算力容器介绍
容器的执行模型
算力容器作为一个计算单元,可以执行各种各样的计算工作,包括数据预处理,机器学习模型的训练,利用已有模型对未标注数据进行推理等,其构成包含以下几个重要元素:
- 基本的硬件配置,目前包括 CPU、GPU、内存、存储四大元素,通过算力类型指定。
- 基本的运行时环境,主要就是选择想要采用的深度学习框架以及其配套的周边依赖,通过镜像指定,具体的依赖列表参见运行时环境。
- 所需要的代码、数据,通过绑定数据、绑定其他容器执行的「工作目录」或者直接上传代码提供。
容器每次的执行都会重新分配存储并将存放在这次执行容器中的数据保存下来,因此每个容器下的各个执行是相互独立的,结合自定义参数和Parameters 等工具,如果使用得当可以大大提升机器学习实验的可复现性。但如果没有对这些概念有很好的了解可能会导致数据在各个执行之间来回复制,既拖慢了容器运行的速度也大大增加了额外的非必要数据存储开销。
容器的创建
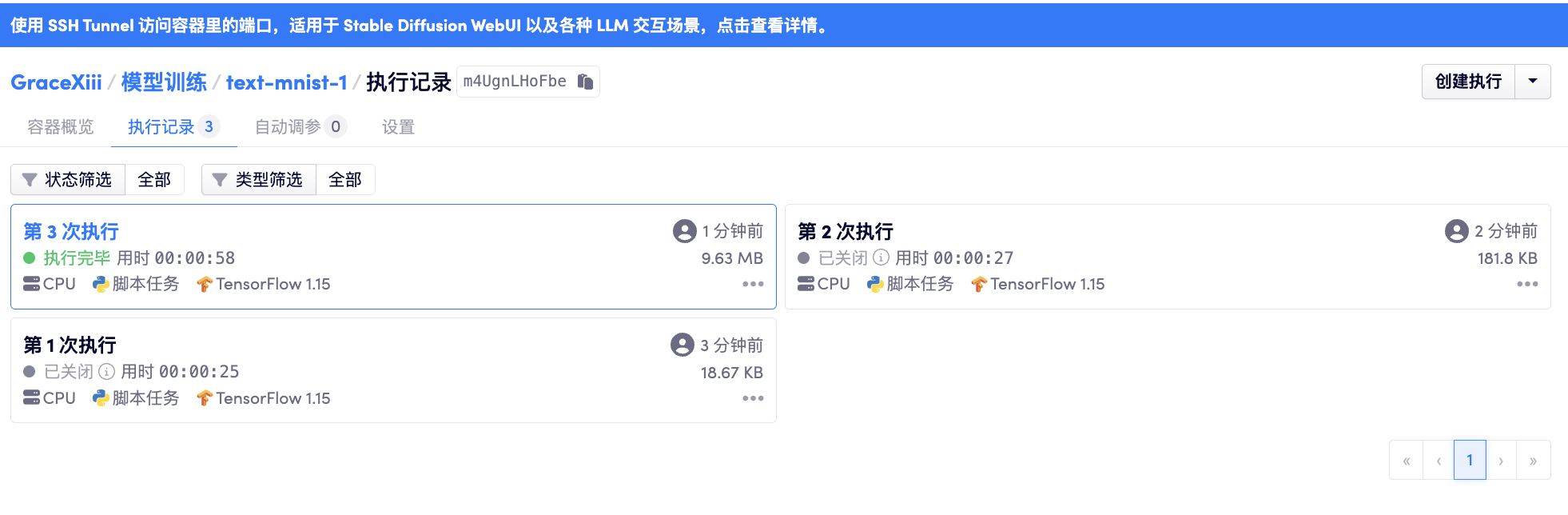
