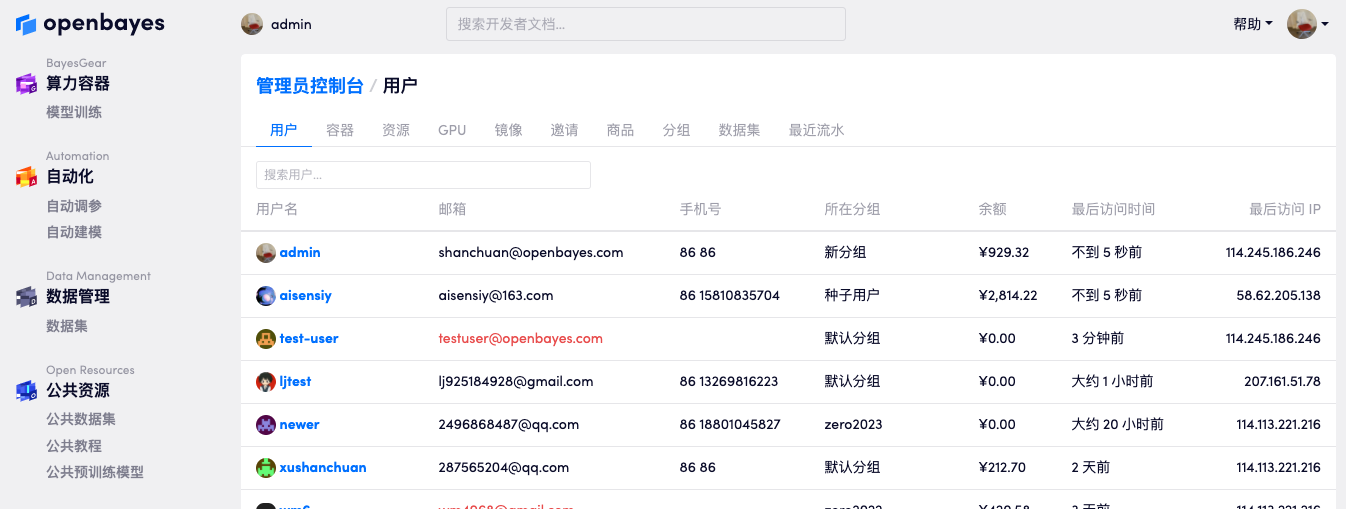
这里首先介绍常见的管理场景,后面我们将逐一介绍管理员的基本操作。
用户角色
OpenBayes 目前有三个用户角色:
- 普通用户
- 自动建模管理员
- 系统管理员
其中「普通用户」是默认角色,openbayes 系统下的所有用户都有这个角色;「自动建模管理员」是有自动建模模板的管理能力的用户,更多信息请参考 自动建模;「系统管理员」是有系统管理能力的用户,可以管理集群中的所有资源。
OpenBayes 系统默认有一个管理员账号,用户名为 admin,密码为 123。系统管理员可以在右上方设置中修改自己的密码。
修改用户角色
在管理员的「用户」管理页面中,可以看到所有用户的列表,点击任意一个用户可以查看该用户的详细信息,包括用户的基本信息、用户的资源、用户的并行限制等。其中也包含「用户角色」信息,点击「更新」可以修改用户的角色。
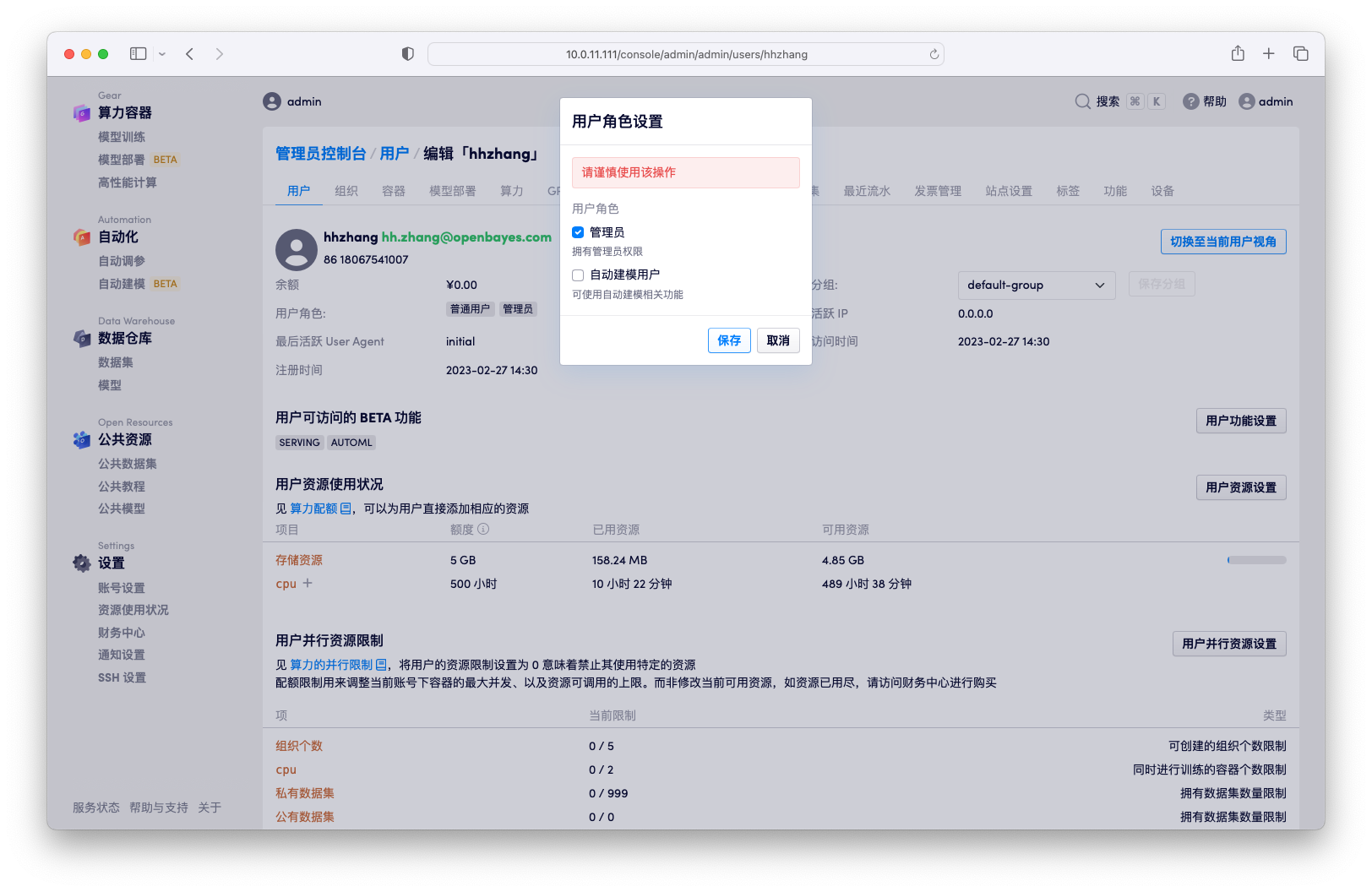
用户管理
用户的浏览和筛选
进入管理员界面后可以看到用户的列表页,展示了集群中所有的用户,通过搜索框可以按照 username email 或者手机号筛选用户。
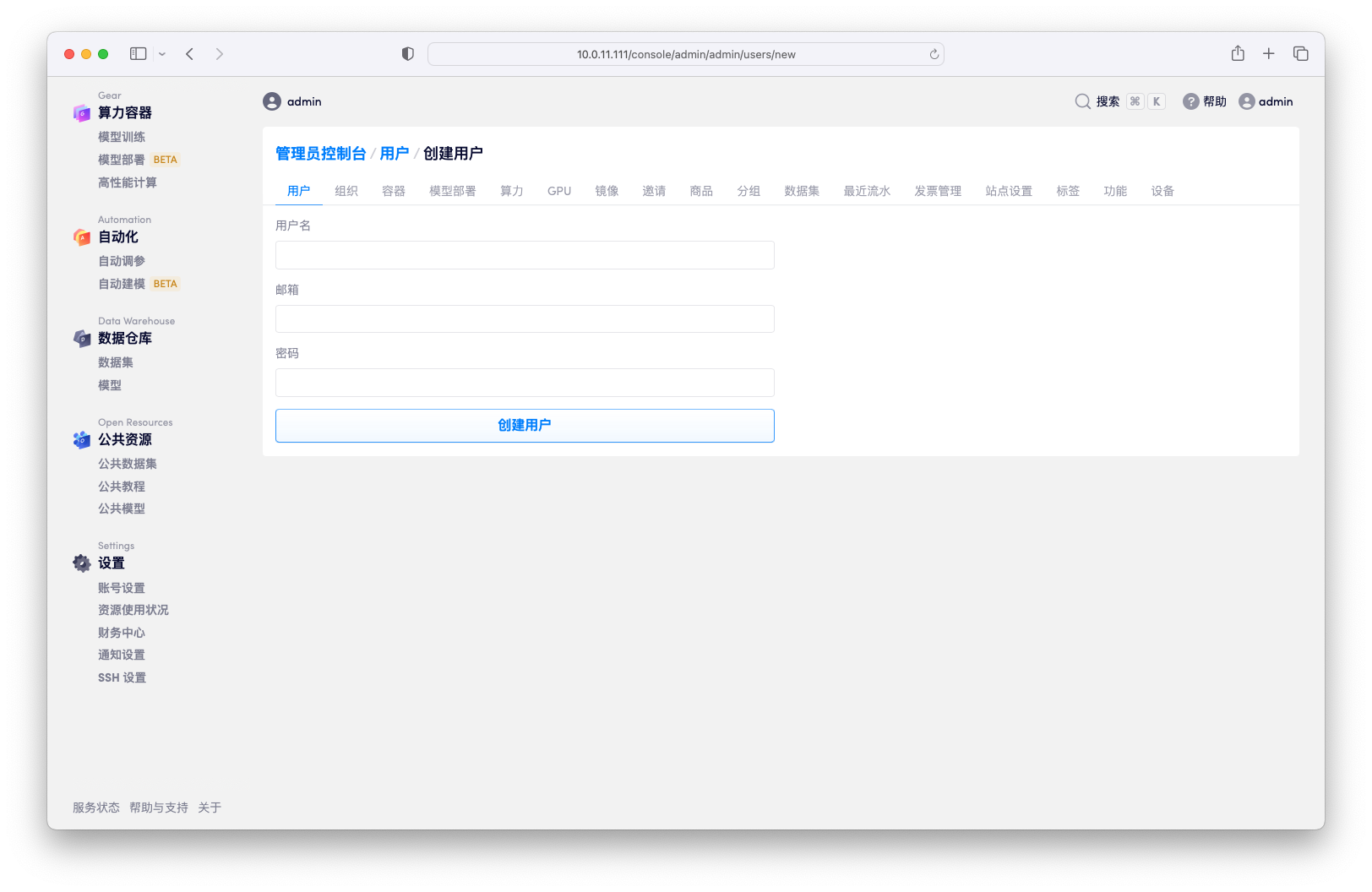
创建用户
点击界面下面的「创建新用户」管理员可以直接创建新的用户,创建成功后会自动发送邮箱验证邮件提醒用户验证邮箱并登录。
重置用户密码与锁定用户
系统管理员有权限干预异常或遗忘密码的用户账户。在用户列表中点击进入某个用户的详细信息页面:
- 重置密码:管理员可以强制修改指定用户的密码。
- 锁定用户:对于违规用户,管理员可以点击「锁定」,被锁定的用户将无法再登录系统和使用资源。
管理用户资源