容器目前支持两种方式:「Python 脚本执行」和「Jupyter 工作空间」。两者默认的工作目录都是系统中的 /output 目录(同时会在 /openbayes/home 设置软链接,即 /openbayes/home 与 /output 为同一个目录)。
容器可以创建多个「执行」,每个「执行」都是独立的容器,可以有独立的算力配置、镜像。而每次「执行」在被关闭后其工作目录 /openbayes/home 下的内容将被保存下来,可以通过页面的「工作目录」选项卡查看。
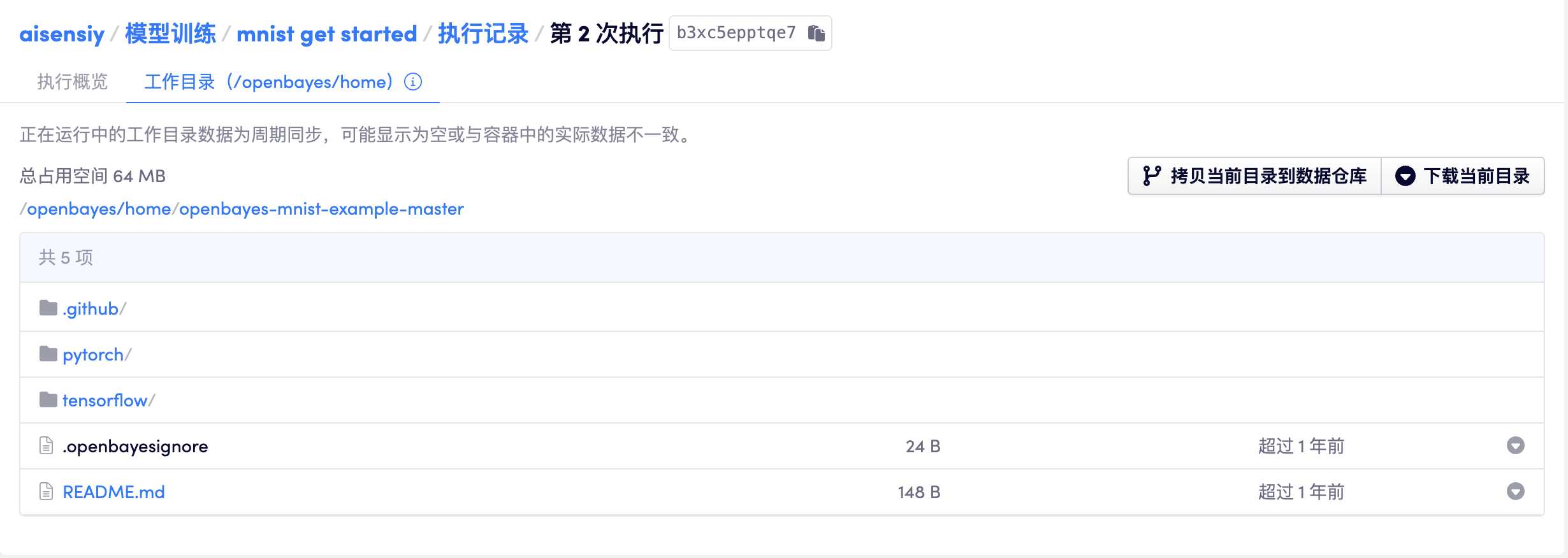
容器执行时其工作目录为 /openbayes/home,所以对其他数据仓库的引用 /openbayes/input/input0-4 需要用绝对路径,而上传的代码则可以用相对目录执行。
举个例子,在创建「Python 脚本执行」时上传了一个名为 train.py 的文件,文件中需要读取 /openbayes/input/input0 目录下的数据,那么在执行时需要用绝对路径 /openbayes/input/input0/<file content> 来引用。而如果需要直接执行该文件则可以直接使用相对路径 python train.py 而不必使用 python /openbayes/home/train.py。