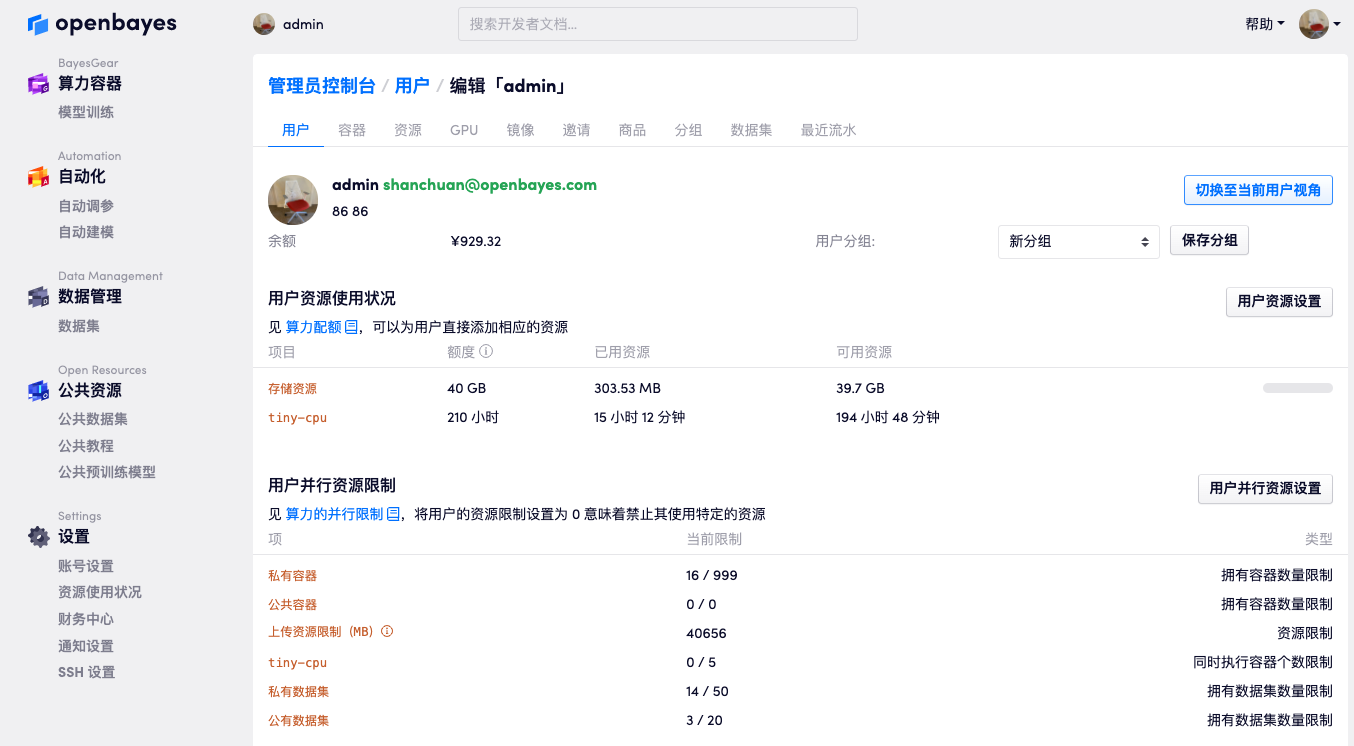
在用户浏览页面点击任意一个用户可以查看该用户的关键信息,包括「基本信息」「用户资源」「用户并行限制」。
从用户视角查看用户资源
在用户信息页面可以看到一个「切换至当前用户视角」点击后管理员会以该用户的视角查看用户的资源,左侧的「算力容器」「数据集管理」等导航链接将默认跳转至该用户的页面。此时管理员可以方便的查看该用户的相关资源。
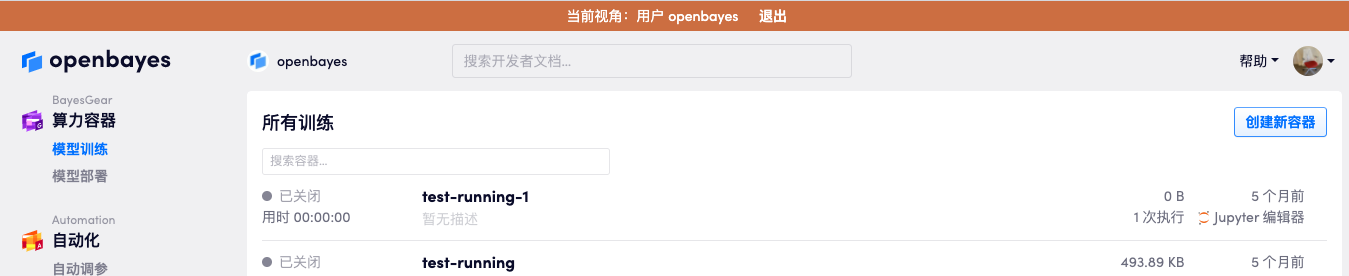
点击顶部提示条的「退出」将再次回到管理员视角。
查看并增加用户资源
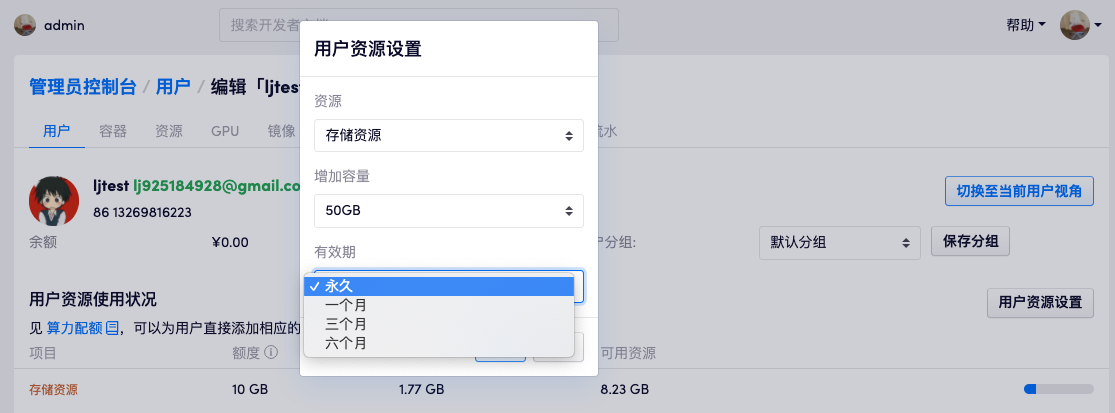
在「用户资源使用状况」部分可以看到用户目前的资源用量和余额,包括计算资源和存储资源。点击「用户资源设置」可以为用户增加计算资源或者是存储资源,并且选择这次增加的资源的有效时间。
资源的默认有效时间是「永久」,也可以选择「一个月」「三个月」这样的期限。这意味着该资源在此期间有效,对于计算资源在此期间使用是有效的,如果在此期间没有用尽,超过该时间范围后就不再能使用;对于存储资源在该有效期过后该用户的存储总量将减少至添加前的额度。例如用户默认的存储资源为 10GB,如果为用户增加有效期为三个月的 50GB 的存储,那么在此期间用户有 60GB 的存储空间;但是在三个月过后,用户的存储总量限制将会再次被调整至 10 GB。
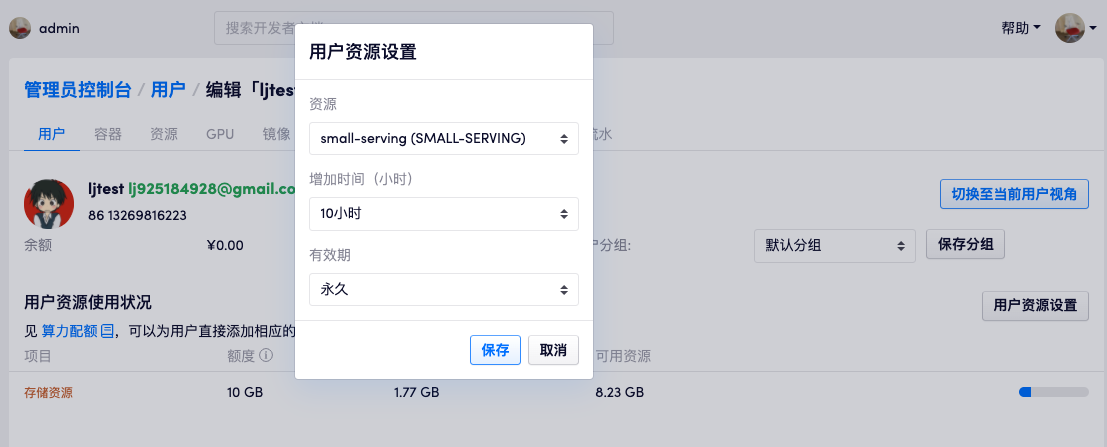
查看并更新用户的资源限制
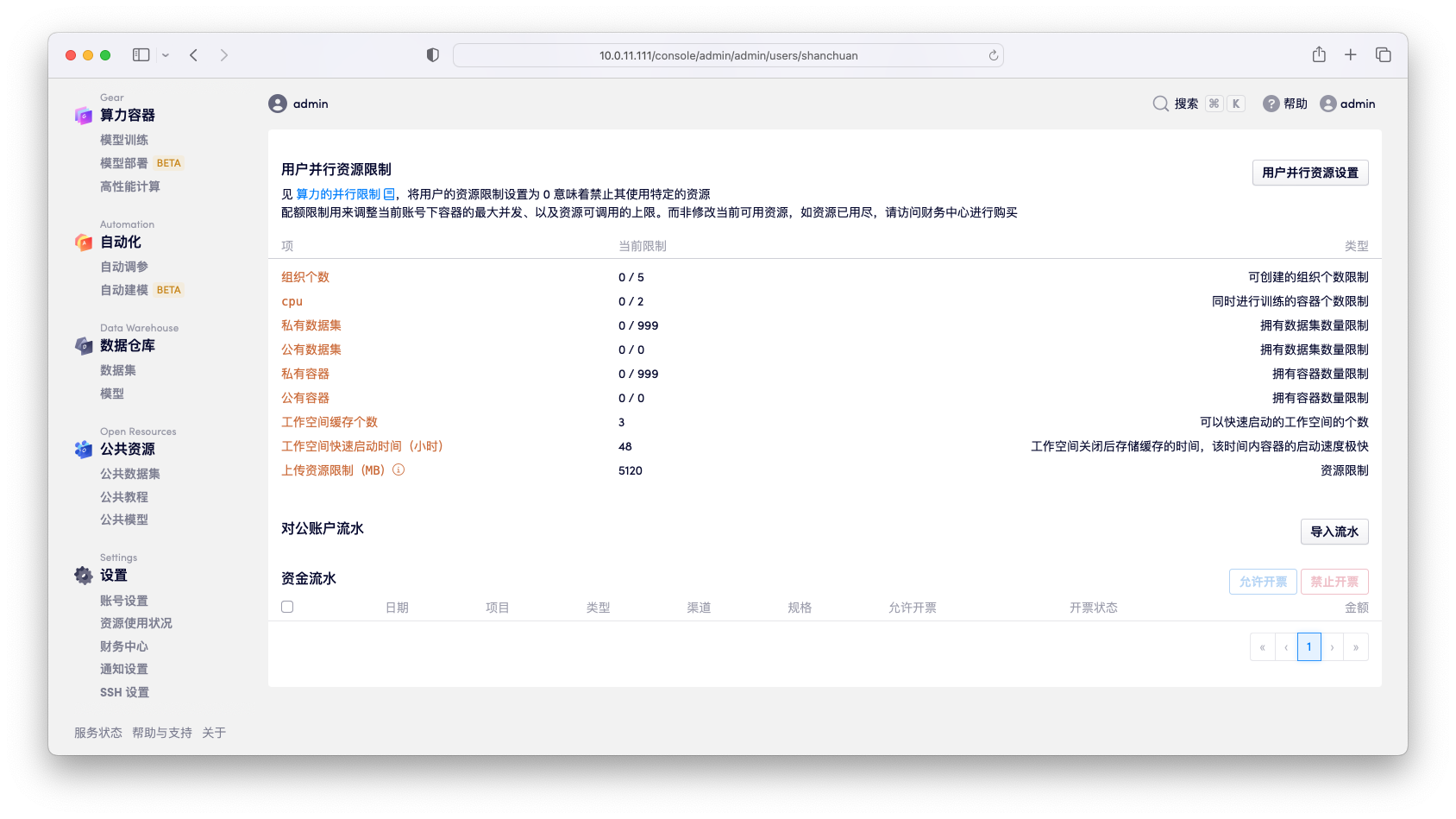
用户的资源限制包含如下几种:
- 不同算力类型容器的并行个数
- 容器的创建个数,包含公开容器 / 私有容器