数据绑定
见 算力容器数据绑定。
环境变量
创建容器时可以配置一组环境变量来控制容器的行为,例如传入第三方服务的 Token 等。环境变量分为明文与 Secret 两种类型,Secret 用于密钥等敏感信息、会全程脱敏显示。见 环境变量与 Secret 变量。
Jupyter 工作空间
Jupyter 工作空间是我们基于 JupyterLab 开发的交互式运行环境,首先支持的编程语言是 Python 目前已经成为了大量数据科学家的默认工作环境。通过 Jupyter 工作空间访问算力容器就可以像在其他环境一样使用算力资源了。
Jupyter 工作空间支持两种环境 Notebook 以及 Lab 这里我们默认支持了 Lab。如果你还不知道如何使用 Jupyter 工作空间可以参见其 文档 或相关的中文翻译资料。这里不我们不会穷尽使用 Jupyter 工作空间的一些内容,而是强调几个 OpenBayes 下 Jupyter 工作空间的几个关键特性。
更多信息见 Jupyter 工作空间。
继续执行
通常来说,同一个「容器」下的多次执行在业务上会存在着很大的共性。为了方便用户可以在执行历史的基础上创建新的「执行」,目前 OpenBayes 提供了「继续执行」的选项。

OpenBayes 会为我们做如下事情:
- 绑定上一次「执行」已经绑定的数据仓库到相同的位置
- 如果上一次「执行」是一个「Python 脚本任务」,那么同样绑定相同的代码
- 绑定上一次「执行」的「工作目录」到
/openbayes/home目录
在 OpenBayes 中可以将一个算力容器的「工作目录」绑定到一个新的容器上,实现 "管道" 的效果。这里我们就是将之前的一个 "模型训练" 的「工作目录」作为了一个 "模型推断" 任务的输入。然而这种使用方式是将上一次执行的「工作目录」全部拷贝到新的容器里,这会导致所使用的存储翻倍。因此如果不需要对上一次执行的「工作目录」进行写操作,建议将其绑定到「input0-4」目录中,这将把数据以只读的方式链接到新的容器中,不会产生额外的数据用量。
除了在执行页面上使用「继续执行」外,还可以在「执行记录」页面操作。

在选择继续执行后修改代码的场景
「继续执行」意在方便用户在代码不变的基础上继续上一次的训练,如果在「继续执行」场景下更新了代码需要特别注意。
在点击「继续执行」后如果在这里尝试上传新的代码可能会与当前绑定的「上一次执行的工作目录」中的代码冲突。例如在上一次执行中,我们已经上传了一个名为 main.py 的文件,这个文件已经被保存到了上一次执行的「工作目录」里面了。如果再次上传了一个修改了的同样名为 main.py 的文件,那么 OpenBayes 会忽略这次修改,保留已有的文件。
因此,如果当您使用了「继续执行」并且发现出现了执行代码与您的预期不一致的情况,可能是因为上传的代码内容被上一次容器绑定的工作目录覆盖了。如果不想出现这种情况,可以修改默认绑定的「上一次执行的工作目录」的绑定目录。
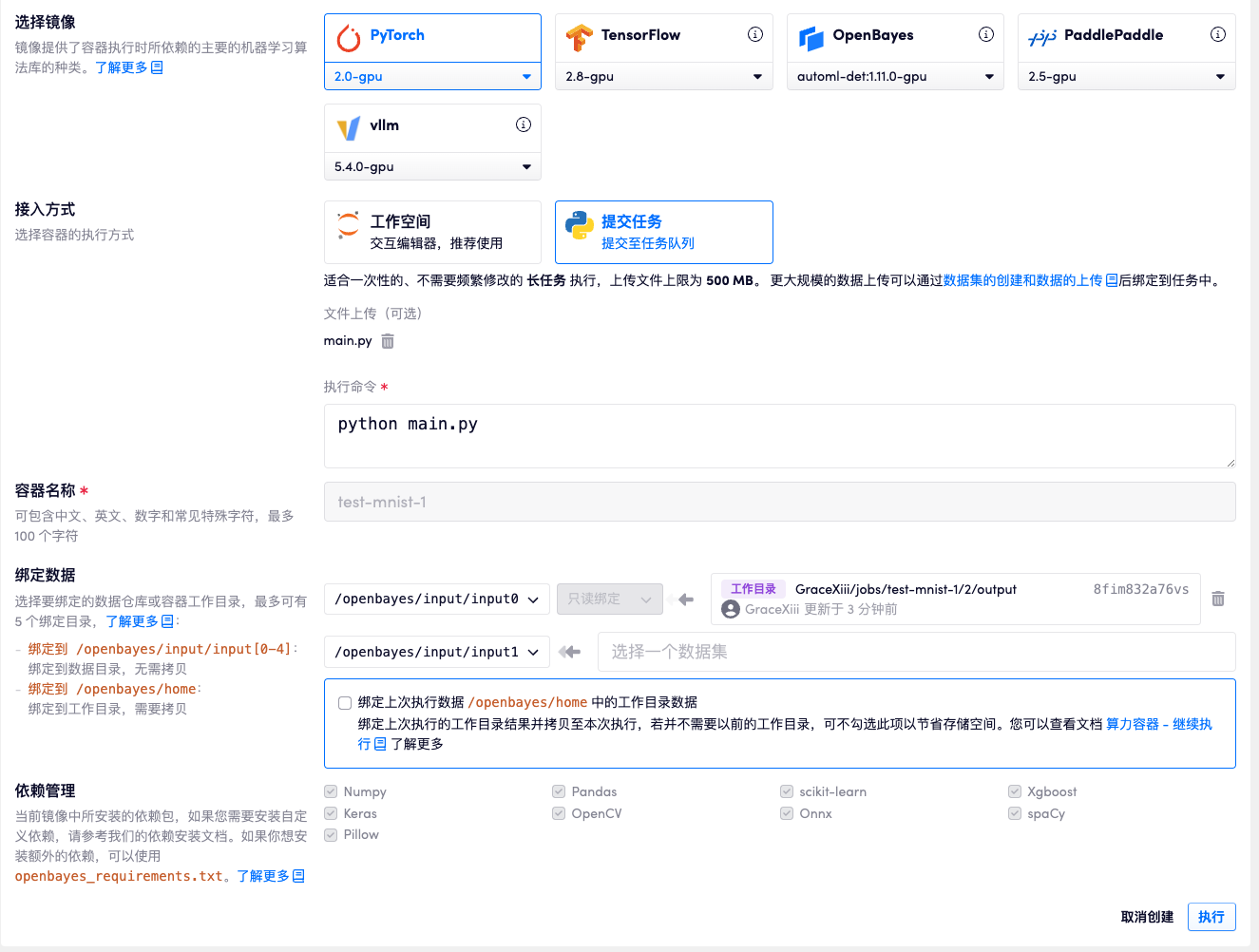
如何加速容器的启动
在容器的工作目录(/openbayes/home 或者说是 /output 两者是等价的)下保存大量的文件会影响容器的启动速度,尤其是大量的小文件的拷贝会非常的耗时。在容器启动进入数据拷贝的流程时,执行的状态会变更为「同步数据」,并显示相应的同步速度。