- 数据仓库的创建个数,包含公开数据仓库 / 私有数据仓库
- 工作空间的缓存个数,是指可以用于快速启动的缓存容器的个数
- 工作空间的缓存时间,是指在工作空间关闭多久后会自动删除缓存
- 上传资源限制,是指用户一次性上传的数据的上限,由用户存储决定,管理员无法做调整
容器管理 & 数据集管理
管理员可以查看浏览集群内所有的容器,按照「状态」和「类型」筛选,可以方便的看到当前集群中处于不同状态的容器。
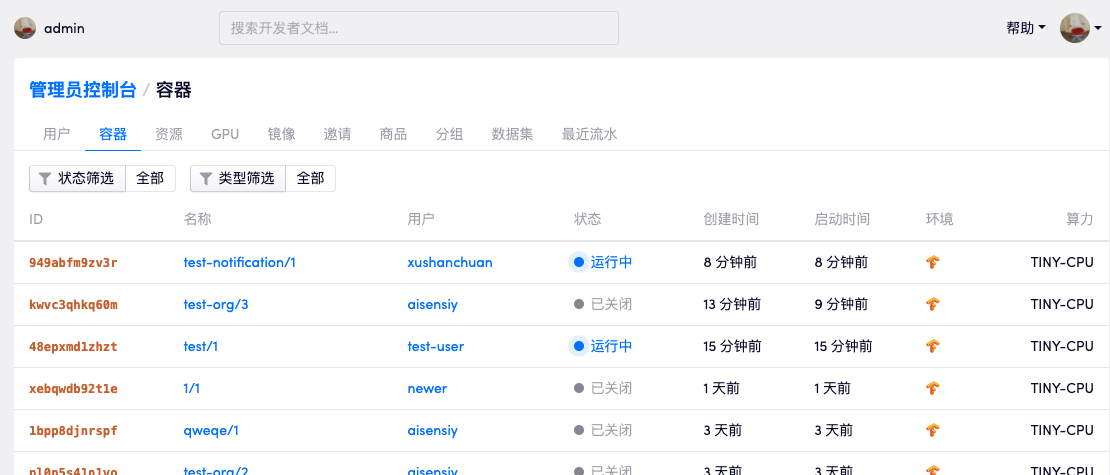
通过点击页面上的容器链接可以进入容器的详情页面查看容器的日志信息并有权限关停容器。
数据集管理和容器管理类似,这里不再赘述。
GPU
设置集群中不同类型 GPU 的总个数,这个个数必须小于等于实际集群中可用的 GPU 个数,大于实际个数会导致相应的资源无法成功运行。
算力资源管理
用户创建的容器时需要选择指定的「算力」,具体可以选择的「算力」由管理员创建和维护。每个算力需要定义 CPU、GPU、内存、存储四个维度。
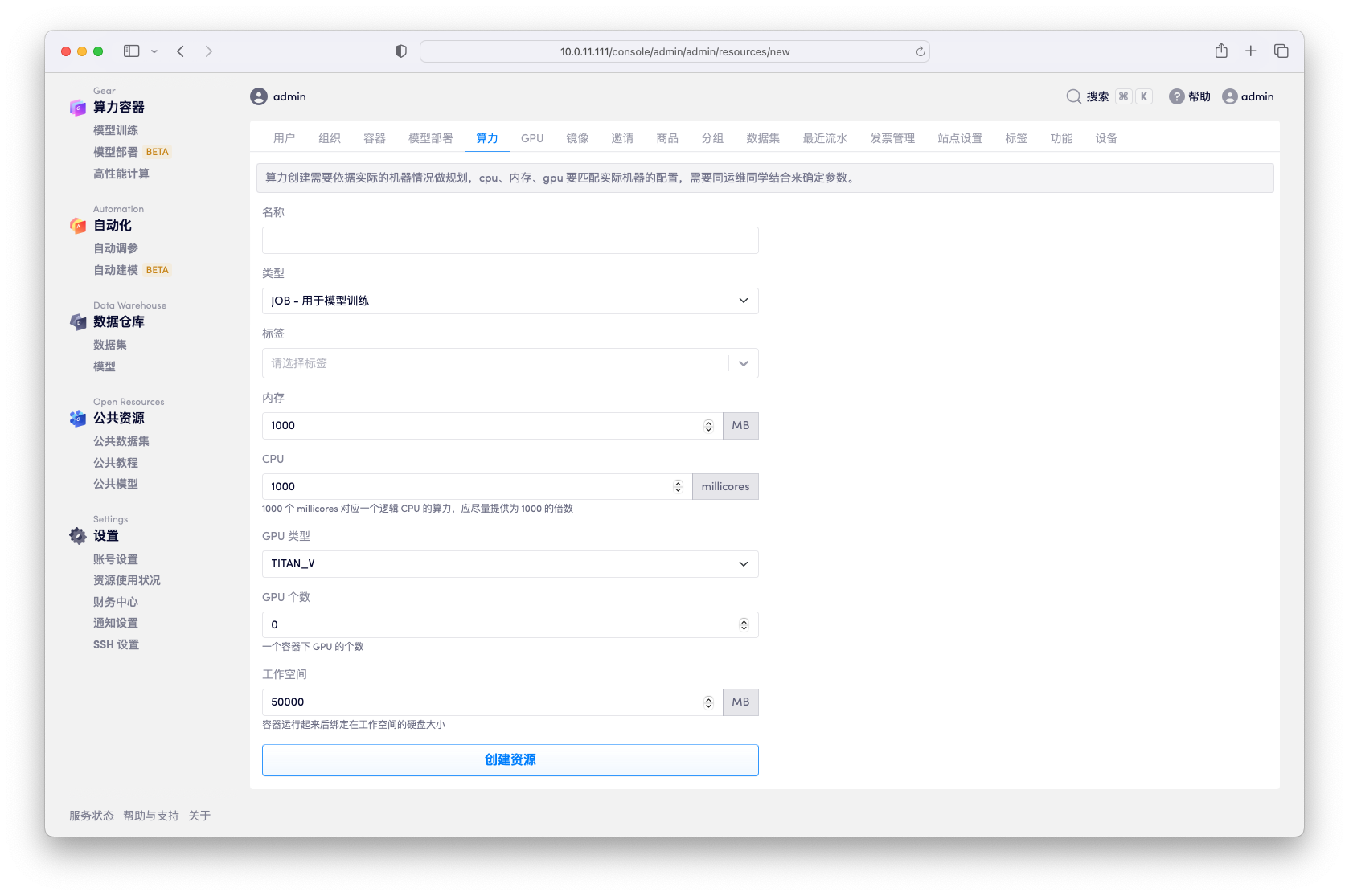
一个集群的算力总和是由集群的机器节点决定的,但是具体要对算力资源如何划分需要针对使用场景来具体分配,每个「算力」配置的太小无法满足用户的使用需求,每个「算力」配置的太大会导致少量用户占用过多资源,造成集群空置。
例如对于一个拥有 10 个 T4 类型 GPU 的计算集群来说,管理员可以依据需求将每两个 T4 类型的显卡绑定为一个算力资源构建成 5 个算力配额,这就意味着该集群可以最多同时运行 5 个这样类型的容器;也可以将每一个 T4 类型分配为一个资源构建成 10 个算力配额,这就意味着该集群可以同时运行 10 个这样类型的容器。
集群资源的分配一定要遵循实际情况,例如拥有 10 个 T4 GPU 的集群就不能创建 11 个单卡的容器,如果管理员分配了 11 个单卡资源,那么第 11 个容器将不能够被成功调度。
新创建的「算力」其总个数为 0,并且默认标记为「不可用」,需要管理员手动设置其总个数和标记为「可用」才能被用户使用。
节点绑定与隔离策略
在创建或编辑「算力资源」时,管理员可以将该资源绑定到指定的 k8s 节点,并为这些节点配置隔离策略。两个设置共同决定这批节点的调度行为和空闲数量计算方式。
节点绑定
将资源绑定到指定节点后,该资源下提交的 Job/Serving 会被附加 node affinity(requiredDuringSchedulingIgnoredDuringExecution),确保只调度到这些节点上运行。节点绑定本身不影响其他资源是否可以使用这些节点,这由隔离策略决定。
隔离策略
隔离策略控制其他资源的 Pod 与这些节点的关系:
| 隔离策略 | k8s 机制 | 其他资源的 Pod 能否调度到这些节点 | 节点是否从全局资源池排除 |
|---|---|---|---|
| 不隔离 | 无额外约束 | 能,无任何限制 | 否 |
| 软隔离 | preferredDuringSchedulingIgnoredDuringExecution(weight: 1) | 调度器倾向于避开,但资源紧张时仍可调度 | 否 |
| 硬隔离 | requiredDuringSchedulingIgnoredDuringExecution(DoesNotExist) | 否,k8s 层面硬性禁止 | 是 |
管理员容易误以为「绑定节点」等同于「独占节点」,但实际上只有同时设置硬隔离才能真正独占。
只绑定节点、使用不隔离或软隔离时,存在以下问题:
- 资源争抢:其他资源的 Job 可以(不隔离)或在资源紧张时仍然可以(软隔离)调度到这些节点,与绑定资源的 Job 竞争同一批 GPU;
- 空闲数量高估:绑定资源的空闲数量计算只统计已被 operator 回写了节点信息的 Job。处于创建中、尚未分配节点的 Job 不会被计入占用,高并发提交时存在超分配窗口;
- 全局池未隔离:非硬隔离的节点不会从全局资源池中排除,其他资源依然可以将 Job 调度到这些节点。
如果希望某批节点被某个资源专属独占,必须同时:
- 将节点绑定到该资源
- 将隔离策略设置为硬隔离
三种策略的行为对比:
| 不隔离 | 软隔离 | 硬隔离 | |
|---|---|---|---|
| 其他资源能否调度到绑定节点 | 能 | 能(资源紧张时) | 否 |
| 绑定节点从全局资源池排除 | 否 | 否 | 是 |
| 绑定资源空闲数量准确性 | 低 | 低 | 高 |
| GPU 超分配风险 | 高 | 中 | 无 |
镜像管理
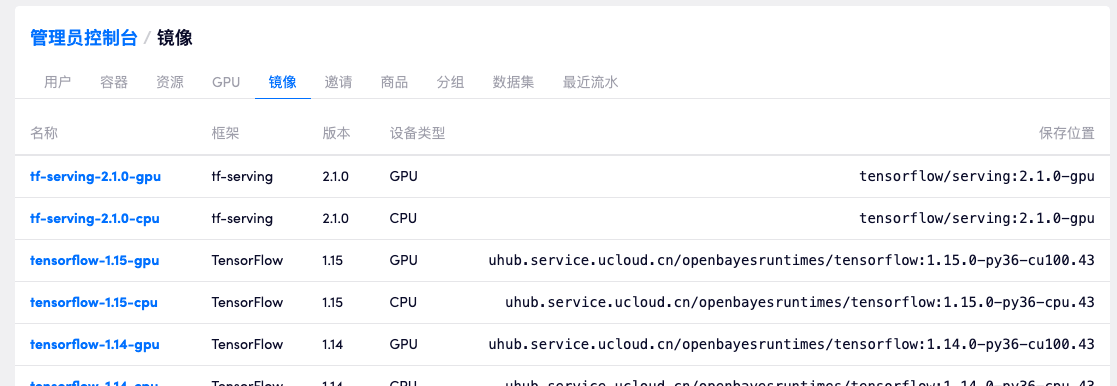
镜像提供了用户所需要的基本软件配置。例如在机器学习方面 OpenBayes 提供了 TensorFlow、PyTorch、MxNet 的 CPU 和 GPU 环境下不同版本的镜像。管理员也可以依据自身需要增加自定义的镜像。
自定义镜像
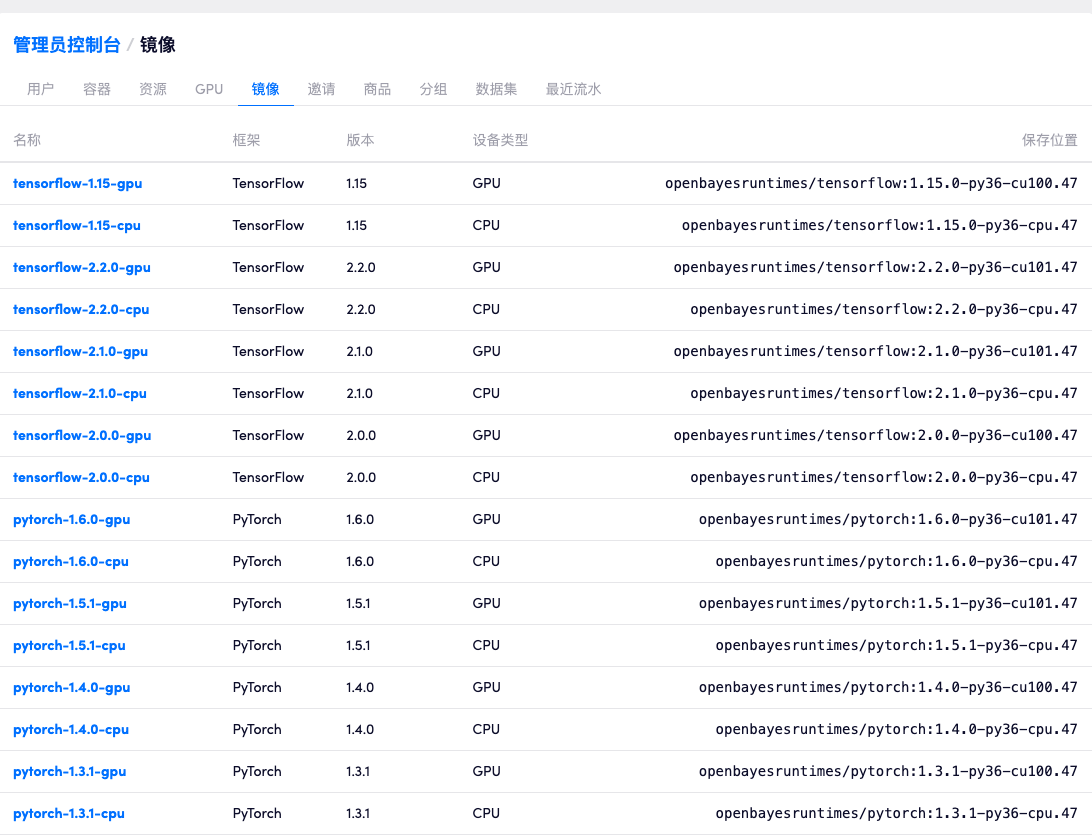
如上图所示,在「管理员控制台」 - 「镜像」 页面展示了每一个运行时镜像的名称、对应框架、支持设备类型以及所报错的镜像位置。
系统初始化时只有系统预置镜像,无法被删除:
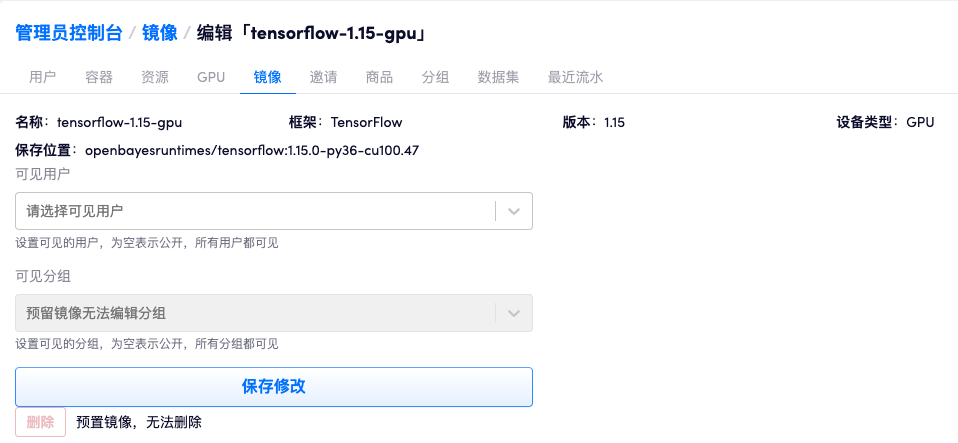
如果需要增加额外的自定义镜像,其镜像必须从预置镜像进行构建。在 运行时环境 下可以看到所有镜像的依赖情况。