可以将数据或者模型创建单独的「数据仓库」并以数据绑定的方式绑定到 /intput0-4 以避免拷贝的过程。在 算力容器的工作目录 - 将工作目录创建为数据仓库版本 可以看到如何从容器的「工作目录」创建新的数据集版本。
设定通知
目前 OpenBayes 提供了两种发送通知的渠道:邮件通知以及短信通知。邮件通知被默认勾选且无法关闭,用户可以依据自己的喜好去设置短信通知。
Task 与 Jupyter 工作空间两种模式结合使用
Jupyter 工作空间模式适合即时的文件执行和修改,但是其对计算资源的使用效率不高,在用户编辑和调试的过程中其资源经常是浪费的;Python 脚本上传方式在容器开始运行后会立即执行 Python 代码,对计算资源的利用效率高,但是其修改起来非常麻烦,每次更新代码都需要重新上传。
因此建议可以在低算力模式下(CPU 算力)首先创建 Jupyter 工作空间,在其中保证代码可以正常执行后关闭资源并将其 "工作目录" 下载。然后再创建一个 Python 脚本执行模式的 GPU 算力容器上传下载的代码,执行脚本。
目前 Jupyter 工作空间已经内置了 openbayes 命令行工具 可以非常方便的在 Jupyter 环境通过命令行工具创建 task。
将 .ipynb 文件转换为 .py 文件
选择「File」-「Export Notebook As...」-「Export Notebook to Executable Script」就可以将当前的 ipynb 文件以 py 格式下载到本地。再将其拖动到 Jupyter 工作空间左侧的文件目录中即可将该文件再次上传到容器中:
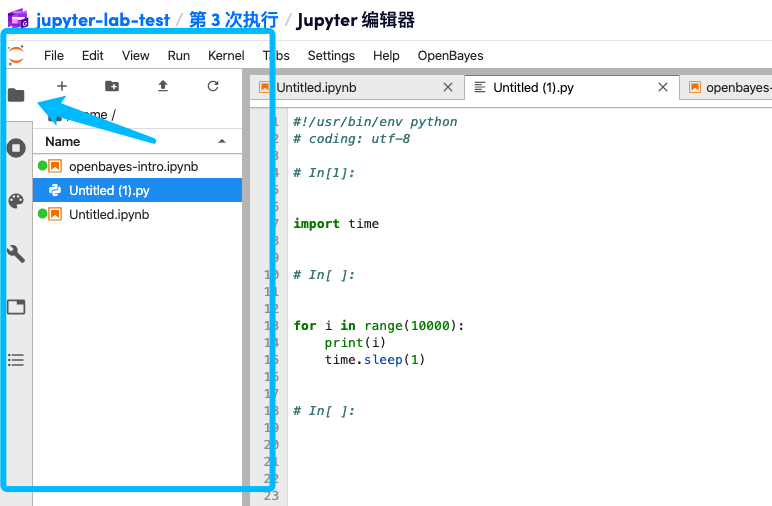
可以看到 ipynb 的代码片段都被串联起来保存在 .py 文件中了。
通过 Jupyter 工作空间内置的命令行工具创建 task
见 创建 Python 脚本 章节。
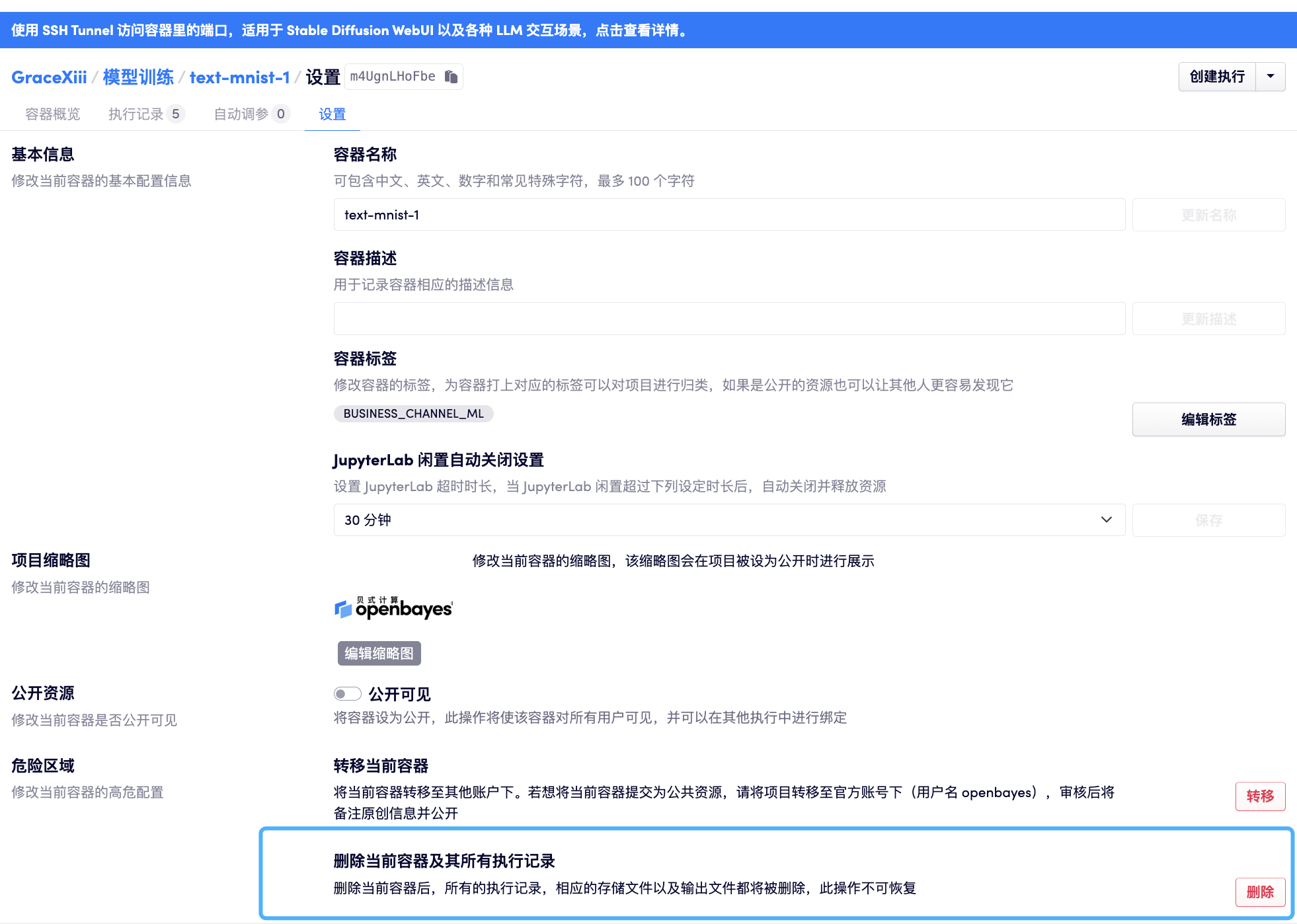
公开容器
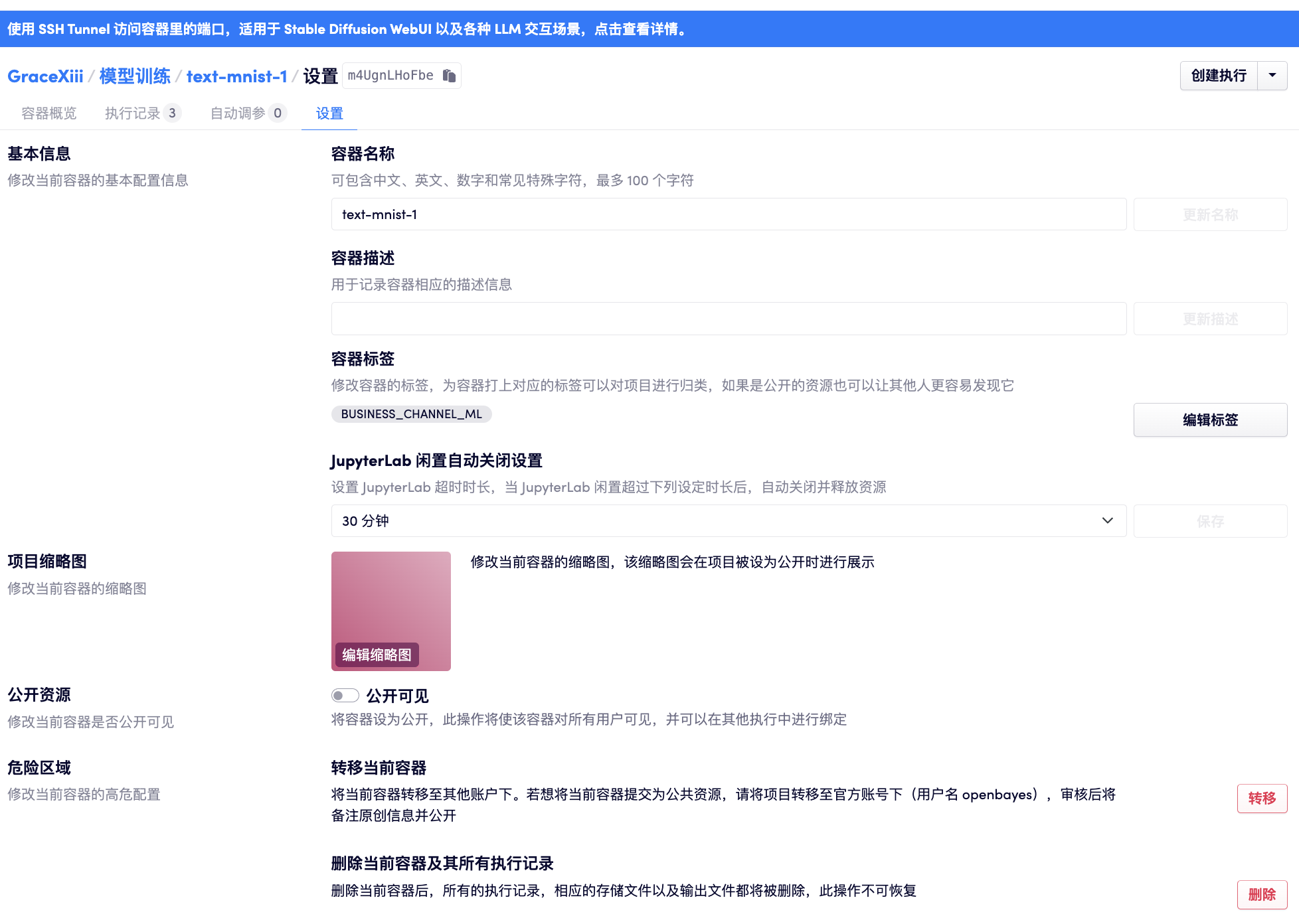