例如如果需要在 PyTorch-1.6.0 的基础上增加一些额外的自定义依赖可以指定如下的 Dockerfile:
FROM uhub.service.ucloud.cn/openbayesruntimes/pytorch:1.6.0-py36-cu101.47
RUN conda install seaborn
然后执行以下操作构建并推送镜像到镜像仓库:
docker build . -t <your-registry>/<your-image-name>:<your-tag>
docker push <your-registry>/<your-image-name>:<your-tag>
创建自定义镜像时有以下几点需要特别注意:
- 由于 OpenBayes 容器的启动依赖于预置镜像中一些通用的配置和依赖,自定义镜像必须在原有的 OpenBayes 的预置镜像上构建,否则可能出现容器无法启动的情况。
- 在 运行时环境 的容器列表下可以看到,对于同一个框架、同一个版本需要提供
cpu与gpu的镜像,那么添加自定义镜像时通常需要添加支持cpu和gpu的一对镜像,这样才能保证两种算力资源下都能够启动该镜像,缺少相应设备的镜像时会导致创建对应算力资源下的容器时报错。 - 确保所提供的镜像为集群可以访问到的,推荐使用对应内网的镜像仓库
添加新镜像
构建完成后可以在 「镜像」 - 「创建新镜像」 这里配置相应的名称以及镜像读取的位置:
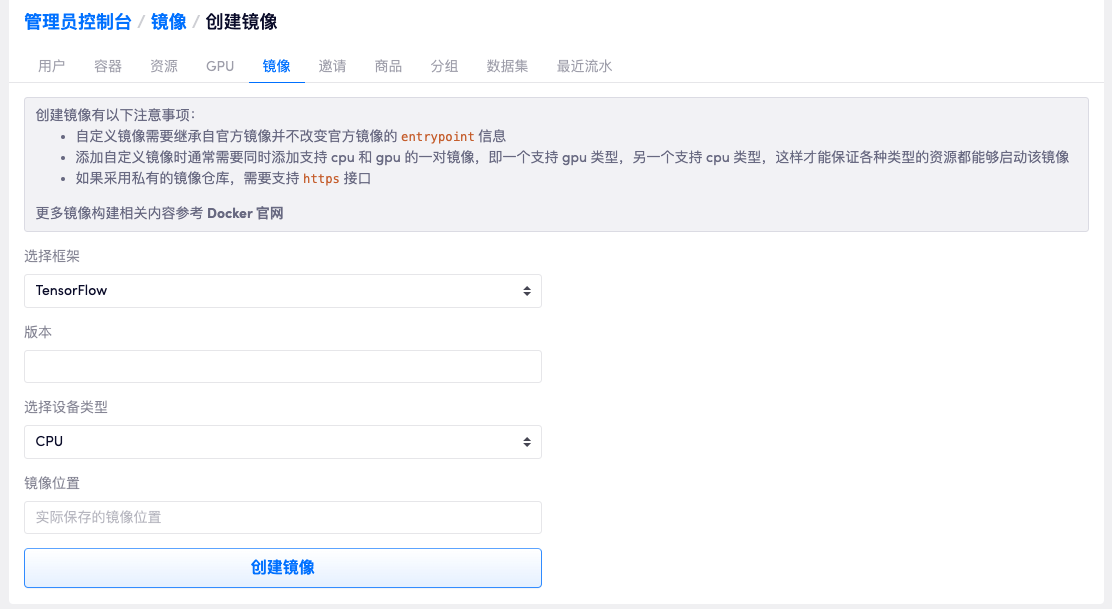
之后在创建容器时就可以选择这个自定义镜像了。
邀请
用于管理注册用户,对于私有集群来说主要是方便各个部门的人员管理。
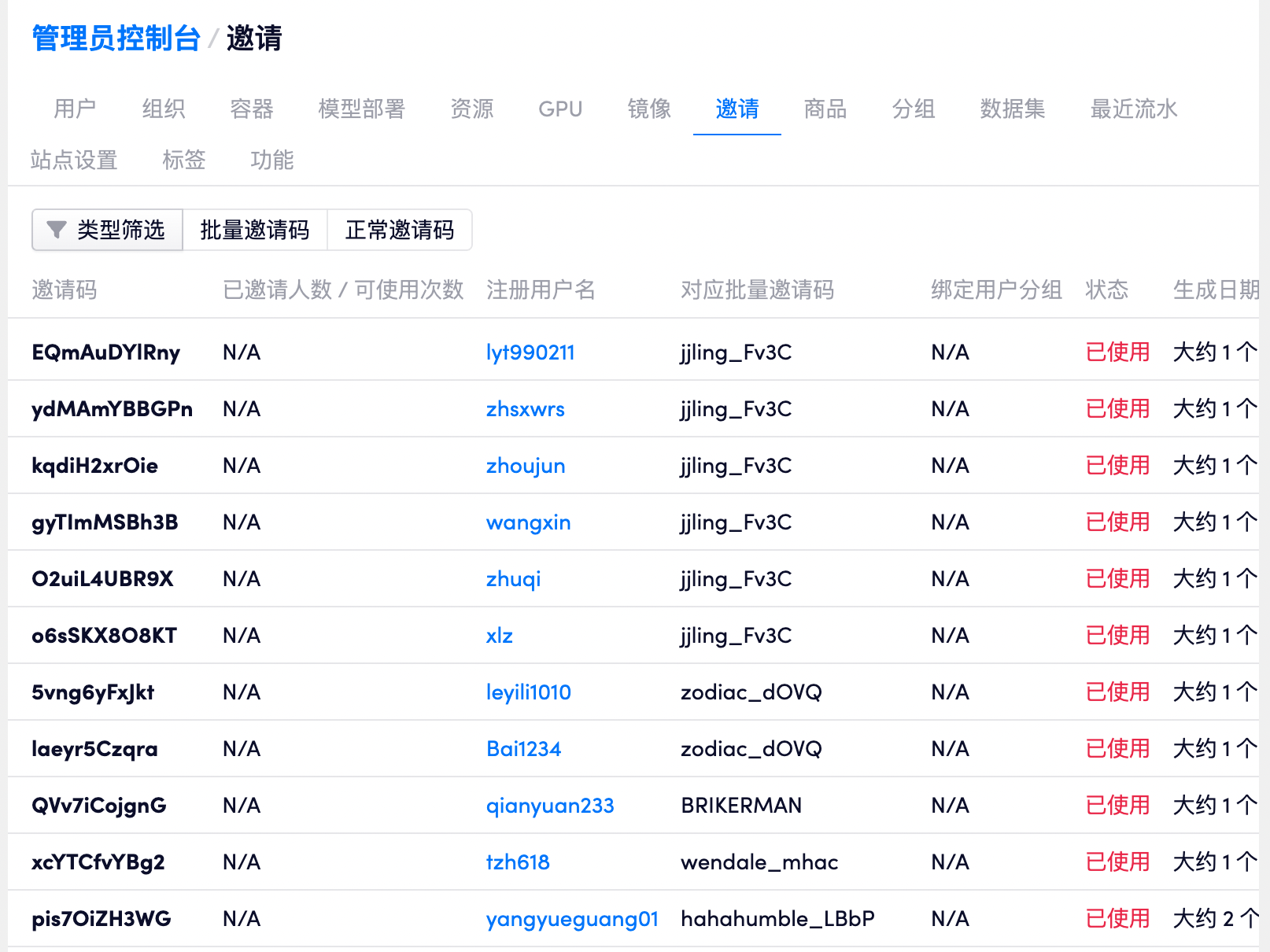
批量邀请码
「批量邀请码」有如下功能:
- 设置邀请码的可用次数,即使用该邀请码可以注册的用户的上限。
- 设置使用该邀请码注册的用户所加入的分组,如果没有设置则加入默认分组。
- 设置通过该邀请码注册的用户立即获取的资源,包括计算资源和存储资源。
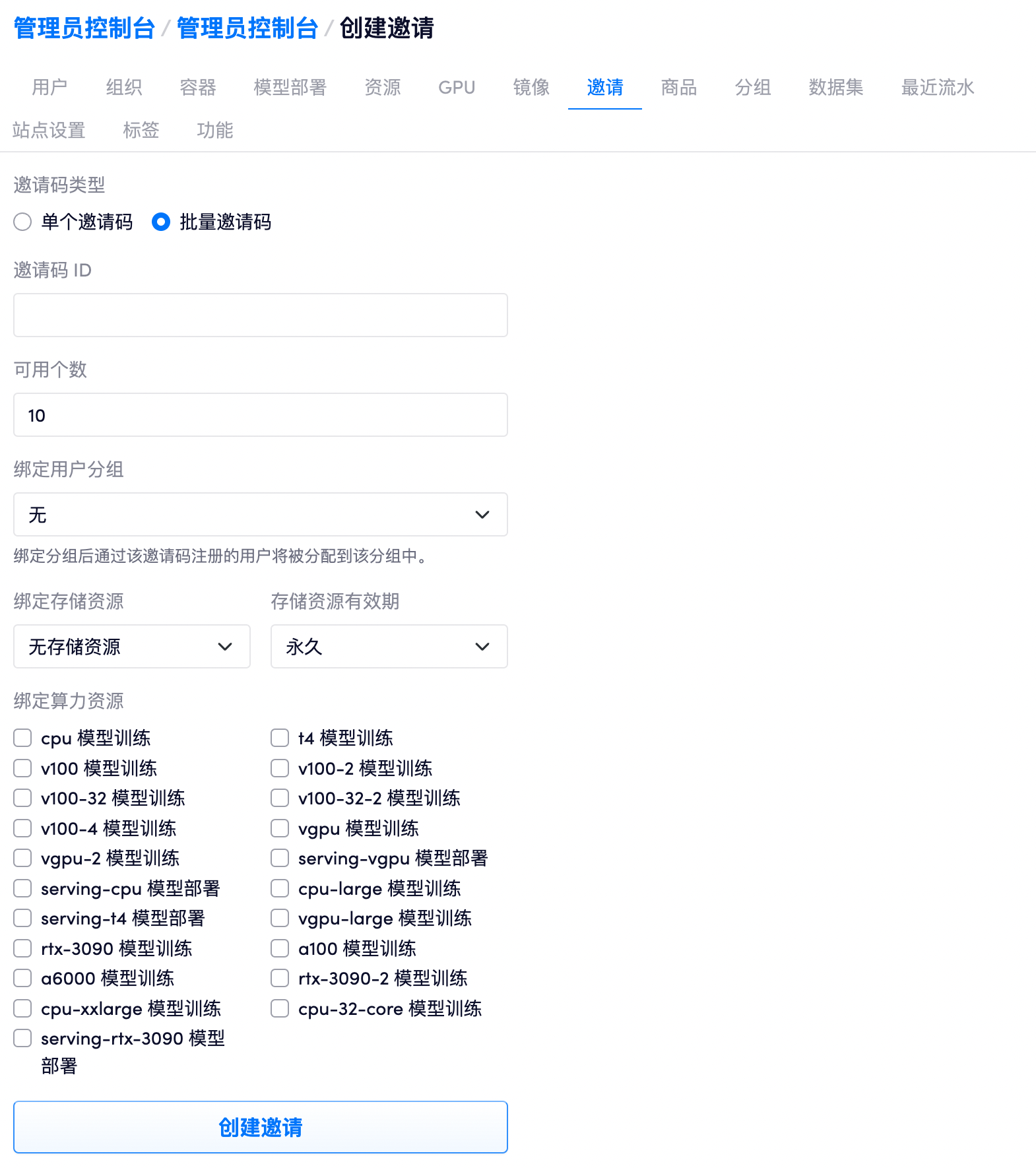
例如可以给通过邀请码注册的用户提供 10 小时 A100 类型资源和 20 小时 rtx-3090 类型的资源:

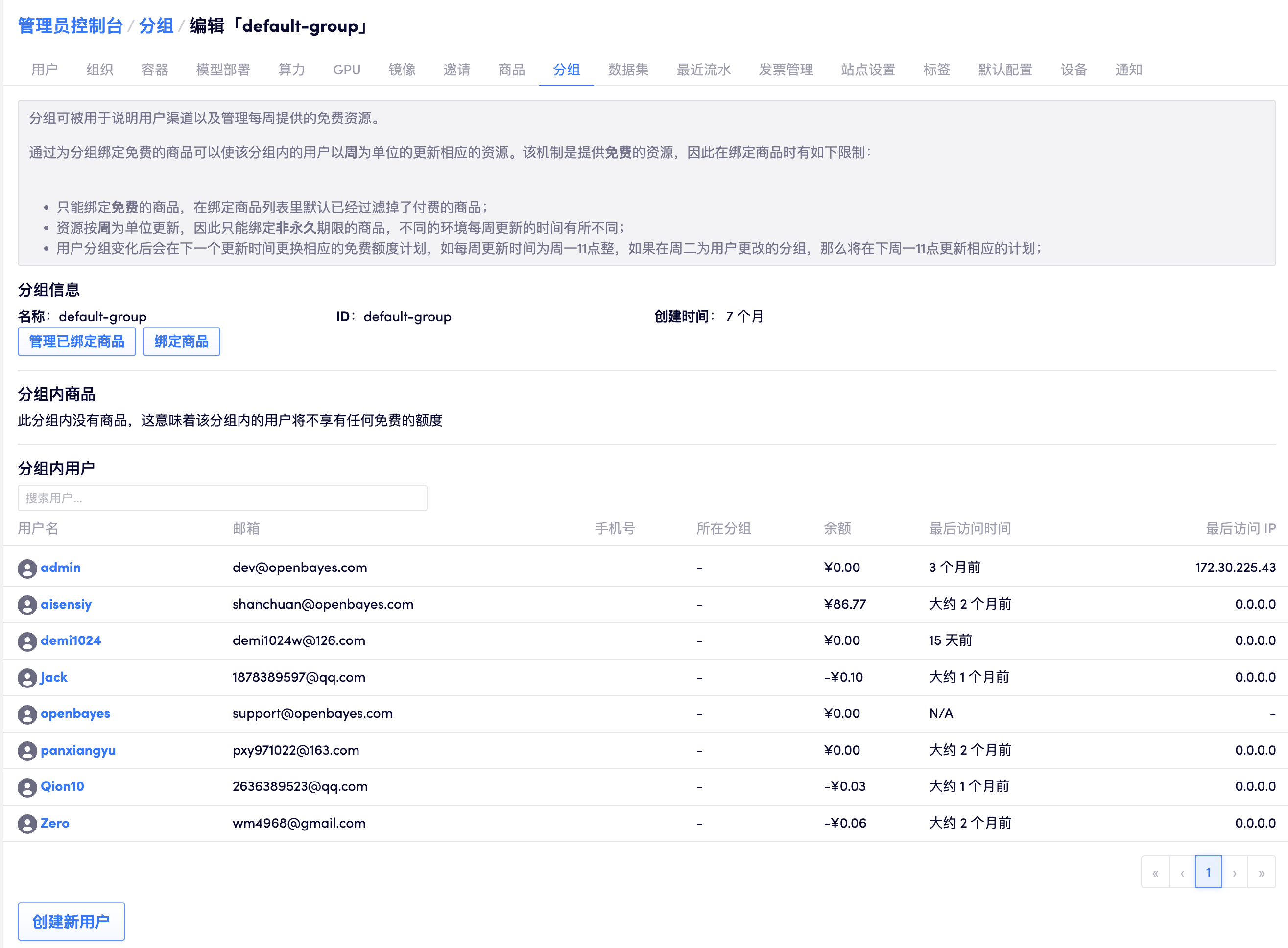
分组
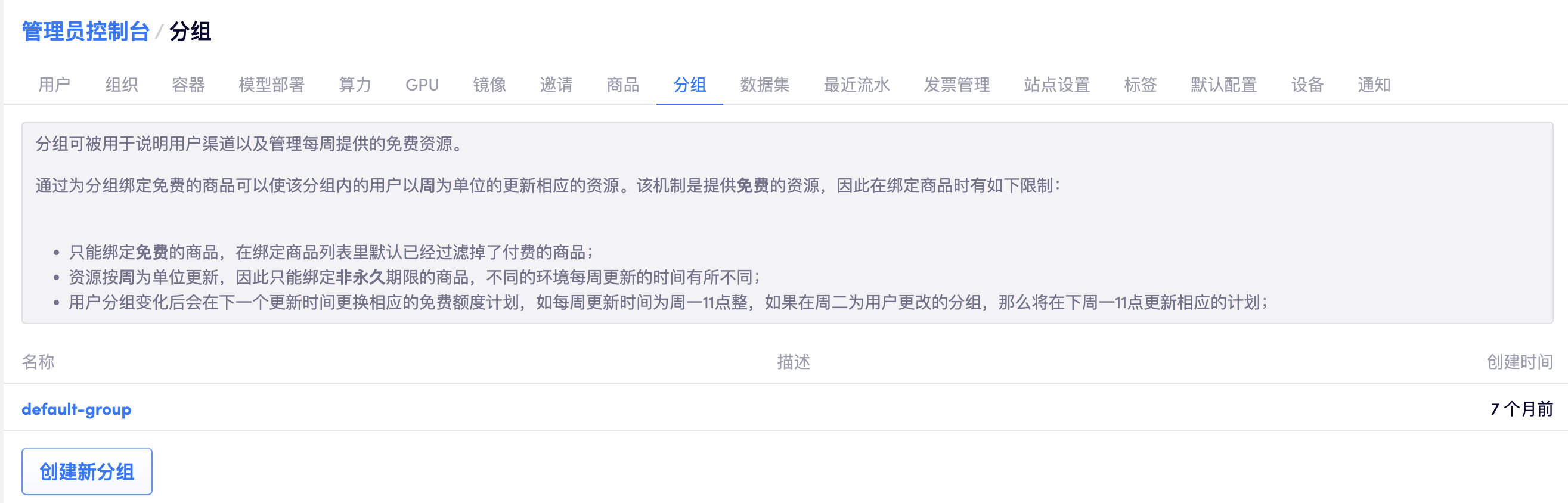
分组的主要用途有如下两个:
- 在注册时绑定分组以区分不同渠道过来的用户,方便按照部门、实验室等进行管理;
- 为分组绑定免费的商品,使得该分组下的用户可以以周为单位的更新相应的资源,这部分见 创建周期性供给计划;
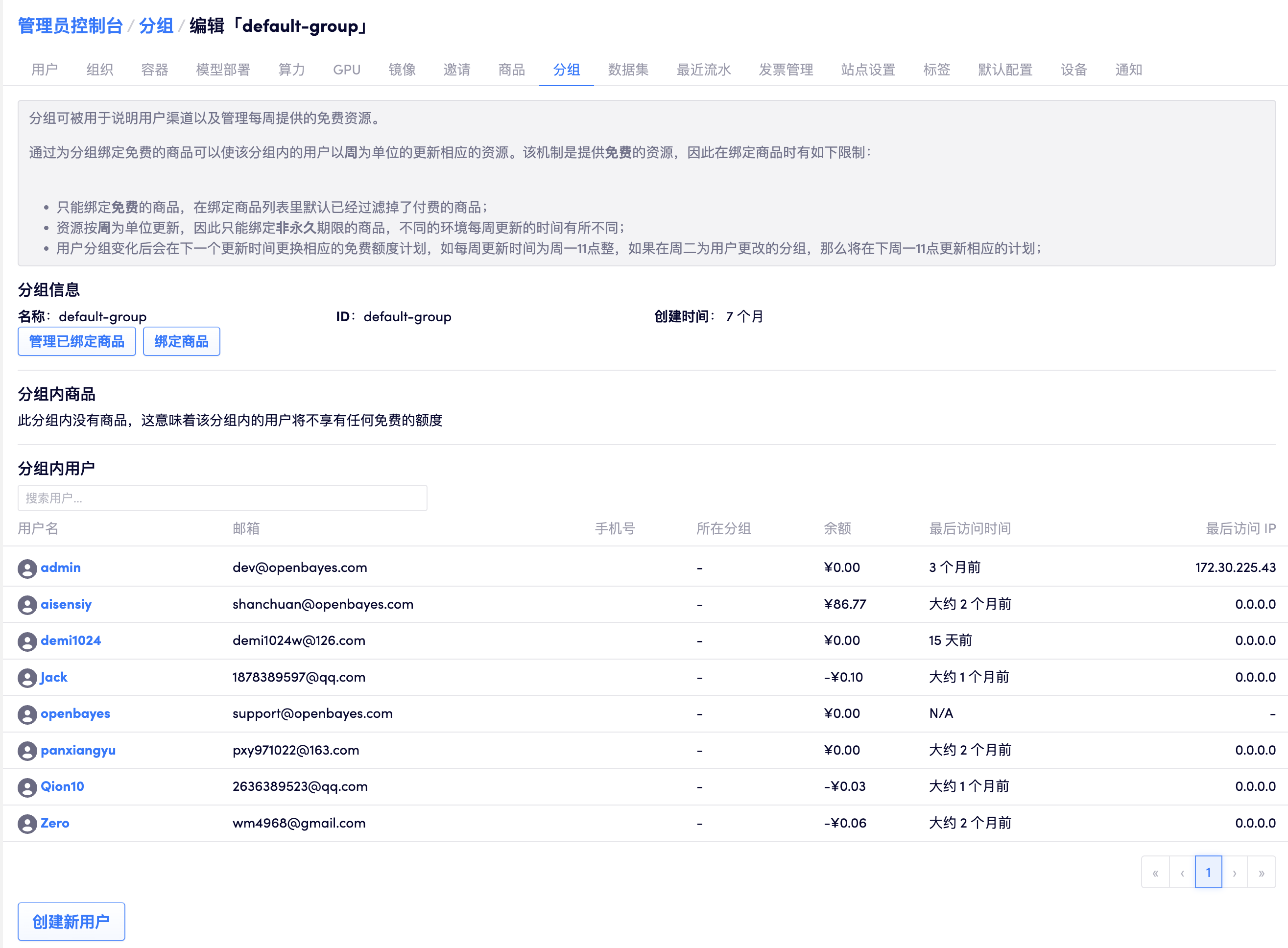
用户会被默认加入到 default 分组中
修改用户的分组
用户的分组管理员可以在个人管理页面进行修改:
周期性供给计划
OpenBayes 为了避免计算资源尽量以比较均匀的方式被使用,提供了周期性供给计划的功能。
- 管理员可以将一个「商品」设置为免费并标记其有效期为一个星期。
- 将这个「商品」绑定一个「分组」下
每周固定时间 OpenBayes 会将这个「商品」的资源分配给「分组」下的所有用户。
举一个例子:
- 管理员创建了一个 50 小时的 cpu 类型的计算资源的商品,将其设置为免费并标记其有效期为一个星期,名为 free-cpu-50h
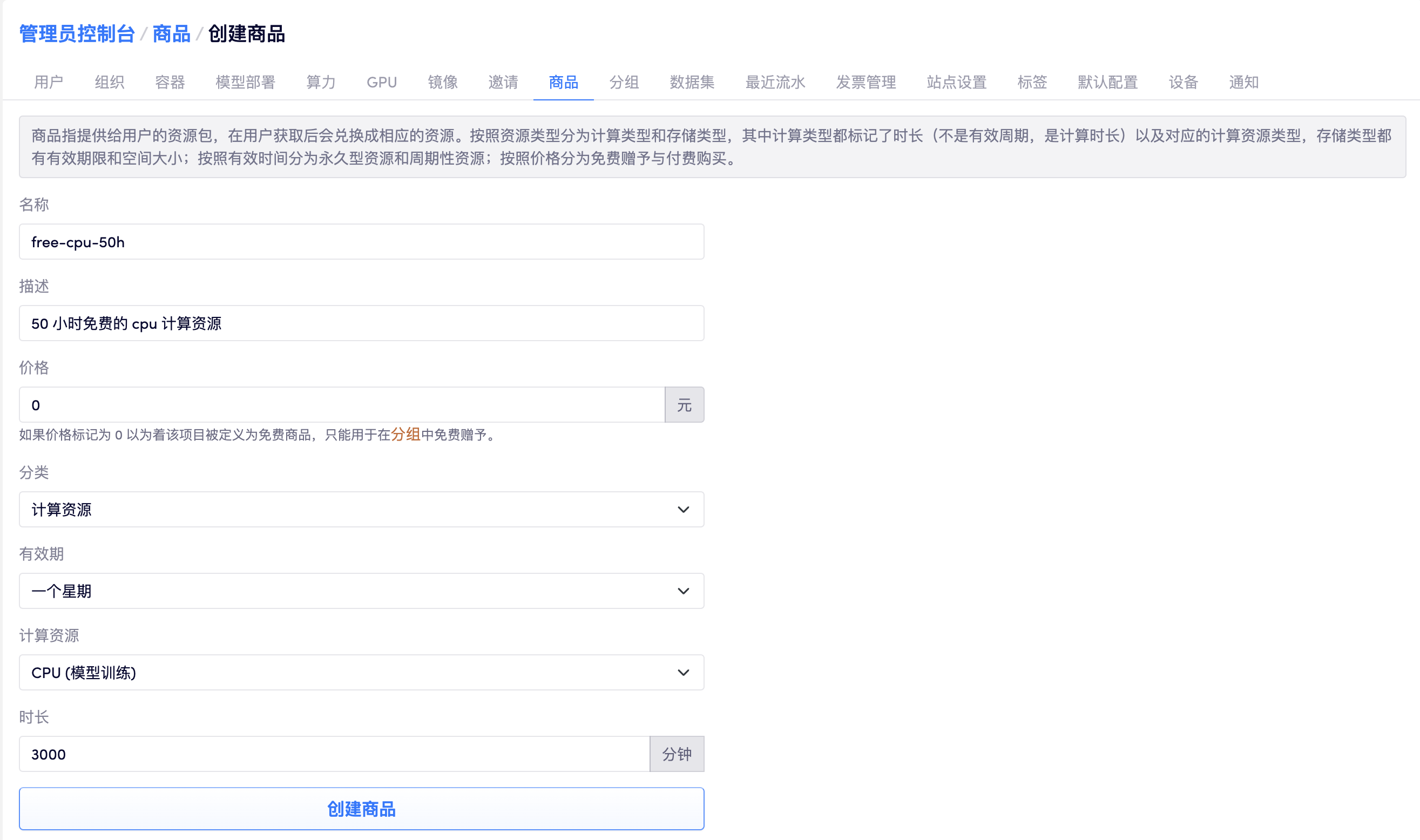
- 管理员将这个商品绑定到分组 xx 中