容器创建时默认为「私有容器」,在容器的「设置」界面允许将容器设置为公开容器,处于安全的考虑,公开容器只允许所有注册用户看到已经关闭了的容器执行。
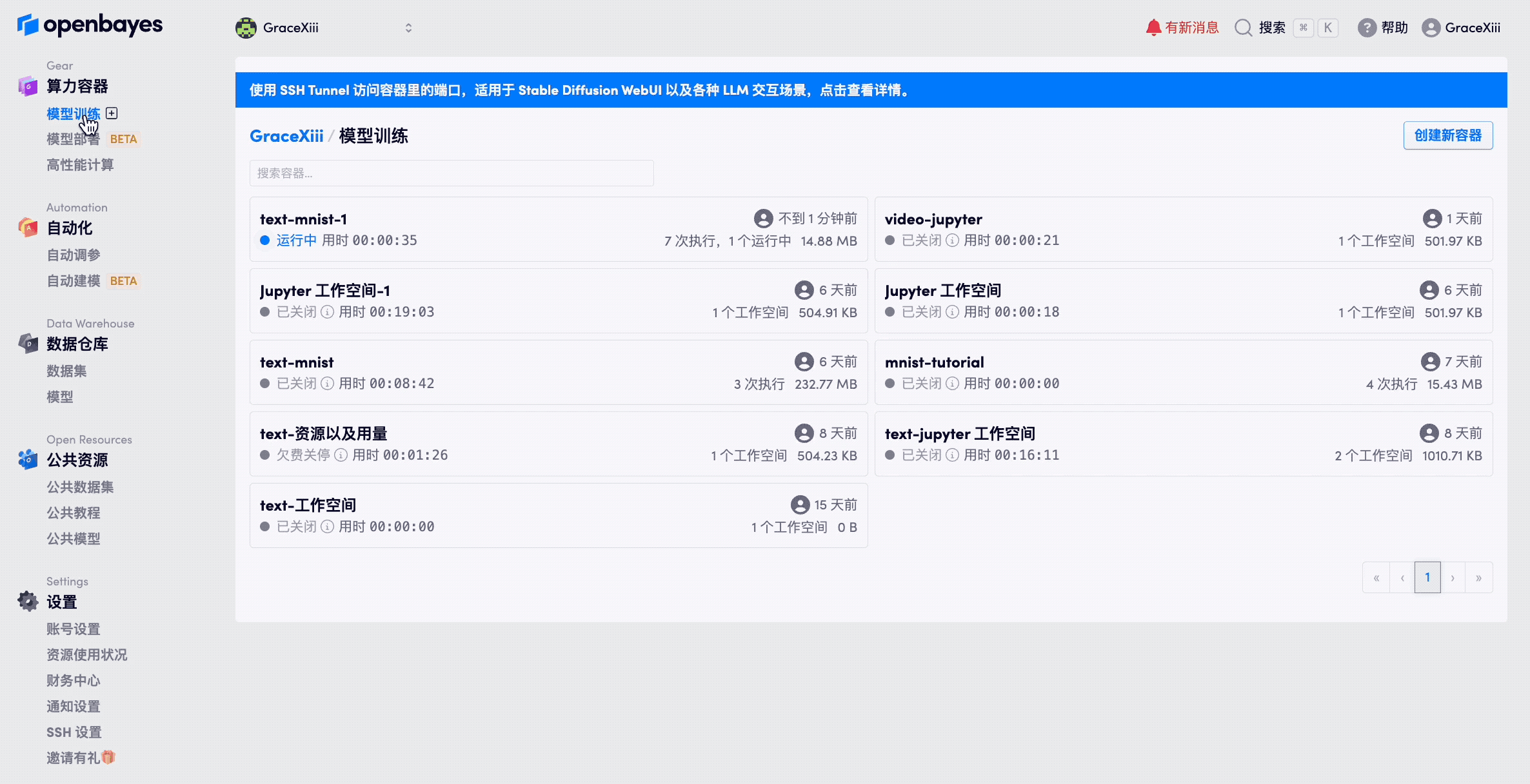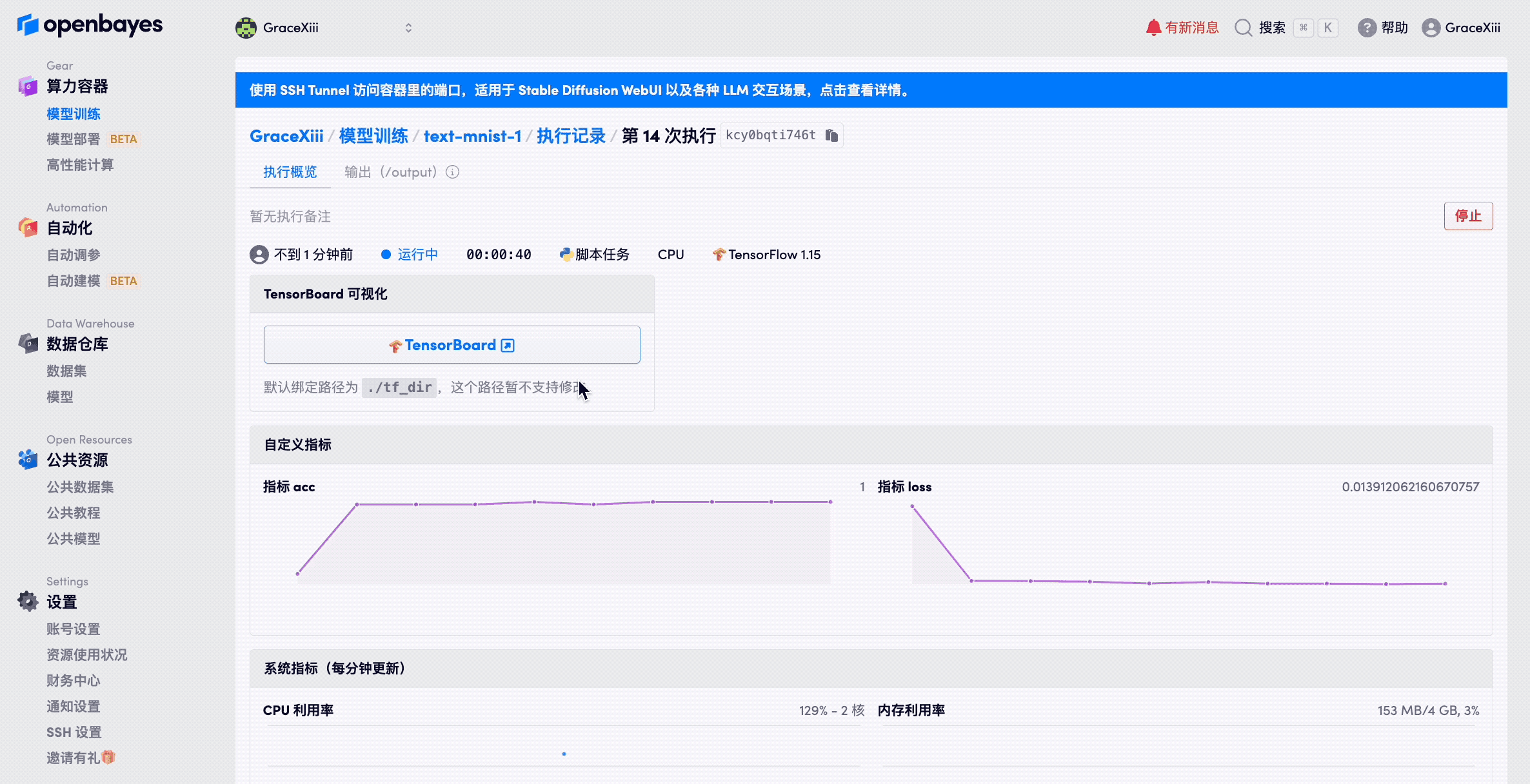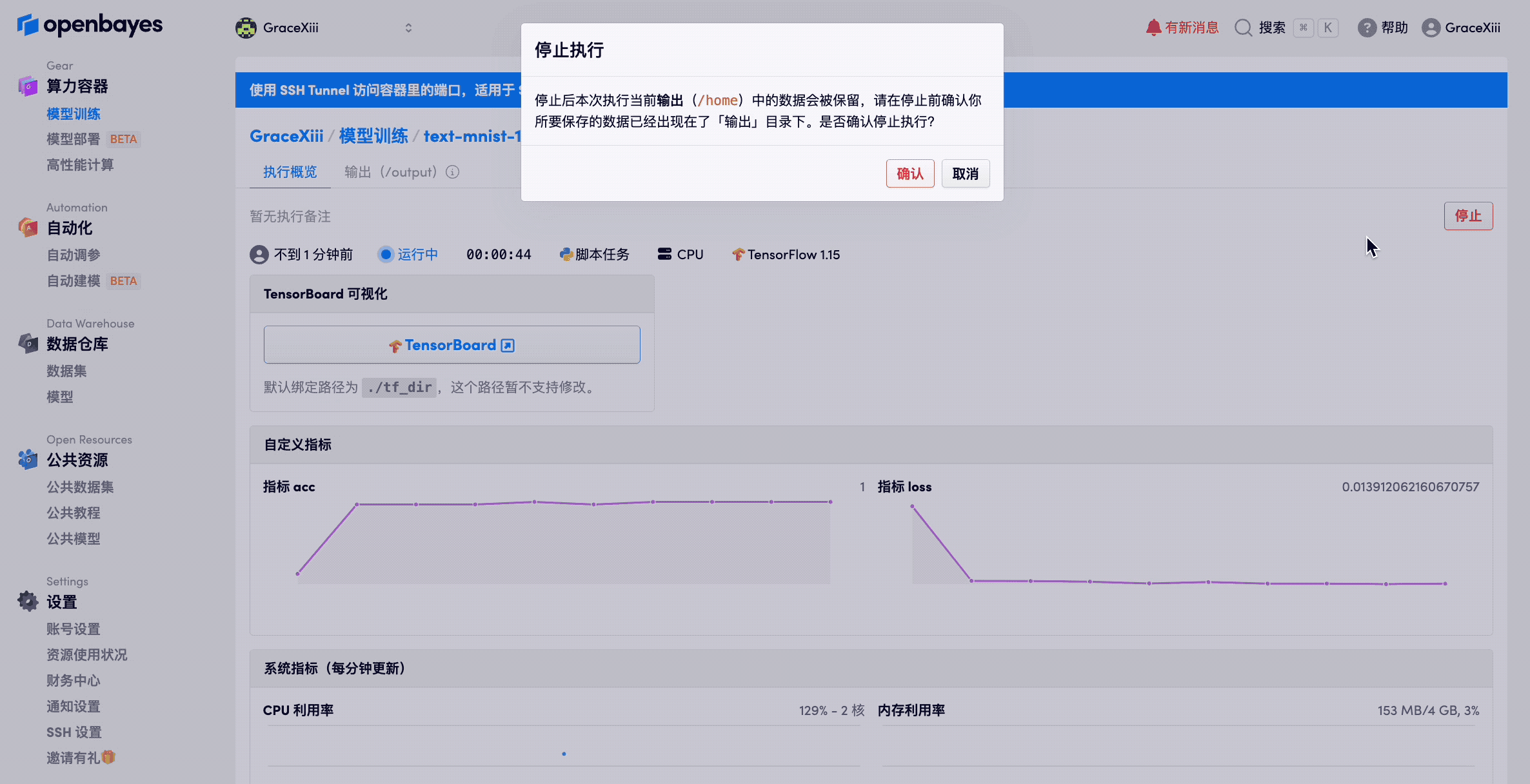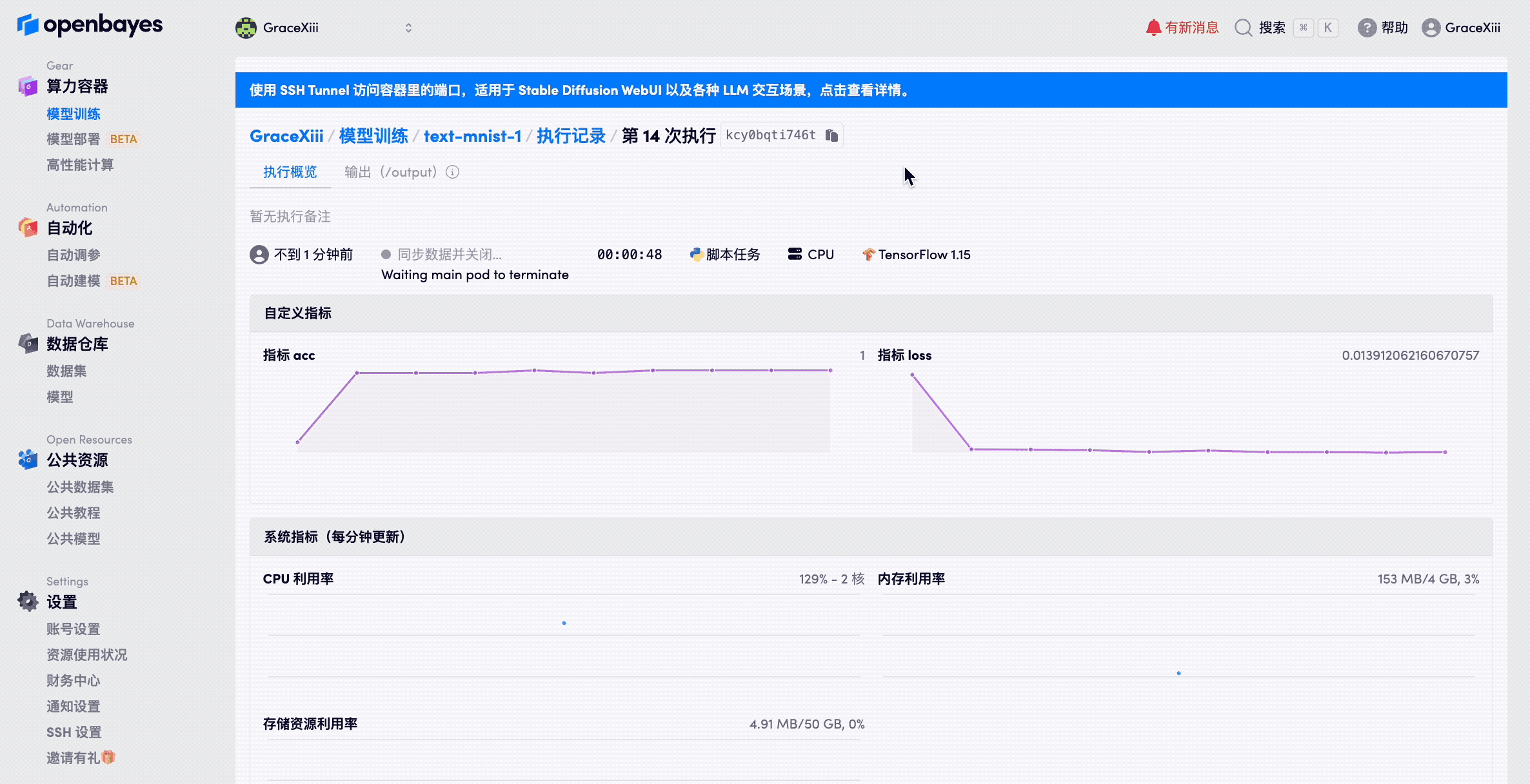
容器的终止
容器在执行的任何过程都可以被终止,但是请注意,容器终止可能会导致部分数据结果没有同步成功,请在容器的「工作目录」标签页确认其当前数据的完整性后再终止容器。
容器的删除
容器在执行完毕之后会自动释放所占有的算力资源,然而通常来说,容器执行完毕后都会有一些文件保存下来以备他用。工作目录会占用用户的存储资源。如果认为整个「容器」的数据都不再需要了,可以在「容器」的「设置」选项卡中删除整个容器,容器删除后将会释放整个容器所占有的用户存储资源。
这项操作非常危险,容器删除后的数据将不可恢复!