每周一的早晨,xx 分组下的所有用户都会获取到 50 小时的 cpu 类型的计算资源。但是这个计算资源的有效期只有一个星期,那么到了下周一,这个资源就会被回收。也就是说,如果这个星期,xx 分组下的用户没有使用完这 50 小时的资源,那么这 50 小时的资源就会被浪费掉。不会因为用户每周获取计算资源而不断积累。
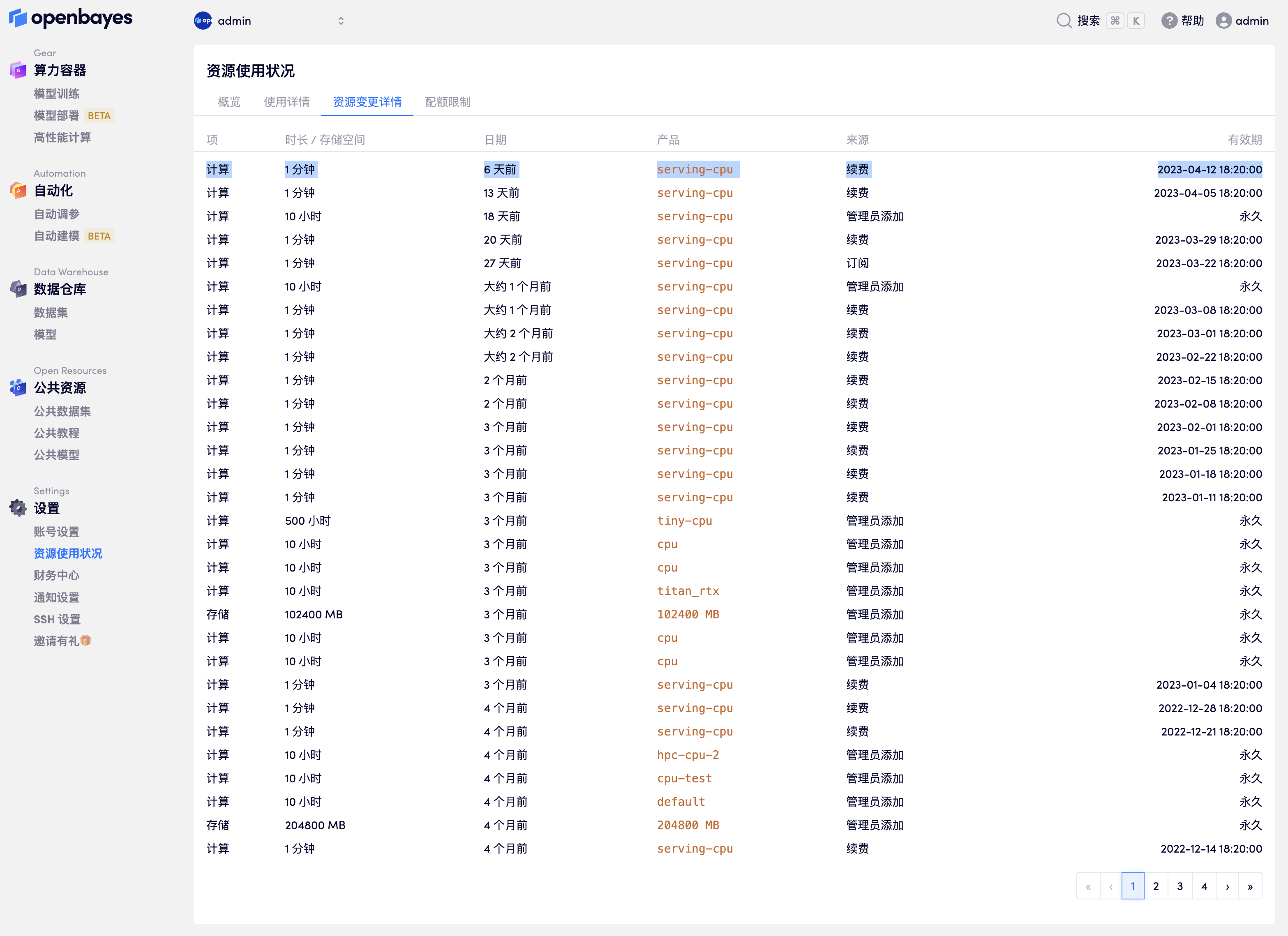
- 查看有失效的计算资源
在用户的「资源使用状况」-「资源变更详情」中可以看到带有效期的计算资源:
- 这里的「商品」是一个比较通用的说法,对于私有部署用户来说,更确切的说法是「计划」主要是针对周期性的资源供给,因此这里的「周期性供给商品」也可以理解为「周期性供给计划」;
- 默认集群内周期性供给计划的更新时间为每周一的早晨八点;
- 在第一次创建了周期性供给计划后其生效期为下一个周期,即下周一的早晨八点;
修改周期性供给计划
在「分组」的详情页面可以看到绑定的周期性供给计划:
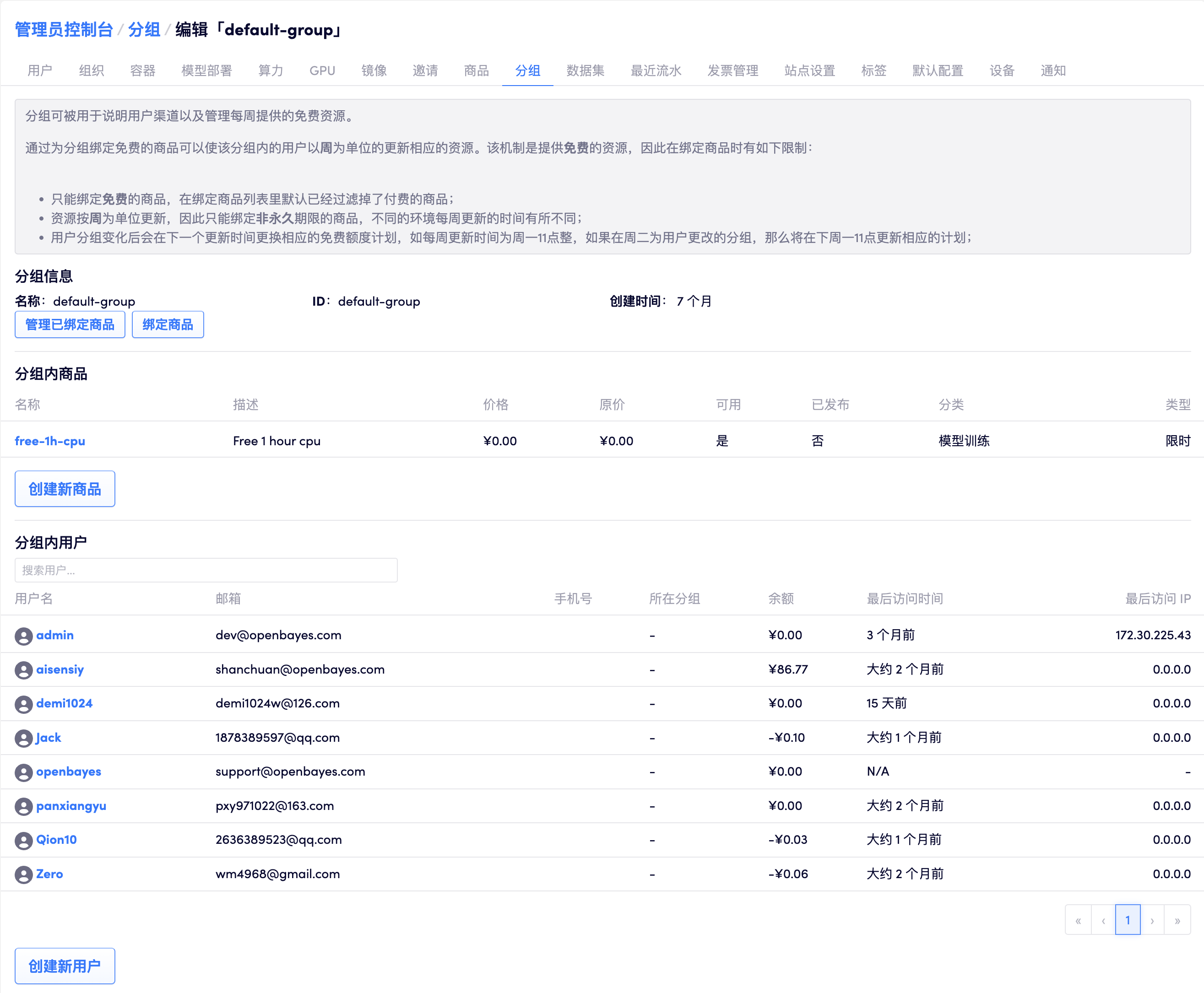
在这里可以删除不再需要的周期性供给计划:

也可以添加新的周期性供给计划:
所有的修改都将在下一个周期生效。
组织 (Org) 管理
组织 (Org) 是一种比分组 (Group) 具有更高维度的实体团队。组织内部的日常维护(如成员增减、资源划分)通常由组织自身的管理员(Owner)完成。系统管理员主要从宏观层面进行控制:
- 组织创建权限:系统管理员可以管理并授权特定用户,使其拥有创建组织(Org)的权限。
- 分配席位:系统管理员负责为组织设置与调整总席位数量,限制该组织可以容纳的最大用户规模。
- 最高权限介入(可选):在必要时,系统管理员凭借最高权限,依然可以随时直接介入任意组织的内部管理或干预资源分配。